-
Part 4:Pandas新增数据列【直接赋值、apply、assign、分条件赋值】
Pandas怎样新增数据列?¶
在进行数据分析时,经常需要按照一定条件创建新的数据列,然后进行进一步分析
1.直接赋值
2. df.apply方法
3. df.assign方法
4.按条件选择分组分别赋值import pandas as pd1、读取CSV数据到dataframe
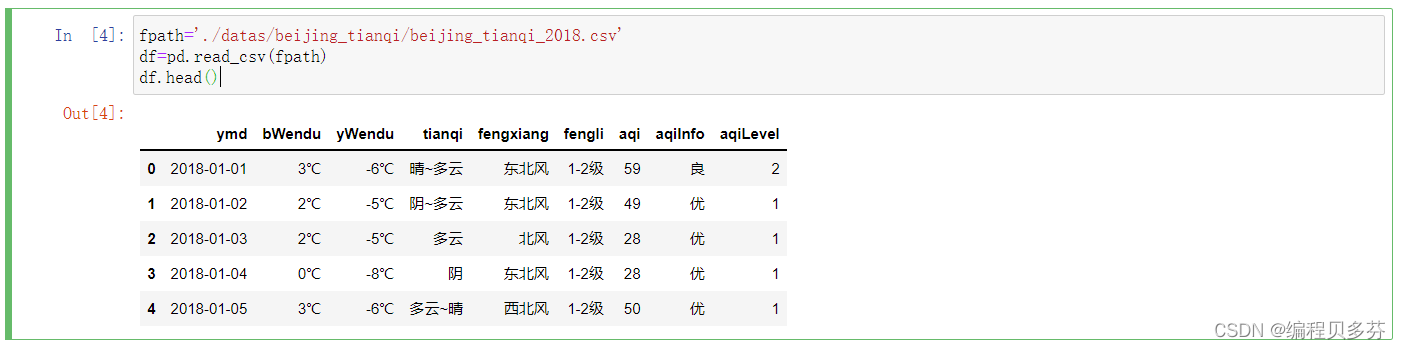
- fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
- df=pd.read_csv(fpath)
- df.head()
2、对数据进行一个预处理
清理温度列,变成一个数字类型
- df.loc[:,'bWendu']=df['bWendu'].str.replace('℃','').astype('int32')
- df.loc[:,'yWendu']=df['yWendu'].str.replace('℃','').astype('int32')
- df.head()
- #AttributeError: Can only use .str accessor with string values! 这种情况下语句代码只能运行一次,当运行第二次的时候,原存储的数据已经被改变了
需要注意的是:AttributeError: Can only use .str accessor with string values! 这种情况下语句代码只能运行一次,当运行第二次的时候,原存储的数据已经被改变了
3、直接赋值方法
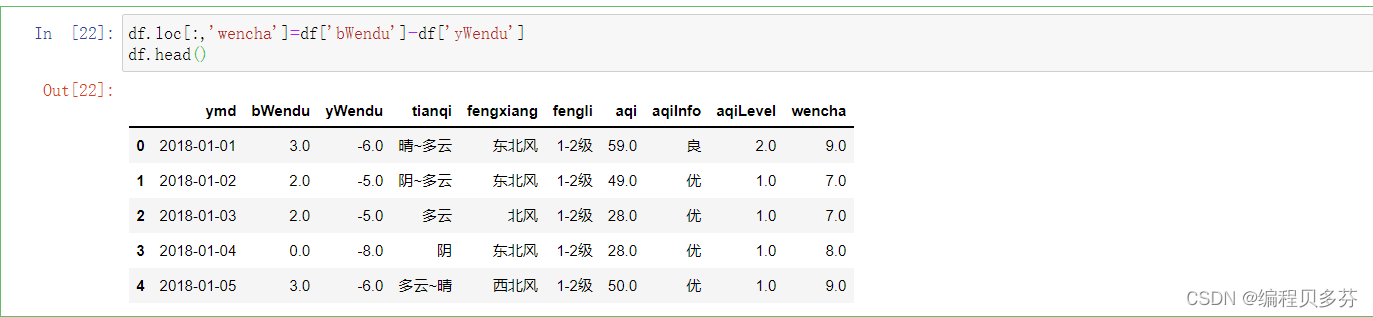
将温差加入表格当中,注意wencha是一个series,后面的减法返回的是一个series
- df.loc[:,'wencha']=df['bWendu']-df['yWendu']
- df.head()
4、df.apply方法
Apply a function along an axis of the DataFrame.
Objects passed to the function are Series objects whose index is either the DataFrame's index(axis=0) or the DataFrame's columns (axis=1).实例:添加─列温度类型:
1.如果最高温度大于33度就是高温
2.低于-10度是低温
3.否则是常温- def get_wendutype(x):
- if x['bWendu']>33:
- return '高温'
- if x['yWendu']<-10:
- return'低温'
- else:
- return '常温'
- df.loc[:,'wendutype']=df.apply(get_wendutype,axis=1)
df['wendutype'].value_counts()
5、df.assign方法
Assign new columns to a DataFrame.
Returns a new object with all original columns in addition to new ones.实例:将温度从摄氏度变成华氏度
注意:df.assign可以同时添加多个列
- #df.assign可以同时添加多个列
- df.assign(
- yWendu_huashi=lambda x: x['yWendu']*9/5+32,
- bWendu_huashi=lambda x: x['bWendu']*9/5+32
- )

6、按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:高低温差大于10度,则认为温差大
- #先创建空列(第一种创建新列的方法)
- df['wencha']=''
- df.loc[df['bWendu']-df['yWendu']>10,'wencha']='温差大'
- df.loc[df['bWendu']-df['yWendu']<=10,'wencha']='温差正常'
- df['wencha'].value_counts()

-
相关阅读:
Excel中插入的图片在不同电脑上消失的问题及解决方法
Qt应用软件【协议篇】GPIO控制LED灯
基于Redission实现分布式锁
Java版工程行业管理系统源码-专业的工程管理软件- 工程项目各模块及其功能点清单
6、python的高级特性(生成式、生成器、闭包、装饰器)
医疗信息管理系统(HIS)——>业务介绍
22 mysql range 查询
【MySQL 8】Generated Invisible Primary Keys(GIPK)
DataBinding 进阶用法
adapter 模式
- 原文地址:https://blog.csdn.net/qq_46044325/article/details/126807762