-
现代循环神经网络 - LSTM
长短期记忆网络(LSTM)
1 - 门控记忆元
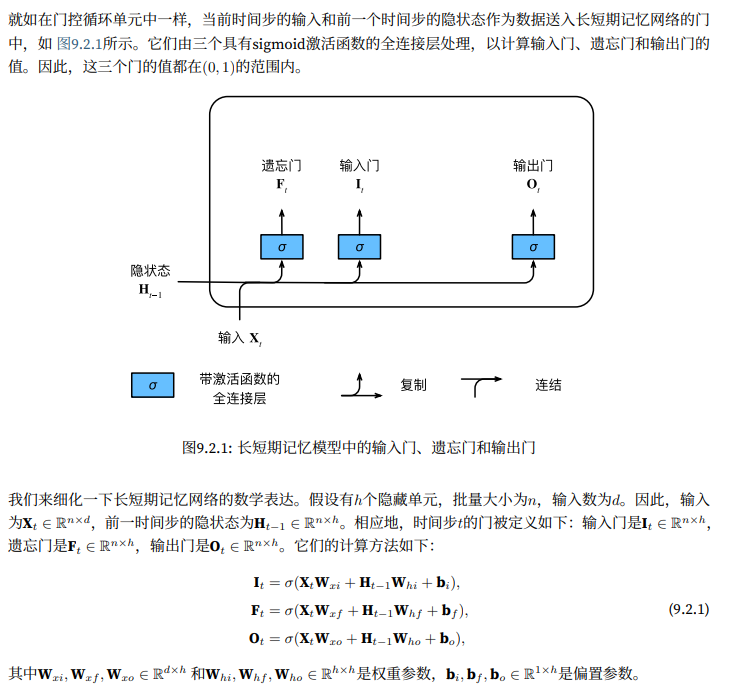
可以说,长短期记忆网络的设计灵感来自于计算机的逻辑门,长短期记忆网络引入了记忆元(memory cell),或简称为单元(cell)。有些文献认为记忆元时隐状态的一种特殊类型,它们与隐状态具有相同的形状,其设计目的时用于记录附加的信息。为了控制记忆元,我们需要许多门。
- 输入门:用来决定何时将数据读入单元
- 输出门:用来从单元中输出条目
- 遗忘门:用来重置单元的内容
这种设计的动机与门控循环单元相同,能够通过专用机制决定上面时候记忆或忽略状态中的输入。让我们来看看这些在实践中是如何运作的
输入门、忘记门和输出门
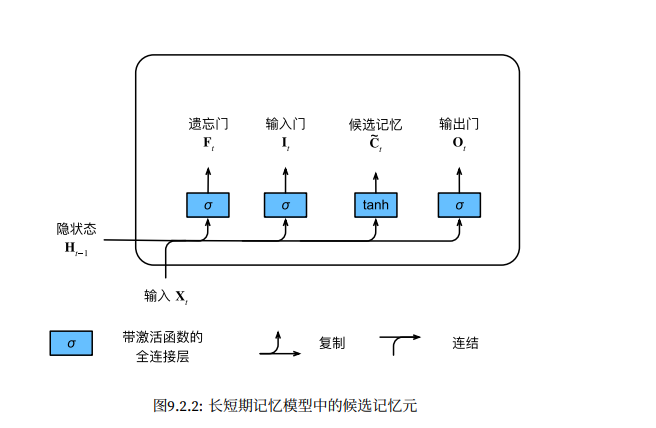
候选记忆元

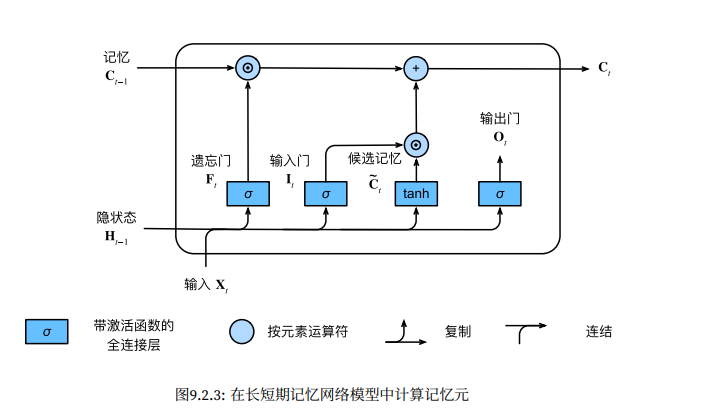
记忆元

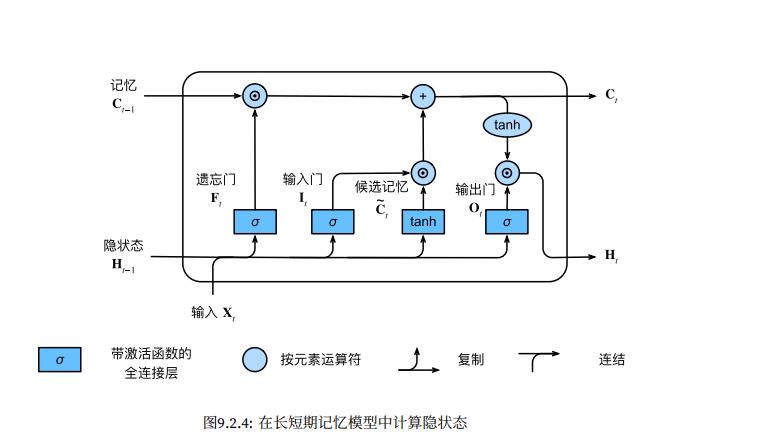
隐状态

2 - 从零开始实现
现在,让我们从零开始实现长短期记忆网络。加载时光机器数据集
import torch from torch import nn from d2l import torch as d2l batch_size,num_steps = 32,35 train_iter,vocab = d2l.load_data_time_machine(batch_size,num_steps)- 1
- 2
- 3
- 4
- 5
- 6
初始化模型参数
接下来,我们需要定义和初始化模型参数。如前所述,超参数num_hiddens定义隐藏单元的数量。我们按照标准差0.01的高斯分布初始化权重,并将偏置项设为0
def get_lstm_params(vocab_size,num_hiddens,device): num_inputs = num_outputs = vocab_size def normal(shape): return torch.randn(size=shape,device=device)*0.01 def three(): return (normal((num_inputs,num_hiddens)), normal((num_hiddens,num_hiddens)), torch.zeros(num_hiddens,device=device)) W_xi,W_hi,b_i = three() # 输入门参数 W_xf,W_hf,b_f = three() # 遗忘门参数 W_xo,W_ho,b_o = three() # 输出门参数 W_xc,W_hc,b_c = three() # 候选记忆元参数 # 输出层参数 W_hq = normal((num_hiddens,num_outputs)) b_q = torch.zeros(num_outputs,device=device) # 附加梯度 params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,b_c, W_hq, b_q] for param in params: param.requires_grad_(True) return params- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
定义模型参数
在初始化函数中,长短期记忆网络的隐状态需要返回一个额外的记忆元,单元的值为0,形状为(批量大小,隐藏单元数)。因此,我们得到以下的状态初始化
def init_lstm_state(batch_size,num_hiddens,device): return (torch.zeros((batch_size,num_hiddens),device=device), torch.zeros((batch_size,num_hiddens),device=device))- 1
- 2
- 3
实际模型的定义与我们前面讨论的一样:提供三个门和一个额外的记忆元。请注意,只有隐状态才会传递到输出层,而记忆元 C t C_t Ct不直接参数输出计算
def lstm(inputs,state,params): [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,W_hq, b_q] = params (H,C) = state outputs= [] for X in inputs: I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i) F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f) O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o) C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c) C = F * C + I * C_tilda H = O * torch.tanh(C) Y = (H @ W_hq) + b_q outputs.append(Y) return torch.cat(outputs, dim=0), (H, C)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
训练和预测
让我们通过实例化引入的RNNModelScratch类来训练一个长短期记忆网络
vocab_size,num_hiddens,device = len(vocab),256,d2l.try_gpu() num_epochs,lr = 500,1 model = d2l.RNNModelScratch(len(vocab),num_hiddens,device,get_lstm_params,init_lstm_state,lstm) d2l.train_ch8(model,train_iter,vocab,lr,num_epochs,device)- 1
- 2
- 3
- 4
perplexity 1.2, 34844.4 tokens/sec on cuda:0 time traveller our charis our cain firmadisal indo the wime trav travelleryou can show black is whice bat i jeen trimets ove- 1
- 2
- 3
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YMrfqepY-1662904128902)(https://yingziimage.oss-cn-beijing.aliyuncs.com/img/202209112131835.svg)]
3 - 简洁实现
使用高级API,我们可以直接实例化LSTM模型。高级API封装了前文介绍的所有配置细节。这段代码的运行速度要快的多,因为它使用的是编译好的运算符而不是Python来处理之前阐述的许多细节
num_inputs = vocab_size lstm_layer = nn.LSTM(num_inputs,num_hiddens) model = d2l.RNNModel(lstm_layer,len(vocab)) model = model.to(device) d2l.train_ch8(model,train_iter,vocab,lr,num_epochs,device)- 1
- 2
- 3
- 4
- 5
perplexity 1.0, 345769.2 tokens/sec on cuda:0 time travelleryou can show black is white by argument said filby travelleryou can show black is white by argument said filby- 1
- 2
- 3
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KLIFlvDm-1662904128902)(https://yingziimage.oss-cn-beijing.aliyuncs.com/img/202209112131836.svg)]
LSTM是典型的具有重要状态控制的隐变量自回归模型,多年来已提出了许多其他变体,例如,多层、残差连接、不同类型的正则化。然而,由于序列的长距离依赖性,训练LSTM和其他序列模型(例如GRU)的成本是相当高的。在后面的内容中,我们将讲述更高级的替代模型, 如transformer
4 - 小结
- 长短期记忆网络有三种类型的门:输入们、遗忘门、输出门
- 长短期记忆的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆完全属于内部信息
- 长短期记忆网络可以缓解梯度消失和梯度爆炸
-
相关阅读:
【Java】常用的文件操作
C++多线程编程(第四章 案例1,C++11和C++17 多核并行计算样例)
适配器模式是个啥,在Spring中又用来干啥了?
Covalent Network(CQT)构建 Web3 最大的结构化数据集,开拓AI、安全性和数据质量的融合
论文解读(IGSD)《Iterative Graph Self-Distillation》
计算即时订单比例-首单使用开窗函数row_number()
2、HTML——标题分组、居中、引用标签、水平线标签下划线标签、删除标签、<font>标签、图像标签
传统视频会议室改造方案
论人类下一代语言的可能—4.2算术后的发展
洛谷基础题练习3
- 原文地址:https://blog.csdn.net/mynameisgt/article/details/126810140