-
mindspore两日集训营202209-MindSpore高效并行训练推荐算法
作业1
题目 对小规模criteo数据做预处理
说明
1、使用推荐独立仓criteo数据集数据处理脚本对小规模数据做预处理,生成可训练的mindrecord格式数据。
2、小规模数据地址:https://xihe.mindspore.cn/datasets/shenfeng/criteo_60w/tree
3、预处理脚本使用说明:https://gitee.com/mindspore/recommender/tree/master/datasets/criteo_1tb
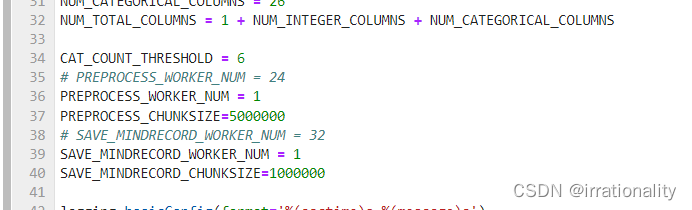
4、由于数据集非常小,可以修改脚本中的处理进程数为1:SAVE_MINDRECORD_WORKER_NUM = 1下载网速还是相当快的。
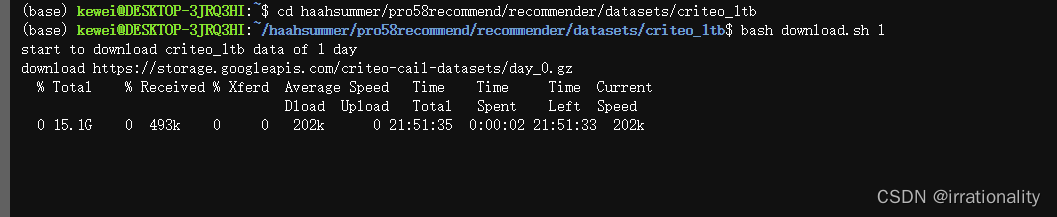
当然,实际上我们需要的只是小规模数据,因此就不用下载这个15G的。下载这个144M
python process_data.py --data_path=./data/ --part_num=1- 1
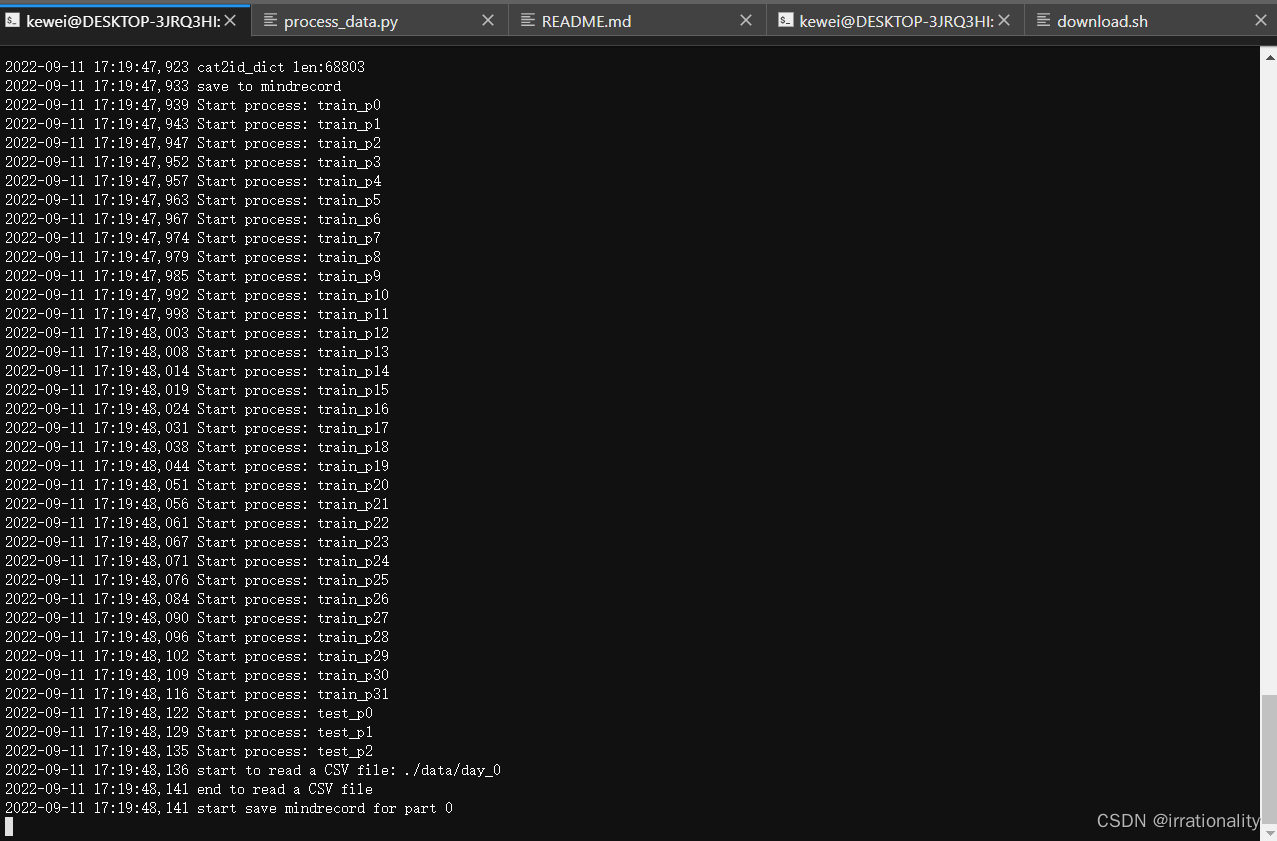
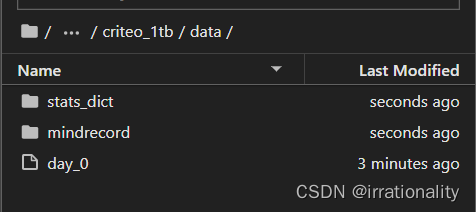
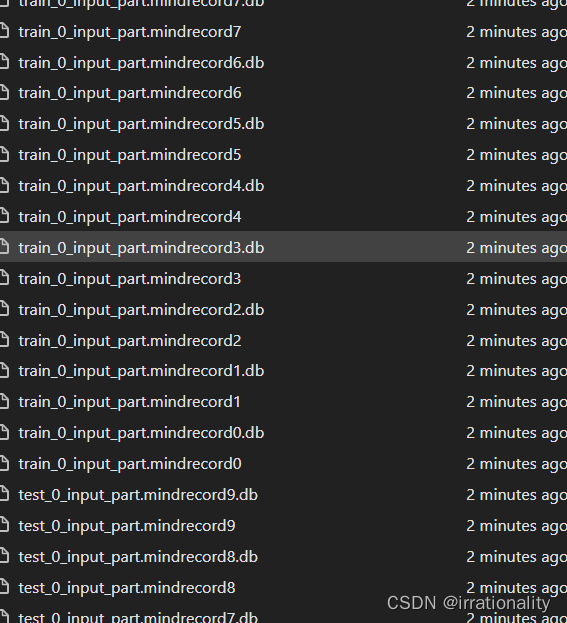
可以看到对应目录下生成了如上文件
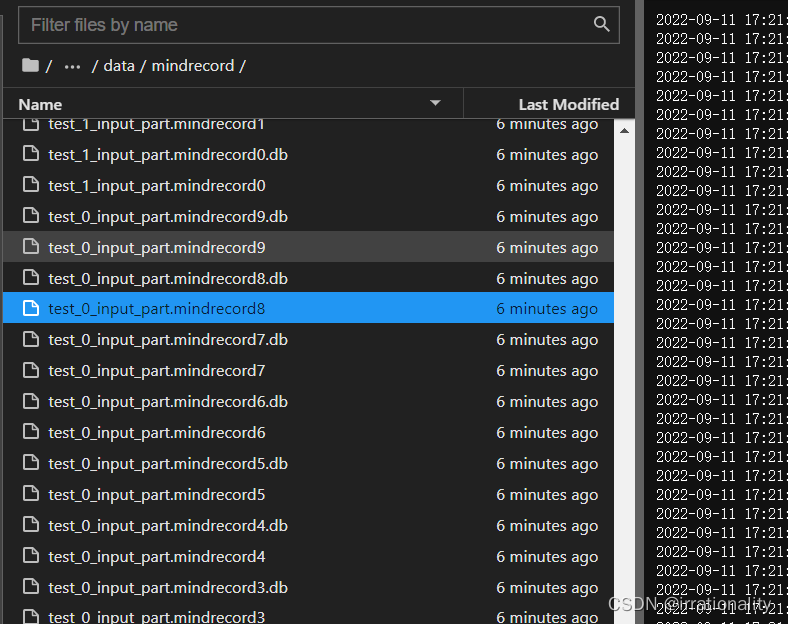
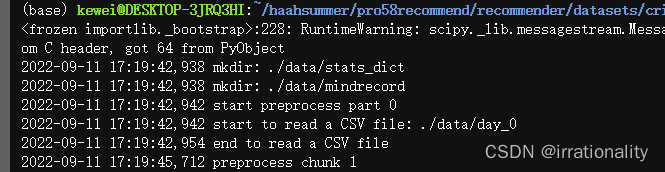
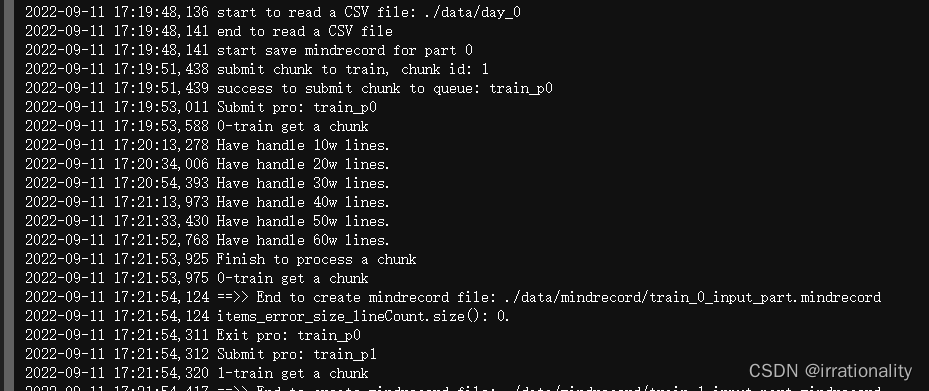

开始时间17:19:42 结束时间17:21:58 共136s
中间有一些读写文件的操作
由于数据集非常小,可以修改脚本中的处理进程数为1:SAVE_MINDRECORD_WORKER_NUM = 1
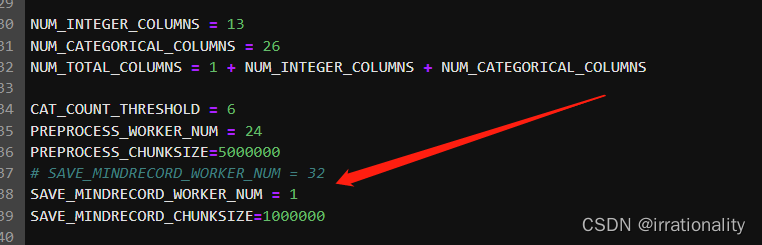
然后再运行一遍
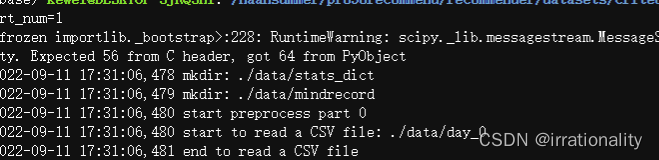
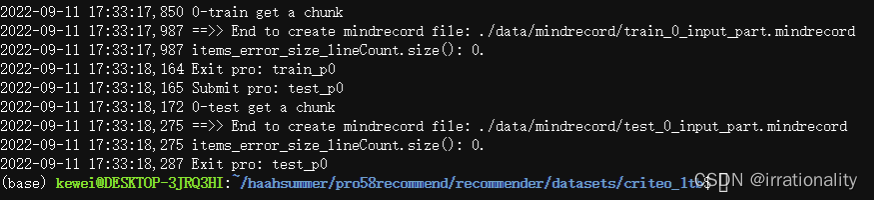
开始时间17:31:06 结束时间17:33:18 共132s
生成的mindrecord文件分为train_0和test_0
作业2
题目 运行wdl算法模型训练
说明
1、运行推荐独立仓的wdl算法模型,使用作业1预处理好的criteo数据,在单机单GPU卡上做训练。
2、训练说明地址:https://gitee.com/mindspore/recommender/tree/master/rec/models/wide_deep
3、使用其中的单卡训练模式,注意调整数据集路径
python train_and_eval.py --data_path=./data/mindrecord --device_target=“GPU”python train_and_eval.py --data_path=/code/datasets/criteo_1tb/data/mindrecord --device_target=“GPU”
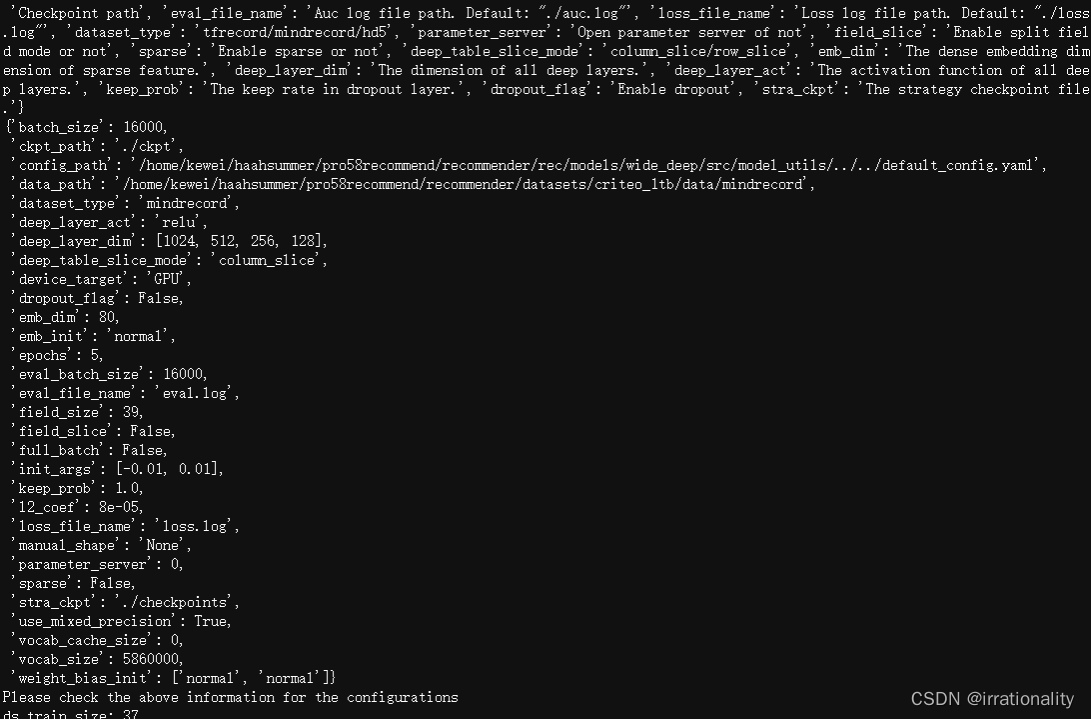
最后报了一个错,gpu的memery不够了。
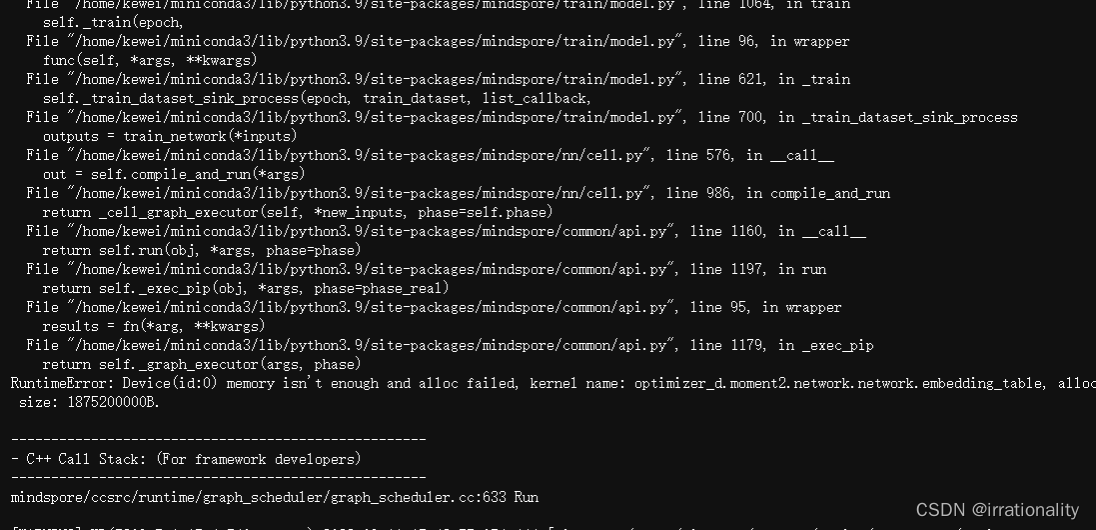
这种情况,我用openi启智社区的搞下

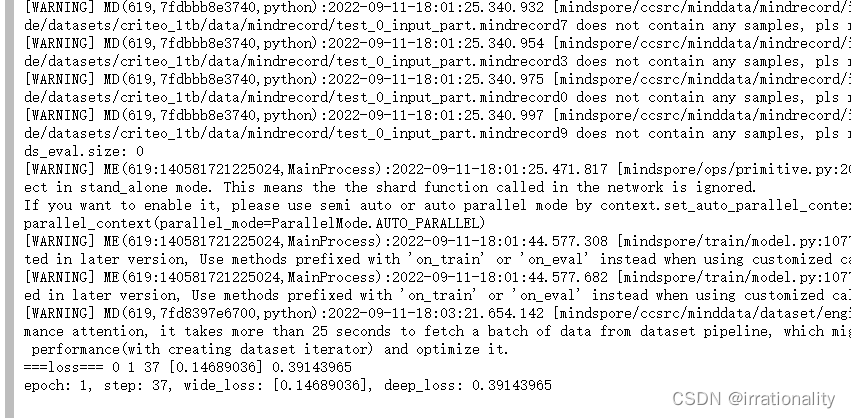
不错,跑起来了。
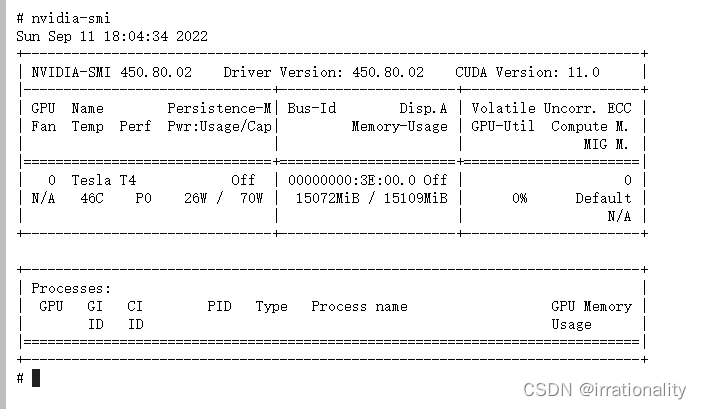
GPU占用确实比较多。
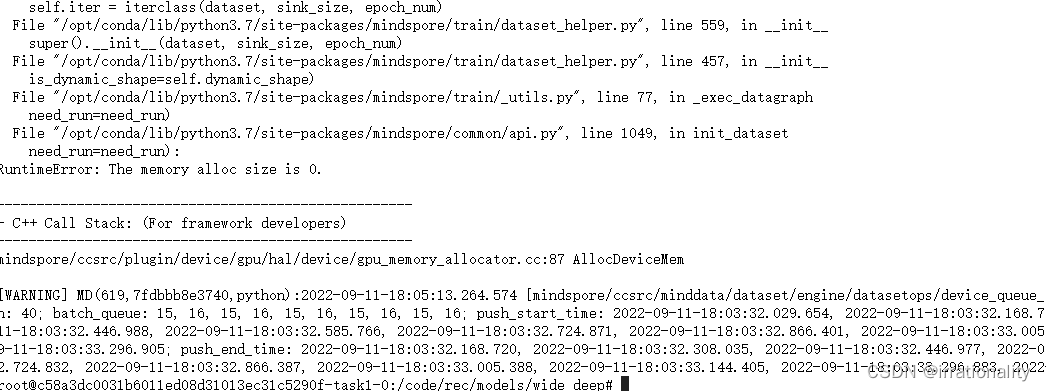
跑了一轮后还是报错了。按照提示,确实有部分mindrecord文件,其内容为空。

老是有空文件,确实很讨厌,我们改为单线程
同时,我们使用sqlitespy对数据集作适当修改,这下就真的跑起来了。

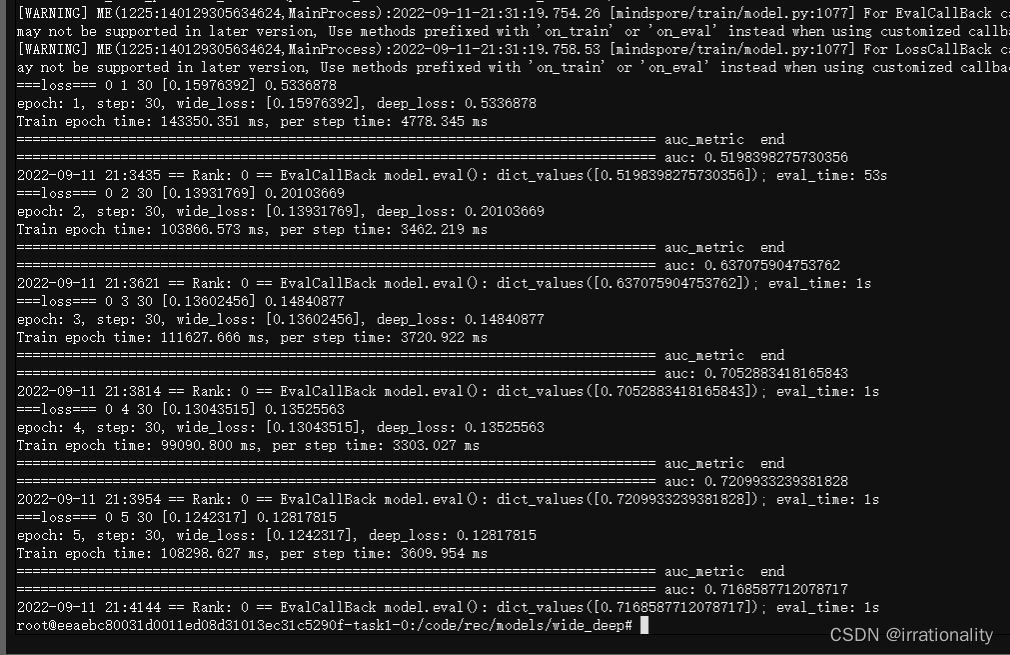
ok,训练完成。
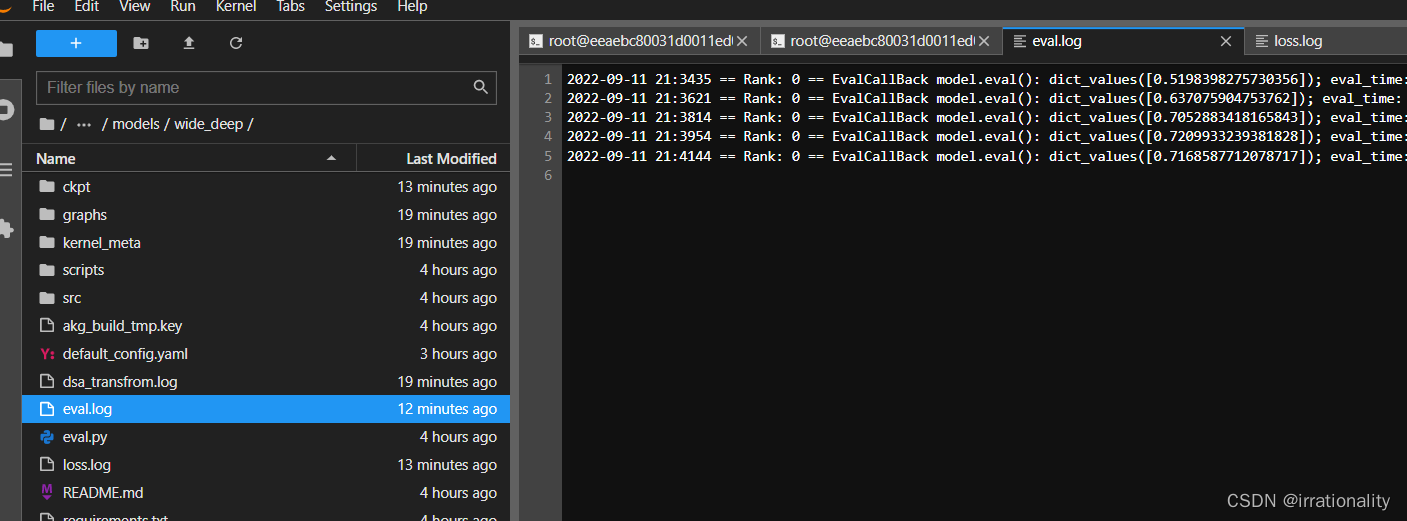
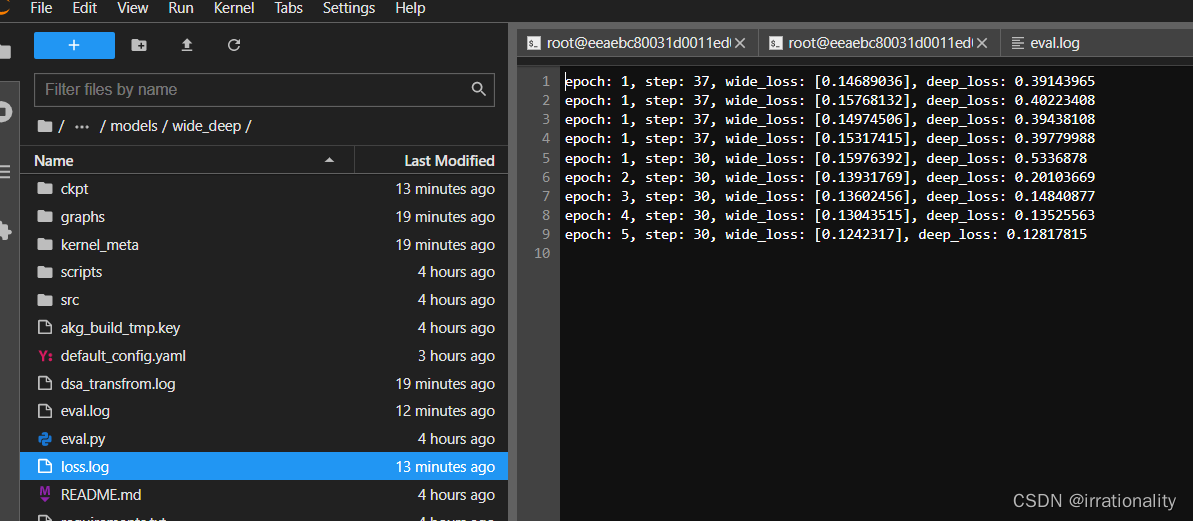
如上是生成的4个log文件,ok了!
-
相关阅读:
UG\NX二次开发 信息窗口的一些操作 NXOpen/ListingWindow
7、脏话检测
vue——组件高级之动态组件、缓存组件、异步组件
docker搭建C语言开发环境
qt pro如何增加自定义值为的字符串的宏
ROL,PIT,YAW
微服务应用与开发知识点练习【Nacos、Ribbon、Sentinel】
Chrome 115之后的版本,安装和使用chromedriver
大模型必备 - 中文最佳向量模型 acge_text_embedding
7.24 - 每日一题 - 408
- 原文地址:https://blog.csdn.net/weixin_54227557/article/details/126806970