-
为什么阿里巴巴禁止数据库中做多表join?
△Hollis, 一个对Coding有着独特追求的人△

这是Hollis的第 397 篇原创分享
作者 l Hollis
来源 l Hollis(ID:hollischuang)

阿里出过一个《Java开发手册》,上面有一条规约是禁止超过三张表的join。

而实际操作过程中,我们平时确实在SQL中写JOIN也比较少,两张表JOIN有的时候也有,多张表的JOIN在离线数据分析的时候很多,但是在线系统确实很少。经常有人问我为什么?
其实最主要的原因就是join的效率比较低。
MySQL是使用了嵌套循环(Nested-Loop Join)的方式来实现关联查询的,简单点说就是要通过两层循环,用第一张表做外循环,第二张表做内循环,外循环的每一条记录跟内循环中的记录作比较,符合条件的就输出。
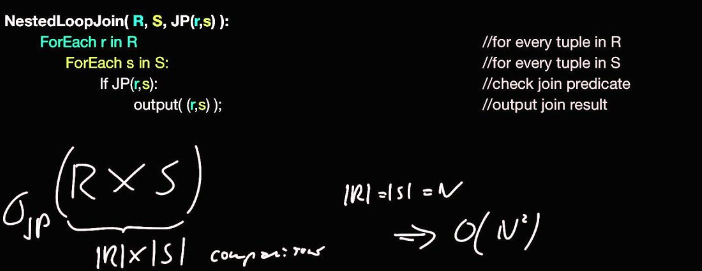
而具体到算法实现上主要有simple nested loop,block nested loop和index nested loop这三种。
而且这三种的效率都没有特别高。
首先,最差的算法就是simple nested loop,他的做法简单粗暴,就是全量扫描连接两张表进行数据的两两对比,所以他的复杂度可以认为是O(n^2)
好一点的算法是index nested loop,当Inner Loop的表用到字段有索引的话,可以用到索引进行查询数据,因为索引是B+树的,复杂度可以近似认为是O(nlogn)
那block nested loop这种算法,其实是引入了一个Buffer,会提前把外循环的一部分结果提前放到多个JOIN BUFFER中,然后内循环的每一行都和多个buffer中的所有数据作比较,从而减少内循环的次数。他的复杂度是O(M*N),这里的M是buffer的个数。
所以,虽然MySQL已经尽可能的在优化了,但是这几种算法复杂度都还是挺高的,这也是为什么不建议在数据库中多表JOIN的原因。随着表越多,表中的数据量越多,JOIN的效率会呈指数级下降。
如果不能通过数据库做关联查询,那么需要查询多表的数据的时候要怎么做呢?
主要有两种做法:
1、在内存中自己做关联,即先从数据库中把数据查出来之后,我们在代码中再进行二次查询,然后再进行关联。
2、数据冗余,那就是把一些重要的数据在表中做冗余,这样就可以避免关联查询了。
其实数据冗余是互联网业务中比较常见的做法,其实本质上是软件开发中一个比较典型的方案,那就是"用空间换时间",通过做一些数据冗余,来提升查询速度。
在互联网业务中,比较典型的就是数据量大,并发高,并且通常查询的频率要远高于写入的频率,所以适当的做一些反范式,通过做一些字段的冗余,可以提升查询性能,降低响应时长,从而提升并发度。
如果你喜欢本文,
请长按二维码,关注 Hollis.

转发至朋友圈,是对我最大的支持。
点个 在看
喜欢是一种感觉
在看是一种支持
↘↘↘
-
相关阅读:
java.lang.Enum类下name()方法起什么作用呢?
SAP UI5 DynamicPage 控件介绍
栈和队列相关的一些问题
Mybatis——一对多关联映射
Azure AD(六)添加自定义域名
38.【C++ 虚函数 纯虚函数 虚基类 (最全详解)】
java8 LocalDate、LocalTime、LocalDateTime
【SwiftUI项目】0011、SwiftUI项目-费用跟踪-记账App项目-第3/3部分 -日期指定选定-新增费用页面
es和kibana单机搭建
ArcMap分别求取矢量要素各区域的面积
- 原文地址:https://blog.csdn.net/hollis_chuang/article/details/126716231