-
JUC并发编程系列详解篇十三(悲观锁VS乐观锁)
java的锁的分类
在java并发编程中,锁有很多种类,如下图所示:
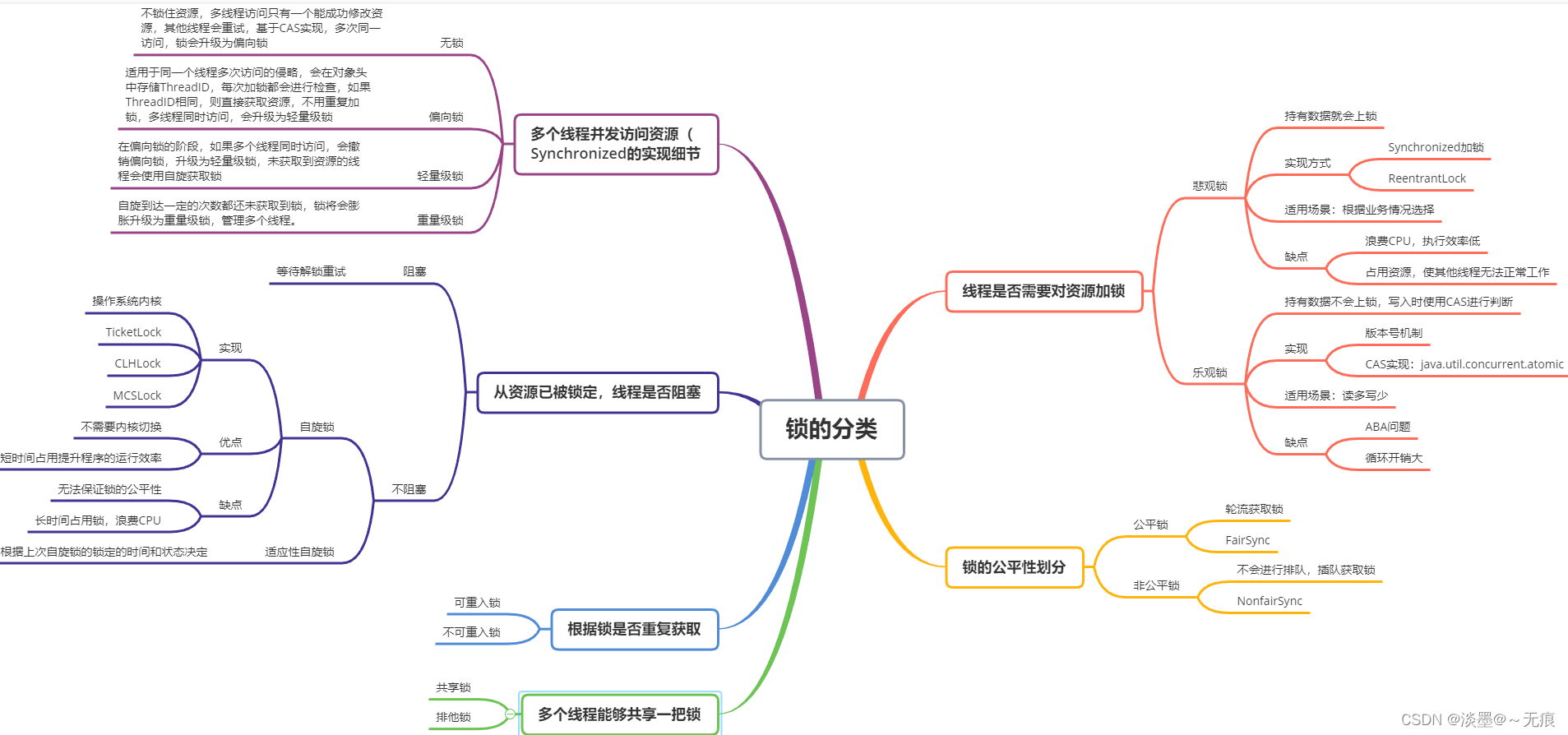
java中锁的分类大致可以划分以下几种:- 从线程是否需要对资源加锁可以分为
悲观锁和乐观锁 - 从资源已被锁定,线程是否阻塞可以分为
自旋锁和适应性自旋锁 - 从多个线程并发访问资源,也就是 Synchronized 可以分为
无锁、偏向锁、轻量级锁和重量级锁 - 从锁的公平性进行区分,可以分为
公平锁和非公平锁 - 从根据锁是否重复获取可以分为
可重入锁和不可重入锁 - 从那个多个线程能否获取同一把锁分为
共享锁和排他锁
悲观锁VS乐观锁
Java 按照是否对资源加锁分为乐观锁和悲观锁,乐观锁和悲观锁并不是一种真实存在的锁,而是一种设计思想,乐观锁和悲观锁对于理解 Java 多线程和数据库来说至关重要。
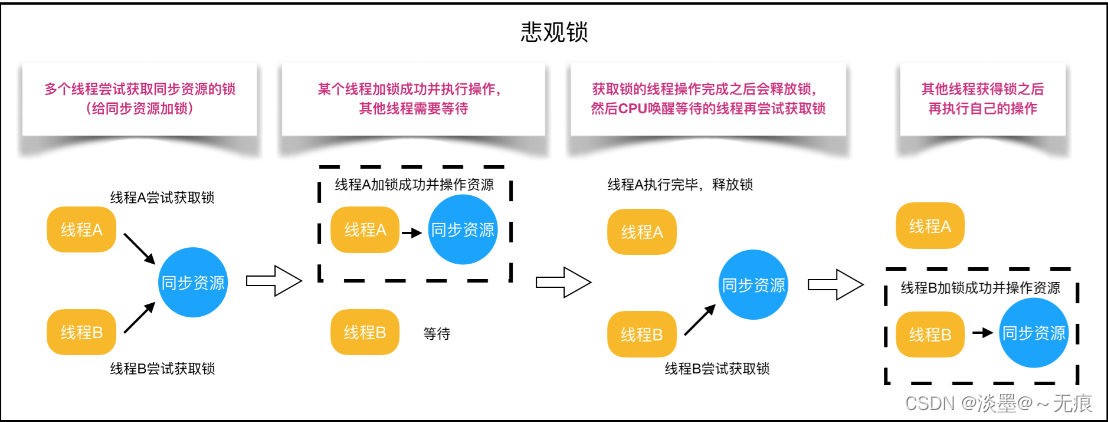
悲观锁
悲观锁是一种悲观思想,它总认为最坏的情况可能会出现,它认为数据很可能会被其他人所修改.所以悲观锁在
持有数据的时候总会把资源或者数据锁住,这样其他线程想要请求这个资源的时候就会阻塞,直到等到悲观锁把资源释放为止。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。 悲观锁的实现往往依靠数据库本身的锁功能实现。
Java 中的 Synchronized 和 ReentrantLock 等独占锁(排他锁)也是一种悲观锁思想的实现,因为 Synchronzied 和 ReetrantLock 不管是否持有资源,它都会尝试去加锁,生怕自己心爱的宝贝被别人拿走。
乐观锁
乐观锁的思想与悲观锁的思想相反,它总认为资源和数据不会被别人所修改,所以读取不会上锁,但是乐观锁在进行写入操作的时候会判断当前数据是否被修改过。乐观锁的实现方案一般来说有两种:版本号机制 和 CAS实现 。乐观锁多适用于多读的应用类型,这样可以提高吞吐量。
在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS 实现的。

两种锁的使用场景
根据从上面的概念描述我们可以发现:
- 悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
- 乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
代码实例:
// ------------------------- 悲观锁的调用方式 ------------------------- // synchronized public synchronized void testMethod() { // 操作同步资源 } // ReentrantLock private ReentrantLock lock = new ReentrantLock(); // 需要保证多个线程使用的是同一个锁 public void modifyPublicResources() { lock.lock(); // 操作同步资源 lock.unlock(); } // ------------------------- 乐观锁的调用方式 ------------------------- private AtomicInteger atomicInteger = new AtomicInteger(); // 需要保证多个线程使用的是同一个AtomicInteger atomicInteger.incrementAndGet(); //执行自增1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
通过调用方式示例,可以发现悲观锁基本都是在显式的锁定之后再操作同步资源,而乐观锁则直接去操作同步资源。
悲观锁调用
上面介绍了两种锁的基本用途,并提到了两种锁的适用场景,一般来说,悲观锁不仅会对写操作加锁还会对读操作加锁,一个典型的悲观锁调用:
select * from student where name="cxuan" for update- 1
这条 sql 语句从 Student 表中选取 name = “cxuan” 的记录并对其加锁,那么其他写操作在这个事务提交之前都不会对这条数据进行操作,起到了独占和排他的作用。
悲观锁因为对读写都加锁,所以它的性能比较低,对于现在互联网提倡的三高(高性能、高可用、高并发)来说,悲观锁的实现用的越来越少了。
但是一般多读的情况下还是需要使用悲观锁的,因为虽然加锁的性能比较低,但是也阻止了像乐观锁一样,遇到写不一致的情况下一直重试的时间。
相对而言,乐观锁用于读多写少的情况,即很少发生冲突的场景,这样可以省去锁的开销,增加系统的吞吐量。
乐观锁的实现方式
乐观锁的适用场景有很多,典型的比如说成本系统,柜员要对一笔金额做修改,为了保证数据的准确性和实效性,使用悲观锁锁住某个数据后,再遇到其他需要修改数据的操作,那么此操作就无法完成金额的修改,对产品来说是灾难性的一刻,使用乐观锁的版本号机制能够解决这个问题。乐观锁一般有两种实现方式:采用
版本号机制和CAS(Compare-and-Swap,即比较并替换)算法实现。版本号机制
版本号机制是在数据表中加上一个
version字段来实现的,表示数据被修改的次数当执行写操作并且写入成功后,version = version + 1,当线程A要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
我们以上面的金融系统为例,来简述一下这个过程。
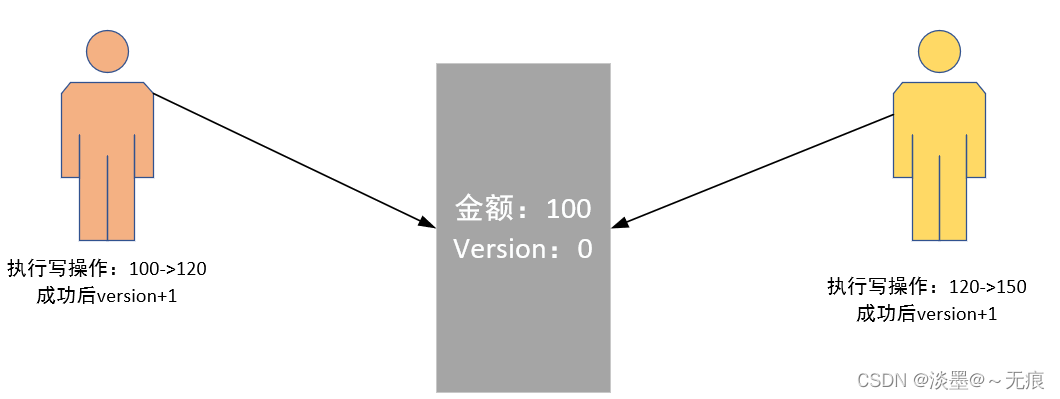
成本系统中有一个数据表,表中有两个字段分别是金额和version,金额的属性是能够实时变化,而 version 表示的是金额每次发生变化的版本,一般的策略是,当金额发生改变时,version 采用递增的策略每次都在上一个版本号的基础上 + 1。在了解了基本情况和基本信息之后,我们来看一下这个过程:公司收到回款后,需要把这笔钱放在金库中,假如金库中存有100 元钱。
- 下面开启事务一:当男柜员执行回款写入操作前,他会先查看(读)一下金库中还有多少钱,此时读到金库中有 100 元,可以执行写操作,并把数据库中的钱更新为 120 元,提交事务,金库中的钱由 100 -> 120,version的版本号由 0 -> 1。
- 开启事务二:女柜员收到给员工发工资的请求后,需要先执行读请求,查看金库中的钱还有多少,此时的版本号是多少,然后从金库中取出员工的工资进行发放,提交事务,成功后版本 + 1,此时版本由 1 -> 2。
上面两种情况是最乐观的情况,上面的两个事务都是顺序执行的,也就是事务一和事务二互不干扰,那么事务要并行执行会如何呢?
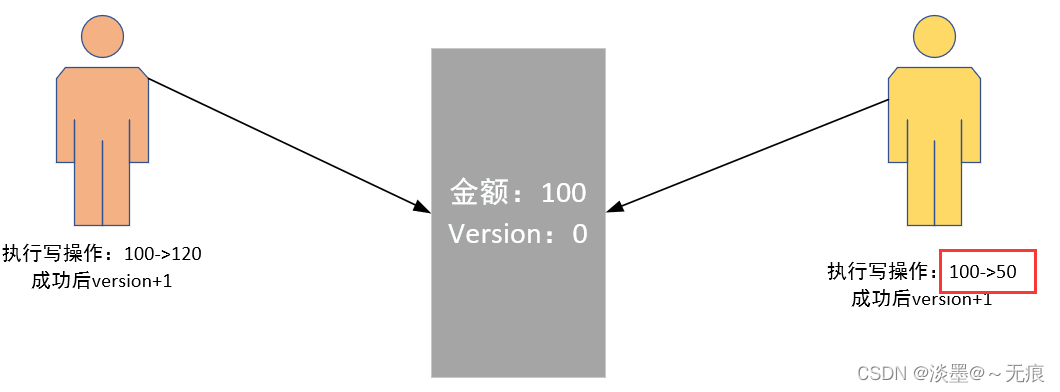
事务一开启,男柜员先执行读操作,取出金额和版本号,执行写操作:begin update 表 set 金额 = 120,version = version + 1 where 金额 = 100 and version = 0- 1
- 2
此时金额改为 120,版本号为1,事务还没有提交。
事务二开启,女柜员先执行读操作,取出金额和版本号,执行写操作:
begin update 表 set 金额 = 50,version = version + 1 where 金额 = 100 and version = 0- 1
- 2
此时金额改为 50,版本号变为 1,事务未提交
现在提交事务一,金额改为 120,版本变为1,提交事务。理想情况下应该变为 金额 = 50,版本号 = 2,但是实际上事务二 的更新是建立在金额为 100 和 版本号为 0 的基础上的,所以事务二不会提交成功,应该重新读取金额和版本号,再次进行写操作。
这样,就避免了女柜员 用基于 version = 0 的旧数据修改的结果覆盖男操作员操作结果的可能。
CAS算法
首先来看一下经典的并发1000次的递增和递减的实例:
public class Counter { int count = 0; public int getCount() { return count; } public void setCount(int count) { this.count = count; } public void add(){ count += 1; } public void dec(){ count -= 1; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
public class Consumer extends Thread{ Counter counter; public Consumer(Counter counter){ this.counter = counter; } @Override public void run() { for(int j = 0;j < Test.LOOP;j++){ counter.dec(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
public class Producer extends Thread{ Counter counter; public Producer(Counter counter){ this.counter = counter; } @Override public void run() { for(int i = 0;i < Test.LOOP;++i){ counter.add(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
public class Test { final static int LOOP = 1000; public static void main(String[] args) throws InterruptedException { Counter counter = new Counter(); Producer producer = new Producer(counter); Consumer consumer = new Consumer(counter); producer.start(); consumer.start(); producer.join(); consumer.join(); System.out.println(counter.getCount()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
多次测试的结果都不为 0,也就是说出现了并发后数据不一致的问题,原因是 count -= 1 和 count += 1 都是非原子性操作,它们的执行步骤分为三步:
- 从内存中读取 count 的值,把它放入寄存器中
- 执行 + 1 或者 - 1 操作
- 执行完成的结果再复制到内存中
如果要把证它们的原子性,必须进行加锁,使用 Synchronzied 或者 ReentrantLock。
CAS 即 compare and swap(比较与交换),是一种有名的无锁算法。即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)
CAS 中涉及三个要素:
- 需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新值 B
当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。下面以 java.util.concurrent 中的AtomicInteger 为例,看一下在不用锁的情况下是如何保证线程安全的。
public class AtomicCounter { private AtomicInteger integer = new AtomicInteger(); public AtomicInteger getInteger() { return integer; } public void setInteger(AtomicInteger integer) { this.integer = integer; } public void increment(){ integer.incrementAndGet(); } public void decrement(){ integer.decrementAndGet(); } } public class AtomicProducer extends Thread{ private AtomicCounter atomicCounter; public AtomicProducer(AtomicCounter atomicCounter){ this.atomicCounter = atomicCounter; } @Override public void run() { for(int j = 0; j < AtomicTest.LOOP; j++) { System.out.println("producer : " + atomicCounter.getInteger()); atomicCounter.increment(); } } } public class AtomicConsumer extends Thread{ private AtomicCounter atomicCounter; public AtomicConsumer(AtomicCounter atomicCounter){ this.atomicCounter = atomicCounter; } @Override public void run() { for(int j = 0; j < AtomicTest.LOOP; j++) { System.out.println("consumer : " + atomicCounter.getInteger()); atomicCounter.decrement(); } } } public class AtomicTest { final static int LOOP = 10000; public static void main(String[] args) throws InterruptedException { AtomicCounter counter = new AtomicCounter(); AtomicProducer producer = new AtomicProducer(counter); AtomicConsumer consumer = new AtomicConsumer(counter); producer.start(); consumer.start(); producer.join(); consumer.join(); System.out.println(counter.getInteger()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
经测试可得,不管循环多少次最后的结果都是0,也就是多线程并行的情况下,使用 AtomicInteger 可以保证线程安全性。incrementAndGet 和 decrementAndGet 都是原子性操作。
乐观锁的缺点
任何事情都是有利也有弊,所以乐观锁也有它的弱点和缺陷:
ABA问题
ABA 问题说的是,如果一个变量第一次读取的值是 A,准备好需要对 A 进行写操作的时候,发现值还是 A,那么这种情况下,能认为 A 的值没有被改变过吗?可以是由 A -> B -> A 的这种情况,但是 AtomicInteger 却不会这么认为,它只相信它看到的,它看到的是什么就是什么。
JDK 1.5 以后的 AtomicStampedReference类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
也可以采用CAS的一个变种DCAS来解决这个问题。DCAS,是对于每一个V增加一个引用的表示修改次数的标记符。对于每个V,如果引用修改了一次,这个计数器就加1。然后在这个变量需要update的时候,就同时检查变量的值和计数器的值。
循环开销大
我们知道乐观锁在进行写操作的时候会判断是否能够写入成功,如果写入不成功将触发等待 -> 重试机制,这种情况是一个自旋锁,简单来说就是适用于短期内获取不到,进行等待重试的锁,它不适用于长期获取不到锁的情况,另外,自旋循环对于性能开销比较大。
CAS与synchronized的使用情景
简单的来说 CAS 适用于写比较少的情况下(多读场景,冲突一般较少),synchronized 适用于写比较多的情况下(多写场景,冲突一般较多)。
- 对于资源竞争较少(线程冲突较轻)的情况,使用 Synchronized 同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗 cpu 资源;而 CAS 基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
- 对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
文章来源
- Java全栈知识体系中的java并发-java中所有的锁
- 微信公众号 - java建设者的文章《看完你就应该能明白的悲观锁和乐观锁》
- 微信公众号 - 石杉的架构笔记的文章《不懂什么是 Java 中的锁?看看这篇你就明白了!》
基于以上三位的文章内容,个人进行归纳总结,仅做日常学习分享,不做其他用途。
- 从线程是否需要对资源加锁可以分为
-
相关阅读:
SFTP 命令帮助
Linux家目录变成了-bash-4.2$
网络安全(黑客)自学
L9ARM体系结构与接口技术--ARM指令集仿真环境搭建(day5)
工厂模式代码实例详解
数据科学手把手:碳中和下的二氧化碳排放分析 ⛵
【计算机网络】文件传输协议FTP和SFTP
初创公司即融资上亿,这个“人造超级大脑”赛道为什么不是噱头?
【仿真建模】AnyLogic入门基础教程 第一课
JAVA:实现Harshad Number哈沙德数算法(附完整源码)
- 原文地址:https://blog.csdn.net/m0_46198325/article/details/126810401
