-
TD Target Algorithms
TD Target Algorithms
1.Sarsa
1.1 名称由来


我们容易求出折扣回报 U t = R t + γ ⋅ U t + 1 U_t=R_t+\gamma\cdot U_{t+1} Ut=Rt+γ⋅Ut+1

可以进行等式变形。

因为无法直接求出期望,考虑用Monte Carlo近似。
1.2表格形式

假设states和actions的个数已知,那么可以建立二维table,不断更新table。

通过observe 一个状态转移,通过策略函数计算 a t + 1 a_{t+1} at+1,然后查表 Q π Q_{\pi} Qπ计算TD target。

然后计算TD error,更新表中的 Q π Q_{\pi} Qπ
1.3 神经网络形式
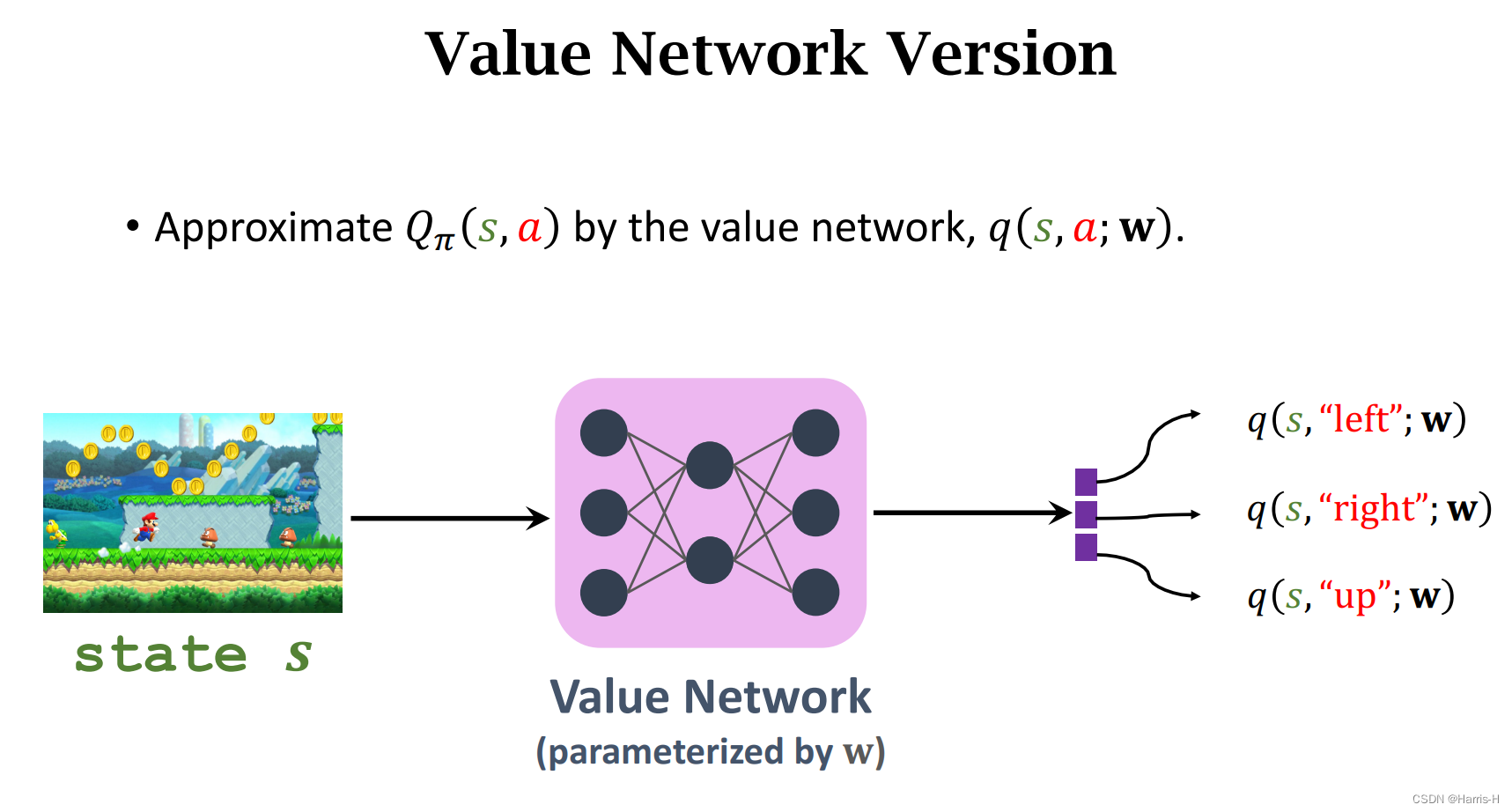

计算TD target 和 TD error,梯度下降更新训练参数 w w w。
1.4 Summary

2.Q-learning
2.1 与Sarsa的区别




等式变形可以得到上式。
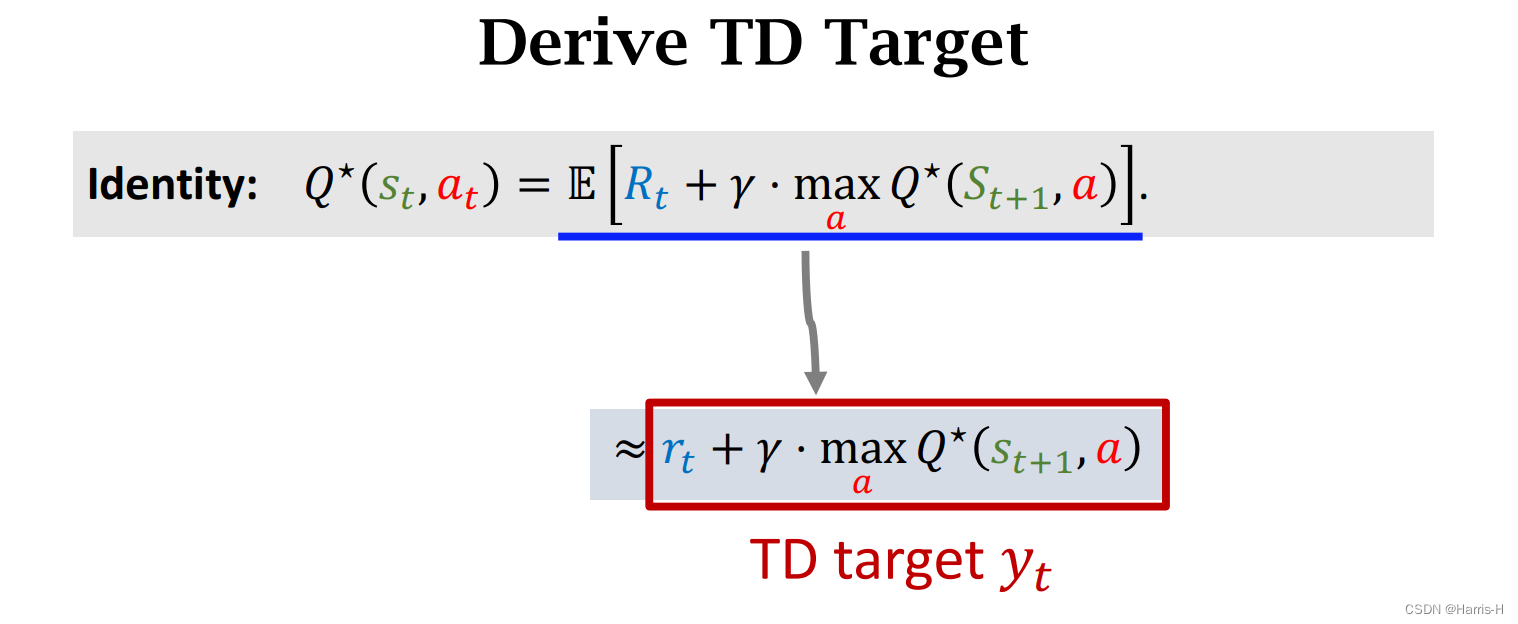
采用Monte Carlo 近似 Q ∗ Q^* Q∗
2.2 Table形式


2.3 DQN形式
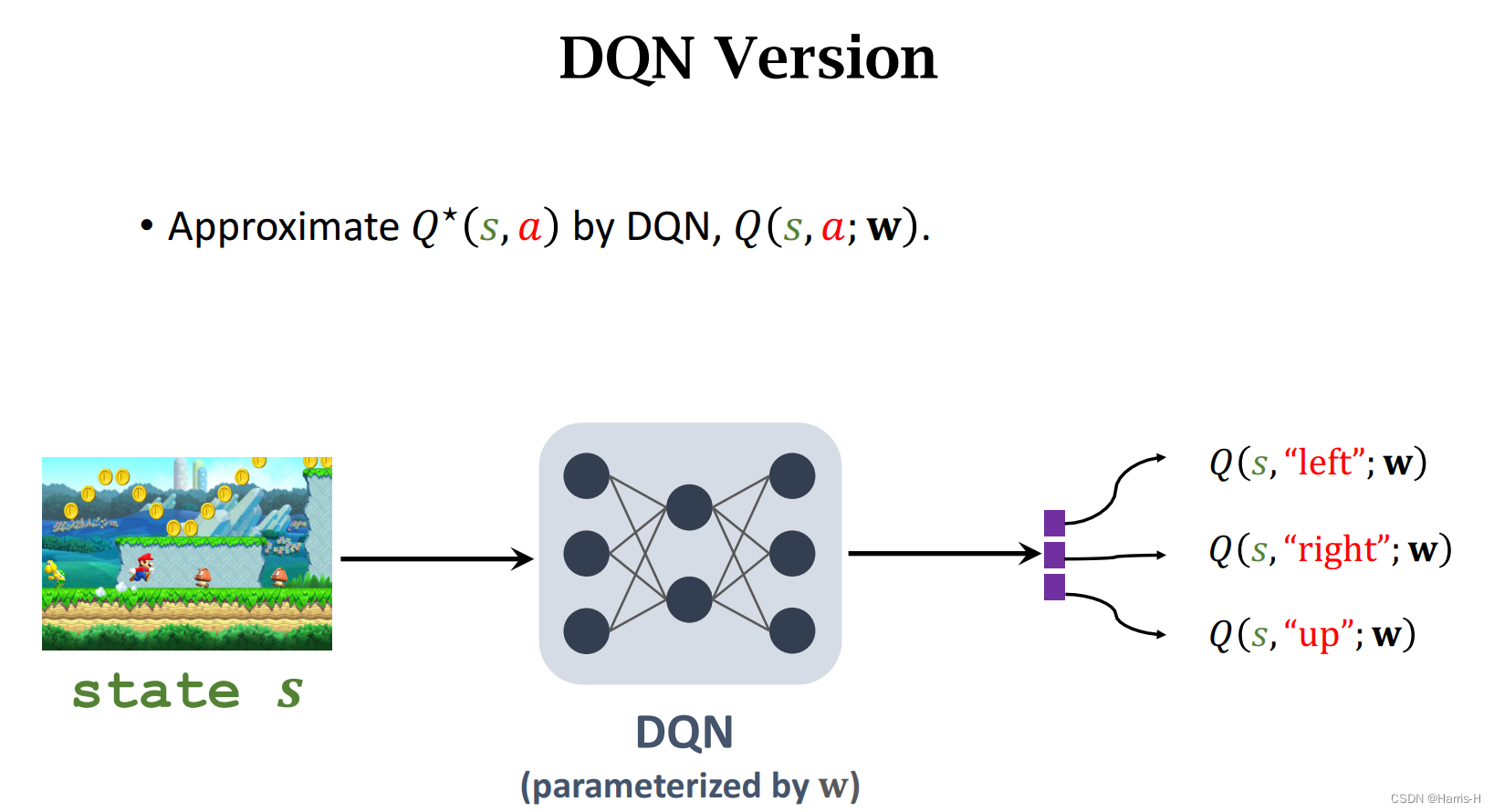

2.4 Summary

3.Multi Step TD Target
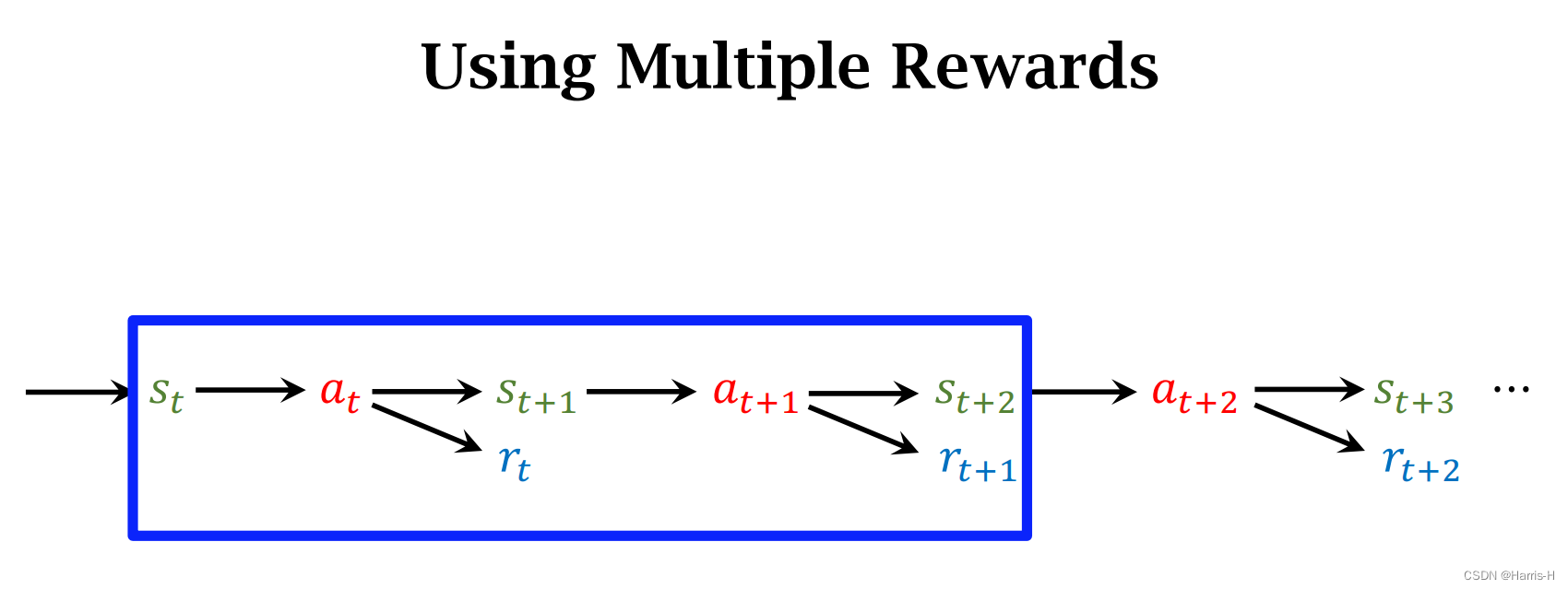


容易得到 U t U_t Ut的变形式。

Sarsa本质是Multi Step TD 的特殊形式 ( m = 1 ) (m=1) (m=1)。

Q-learning 同理。

因为Multi Step TD Target 更接近真实值,因为 r t r_t rt更真实。所以效果会比One-Step 要好,但是需要考虑性能问题(?)
-
相关阅读:
SpringBoot+Freemark根据html模板动态导出PDF
解决conda环境下import TensorFlow失败的问题
Python选择排序和冒泡排序算法
前端uniapp如何修改下拉框uni-data-select下面的uni-icons插件自带的图片【修改uniapp自带源码图片/图标】
大数据ClickHouse进阶(十三):ClickHouse的GROUP BY 子句
牛客网刷题-(2)
stm32Cubemx USB虚拟串口
[ vulhub漏洞复现篇 ] Django debug page XSS漏洞 CVE-2017-12794
JavaEE初阶:文件操作 和 IO
C/C++内存管理
- 原文地址:https://blog.csdn.net/weixin_45750972/article/details/126805488