-
使用Vitis HLS创建属于自己的IP
使用Vitis HLS创建属于自己的IP
副标题-FPGA高层次综合HLS(三)-Vitis HLS创建Vivado IP
高层次综合(High-level Synthesis)简称HLS,指的是将高层次语言描述的逻辑结构,自动转换成低抽象级语言描述的电路模型的过程。
对于AMD Xilinx而言,Vivado 2019.1之前(包括),HLS工具叫Vivado HLS,之后为了统一将HLS集成到Vitis里了,集成之后增加了一些功能,同时将这部分开源出来了。Vitis HLS是Vitis AI重要组成部分,所以我们将重点介绍Vitis HLS。
官方指南:
https://docs.xilinx.com/r/_lSn47LKK31fyYQ_PRDoIQ/root
重要术语
LUT 或 SICE
LUT 或 SICE是构成了 FPGA 的区域。它的数量有限,当它用完时,意味着您的设计太大了!
BRAM 或 Block RAM
FPGA中的内存。在 Z-7010 FPGA上,有 120 个,每个都是 2KiB(实际上是 18 kb)。
Latency延迟
设计产生结果所需的时钟周期数。
循环的延迟是一次迭代所需的时钟周期数。
Initiation Interval (or II, or Interval间隔)
在接受新数据之前必须执行的时钟周期数。
循环的间隔是可以开始循环迭代的最大速率,以时钟周期为单位。
之前,我们一直在使用Vivado给我们提供的IP或者使用硬件描述语言制作 IP 。今天我们将讲解如何使用HLS-高级综合语言来创建属于我们自己的IP。我们将使用的工具称为Vitis HLS,此后称为 HLS。HLS 采用 C 和 C++ 描述并将它们转换为自定义硬件 IP,完成后我们就可以在 Vivado 项目中使用该IP。
Vitis HLS
创建一个新的 HLS 项目:
通过从Linux 终端键入 vitis_hls 或从 Windows 开始菜单运行 HLS 。
PS:Linux系统下可能并没有安装到命令行,所以可能需要使用下面完整命令才能运行HLS:
/opt/york/cs/net/xilinx_vitis-2020.2/Vitis_HLS/2020.2/bin/vitis_hls
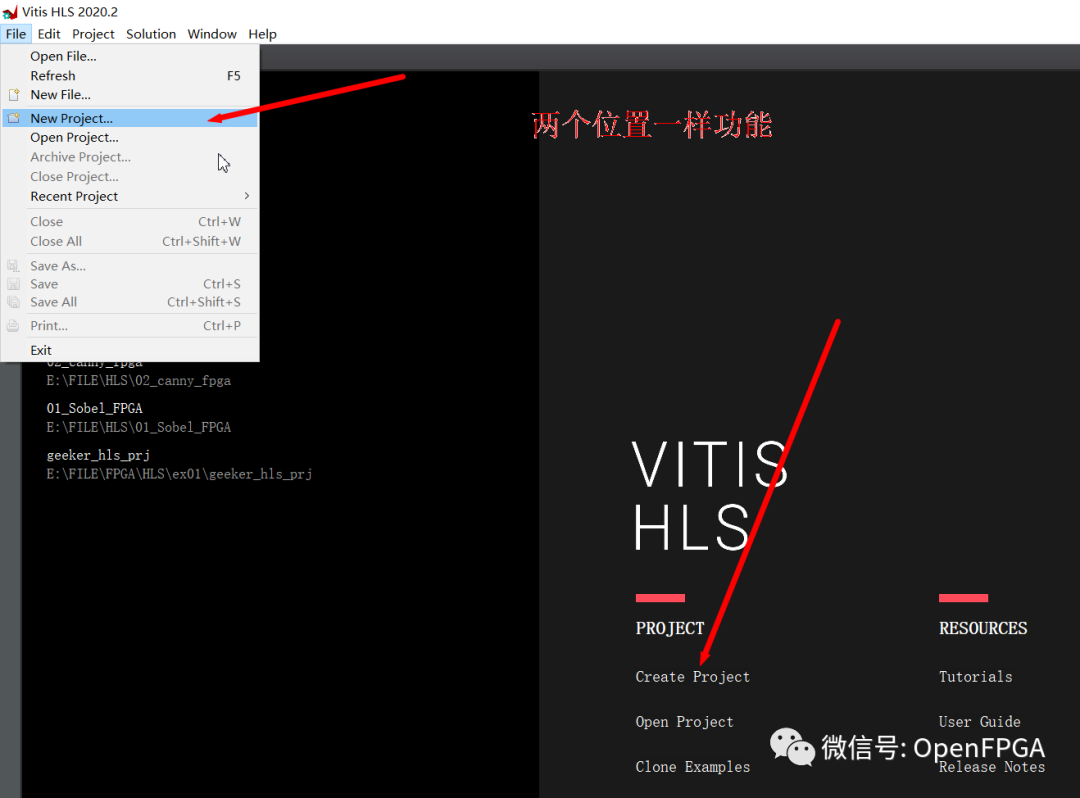
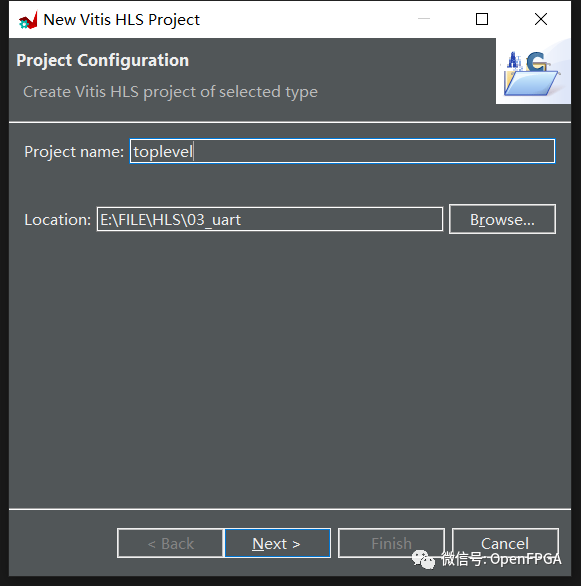
选择创建新项目并为其指定合适的名称和位置。同样,请记住 Xilinx 工具不允许路径或者名称中有空格或者中文。点击下一步。
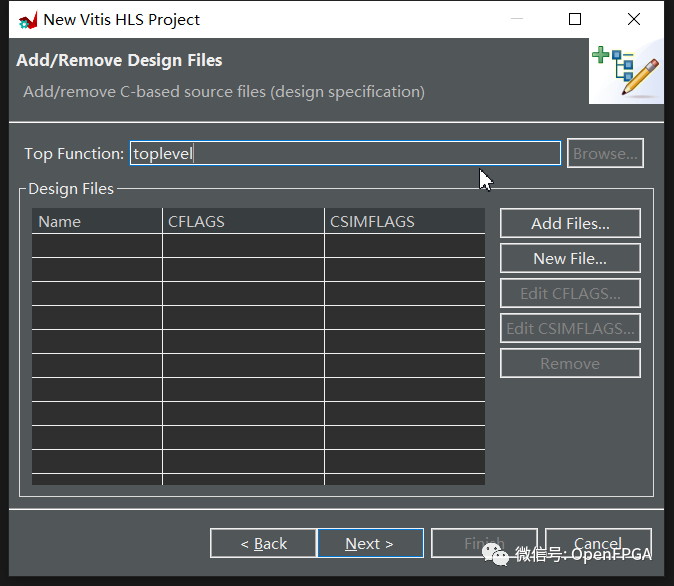
将顶部函数设置为 toplevel。点击下一步。
将时钟周期设置为 10(以纳秒为单位,因此对应于 100MHz 时钟频率,这是提供给 FPGA 架构的默认时钟频率)。
选择FPGA到xc7z020clg484-2。

单击完成。
现在我们就能看到一个 HLS 项目,但它是空的。创建两个名为toplevel.cpp和toplevel.h
toplevel.cpp
- #include "toplevel.h"
- //Input data storage
- #define NUMDATA 100
- uint32 inputdata[NUMDATA];
- //Prototypes
- uint32 addall(uint32 *data);
- uint32 subfromfirst(uint32 *data);
- uint32 toplevel(uint32 *ram, uint32 *arg1, uint32 *arg2, uint32 *arg3, uint32 *arg4) {
- #pragma HLS INTERFACE m_axi port=ram offset=slave bundle=MAXI
- #pragma HLS INTERFACE s_axilite port=arg1 bundle=AXILiteS
- #pragma HLS INTERFACE s_axilite port=arg2 bundle=AXILiteS
- #pragma HLS INTERFACE s_axilite port=arg3 bundle=AXILiteS
- #pragma HLS INTERFACE s_axilite port=arg4 bundle=AXILiteS
- #pragma HLS INTERFACE s_axilite port=return bundle=AXILiteS
- readloop: for(int i = 0; i < NUMDATA; i++) {
- #pragma HLS PIPELINE off
- inputdata[i] = ram[i];
- }
- *arg2 = addall(inputdata);
- *arg3 = subfromfirst(inputdata);
- return *arg1 + 1;
- }
- uint32 addall(uint32 *data) {
- uint32 total = 0;
- addloop: for(int i = 0; i < NUMDATA; i++) {
- #pragma HLS PIPELINE off
- total = total + data[i];
- }
- return total;
- }
- uint32 subfromfirst(uint32 *data) {
- uint32 total = data[0];
- subloop: for(int i = 1; i < NUMDATA; i++) {
- #pragma HLS PIPELINE off
- total = total - data[i];
- }
- return total;
- }
toplevel.h
- #ifndef __TOPLEVEL_H_
- #define __TOPLEVEL_H_
- #include
- #include
- #include
- //Typedefs
- typedef unsigned int uint32;
- typedef int int32;
- uint32 toplevel(uint32 *ram, uint32 *arg1, uint32 *arg2, uint32 *arg3, uint32 *arg4);
- #endif
检查文件
toplevel.cpp 包含整个 EMBS 结构。toplevel函数有五个uint32类型的参数。在typedef.h中描述宽度为32位的无符号整数。
该文件还包含被HLS称为指令的杂注。指令用于告诉HLS如何制作硬件。这里的指令告诉HLS创建AXI主接口和AXI从接口。主接口允许组件访问主存储器,从接口允许ARM内核传入一些变量,并启动、复位和停止组件。一旦构建完成并导出硬件IP,IP将在Vivado中显示如下:
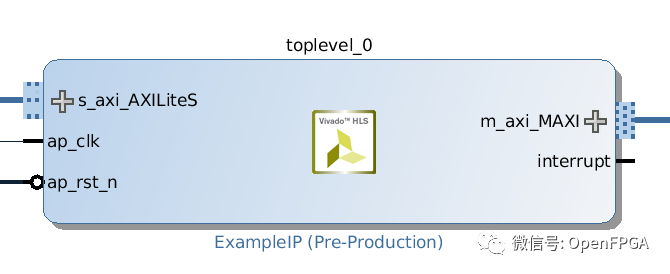
注意三个重要的事情:
没有 main 函数。
我们已经声明了一个函数 toplevel。这将是硬件的“入口点”。
代码中的循环被赋予了标签(readloop、addloop和subloop)。软件中大多数程序员都不这样做,但它在HLS中很有用,稍后您我们将讲解。
测试组件
硬件综合需要的时间比较长。因此,在构建硬件之前,应该充分的验证我们设计的硬件是正确的。测试平台是其中的重要组成部分。测试平台测试代码的功能属性,以确保它不包含任何逻辑错误并且它大致符合要求。因为测试平台是在软件中模拟的,所以无法测试最终硬件的速度。
在 HLS 中,右键单击左侧资源管理器中的“Test Bench”,然后选择“New File”。命名testbench.cpp 并将其放在合理的地方(与之前的toplevel.h文件相同的文件夹中,否则将需要编辑 #include 以获得头文件的相对路径)。
复制以下代码:
testbench.cpp
- #include "toplevel.h"
- #define NUMDATA 100
- uint32 mainmemory[NUMDATA];
- int main() {
- //Create input data
- for(int i = 0; i < NUMDATA; i++) {
- mainmemory[i] = i;
- }
- mainmemory[0] = 8000;
- //Set up the slave inputs to the hardware
- uint32 arg1 = 0;
- uint32 arg2 = 0;
- uint32 arg3 = 0;
- uint32 arg4 = 0;
- //Run the hardware
- toplevel(mainmemory, &arg1, &arg2, &arg3, &arg4);
- //Read the slave outputs
- printf("Sum of input: %d\n", arg2);
- printf("Values 1 to %d subtracted from value 0: %d\n", NUMDATA-1, arg3);
- //Check the values are as expected
- if(arg2 == 12950 && arg3 == 3050) {
- return 0;
- } else {
- return 1; //An error!
- }
- }
注意事项:
我们将一块内存声明为“主内存”。在实际系统中,这是 Z7 板上的 1GB DDR 内存,但对于测试平台,我们只需分配一个足够大的ARRAY即可满足我们的目的。
如果一切正常,测试平台应该返回 0。它将从硬件返回的值与预先计算的值对比,以确保是正确的。
要运行测试平台,请选择 Project | 运行 C Simulation 并在出现的对话框中单击确定。应该会看到 HLS 做了很多工作,但最终会看到测试平台的输出。
- Sum of input: 12950
- Values 1 to 99 subtracted from value 0: 3050
- INFO: [SIM 211-1] CSim done with 0 errors.
- INFO: [SIM 211-3] *************** CSIM finish ***************
- INFO: [HLS 200-111] Finished Command csim_design CPU user time: 0 seconds. CPU system time: 0 seconds. Elapsed time: 4.582 seconds; current allocated memory: 191.719 MB.
- Finished C simulation.
我们已经验证了我们的设计。(如果需求,应该更严格地测试一个真实的设计!)
高层次综合
所以现在我们有了一个仿真好的设计,我们需要研究如何将其转化为硬件。在窗口的右上角,应该看到一行三个按钮-Debug, Synthesis, 和 Analysis(调试、合成和分析)。
这些是透视图,我们将通过单击它们切换。单击合成按钮以确保处于合成透视图中。
打开 toplevel.cpp. 现在单击Solution | Run C Synthesis | C Synthesis(或单击工具栏中的绿色箭头)。将开始进行综合(综合是将 C++ 描述转化为硬件的过程)。
综合完成后,将打开综合报告窗口。这会告诉有关刚刚构建的设计的所有信息。在 Performance Estimates下 查看 Latency 摘要。这应该类似于:
该报告说明设计具有 709 个时钟周期的总体延迟(从第一个数据输入到最后一个数据输出的时间)。它的间隔是 710,这是从一次运行的第一个数据到设计能够接受另一次运行的第一个数据的周期数。
在toplevel行下方,它显示了代码中的三个循环(说明为什么给它们标签是有用的)。循环的延迟是完成所需的周期数。有时 HLS 不会知道这一点(例如,如果循环变量不是静态的)。迭代延迟是一次迭代所花费的周期数。启动间隔仅对流水线循环有效(见下文),行程计数是将计算的迭代总数。
与性能一样重要的是利用率。进一步查看利用率摘要,将看到设计在 FF(触发器)和 LUT(查找表)中的用法。这些是可重构逻辑的度量。还有 DSP(数字信号处理)单元和 BRAM(Block RAM)。Block RAM 是整个 FPGA 架构中非常高速的内存小块。可以在单个时钟周期内读取或写入它们,但每个时钟周期每个 Block RAM 最多可访问两次。这些数字脱离上下文可能有点无意义,因此可以单击表格上方的 % 符号将这些数字转换为 FPGA 的百分比。

上表中主要注意的是 BRAM 和 FF/LUT。此表有助于对大部分设计使用资源的位置进行粗略分类汇总。随着设计变得越来越复杂,可以进一步检查资源以获取更详细的信息。
使用指令调整综合
上边的设计整体看还可以,但可以通过指令进行进一步优化。首先,让我们仔细看看设计是如何实现的。单击“ Analysis”按钮(右上角)转到“ Analysis”透视图。这应该会打开一个性能选项卡。
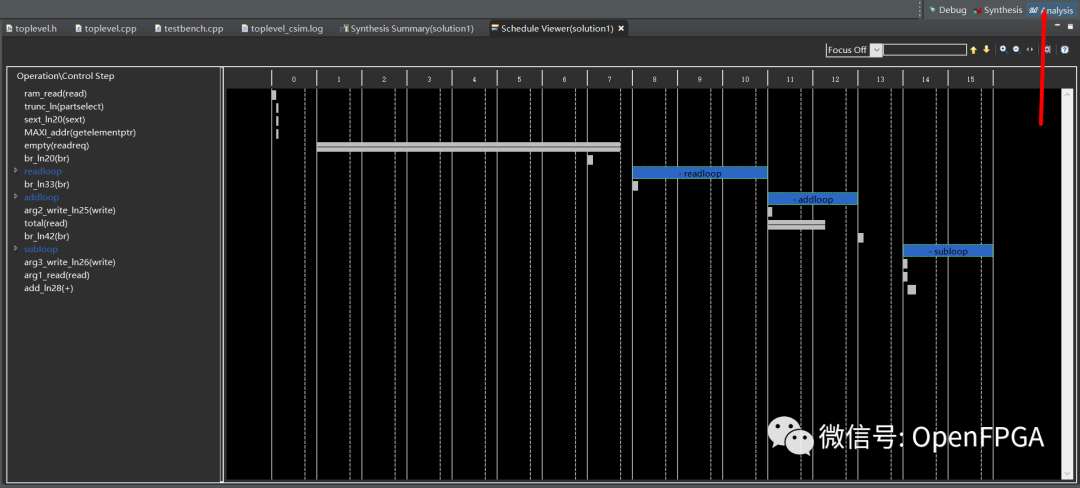
这些行是来自已编译代码的操作。列是状态,因此垂直查看会显示并行发生的所有进程,如果两件事在同一列中,它们会并行发生。目前我们可以看到addloop和subloop循环不重叠,因此它们不是并行完成的。还要注意,addloop和subloop有两种状态。这对应于我们从综合报告中得到的性能估计,该报告告诉我们这两个循环的迭代延迟都是2。
这是因为我作弊了,对不起!
HLS 实际上会做得更好,但我在上面的代码中包含了一些指令,故意关闭一些优化,以便我们更好地了解它们的作用。我们将在下一节中撤消它。可以完全展开每个循环以查看在每个状态下发生的各个操作。还可以右键单击操作并选择 Goto Source 以查看创建它的 C++ 代码行,或者将创建实际 FPGA 硬件的生成的 Verilog 或 VHDL 行。
流水线循环
我们要做的第一个优化是告诉 HLS 流水线 addloop 和 subloop,它们都有两种状态,因此它们可以同时处理两个数据元素。没有流水线,一次只能运行一个迭代,如这些图所示。
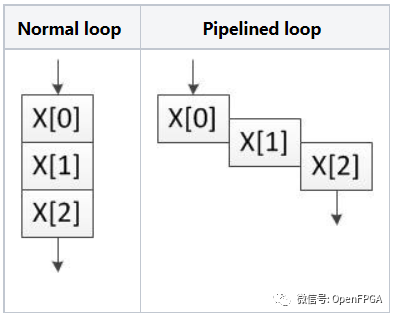
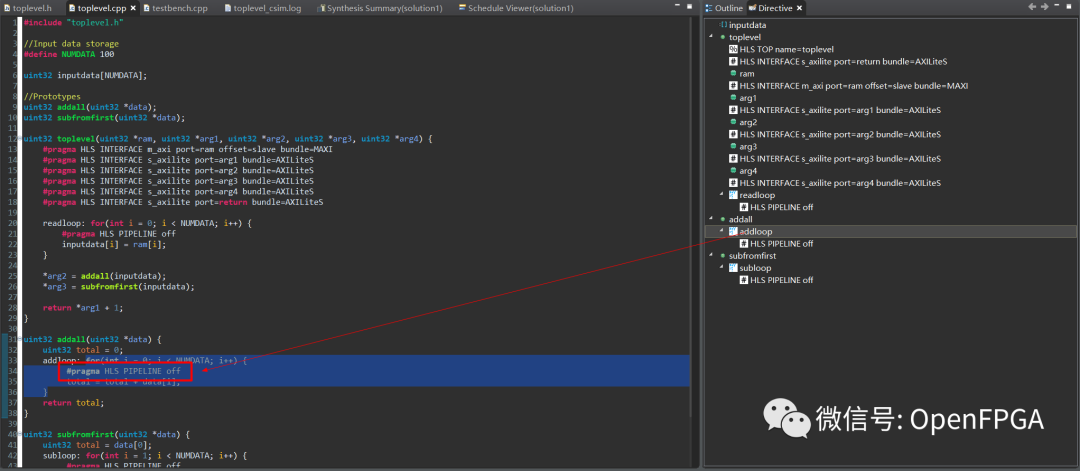
关闭性能报告并返回Synthesis透视图。打开 toplevel.cpp并选择右侧的 Directive 选项卡(或 Window → Show View → Directive)。此选项卡显示源文件中可以附加指令的项目。查找addloop,并注意我包含了指令“HLS PIPELINE off”。这告诉它不要PIPELINE循环。
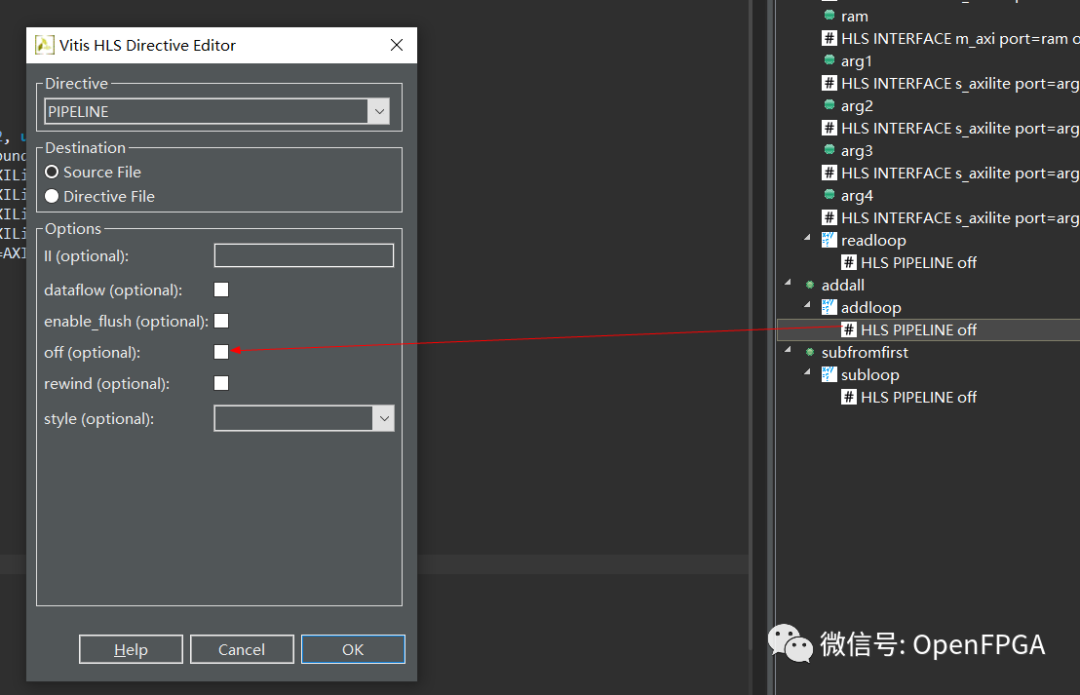
双击该指令并在弹出的对话框中取消选中“关闭”。接下来,重复subloop指令。
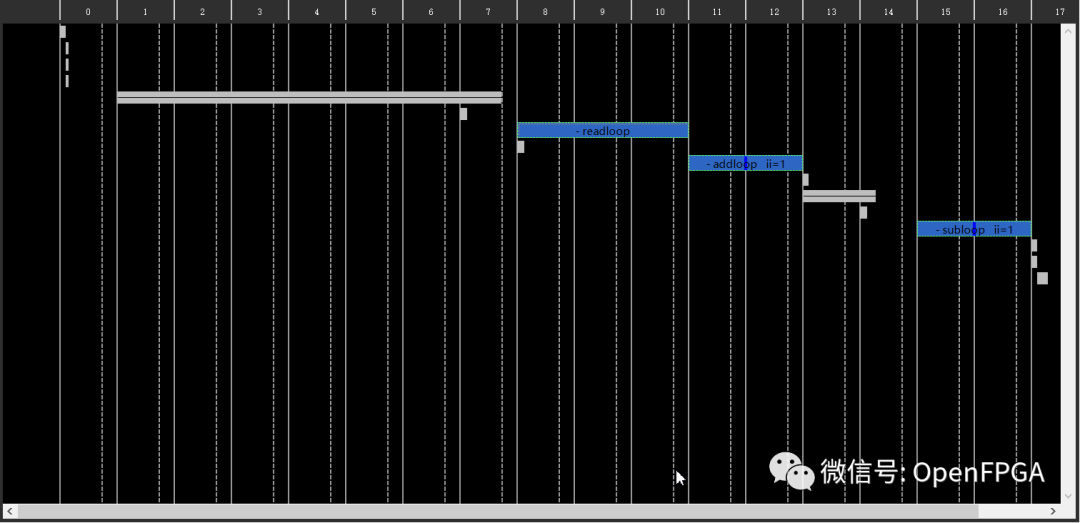
保存文件并重新运行综合(单击绿色箭头)。完成后查看报告。我们立即看到设计的延迟现在是 512 个周期,低于之前的710个。这是因为两个循环同时处理多个数据项。

在综合报告中,将看到两个循环现在已流水线化,它们的 Initiation Interval 现在为 1。这意味着每个时钟周期都可以将数据项推入循环。它们的行程计数(它们执行的次数)是 100 和 99,因此它们的延迟是 100 和 99 个周期,低于之前的 200 和 198。
单击Analysis透视图。流水线还是没有使循环并行发生。速度提升来自于数据项被更快地推入循环的事实。关闭 Performance 选项卡并返回 Synthesis 透视图。
展开循环
比流水线循环更有效地操作是展开它们。UNROLL 指令告诉 HLS 尝试并行执行循环的各个迭代。 这是非常快的,但根据展开的级别可能会花费更多的硬件资源。
在 Synthesis 透视图中, toplevel.cpp 右键单击 addloop 和 subloop 循环上的 PIPELINE 指令并删除它们。有时,上述操作会导致 HLS 弄乱源代码,如果是,请修复它。
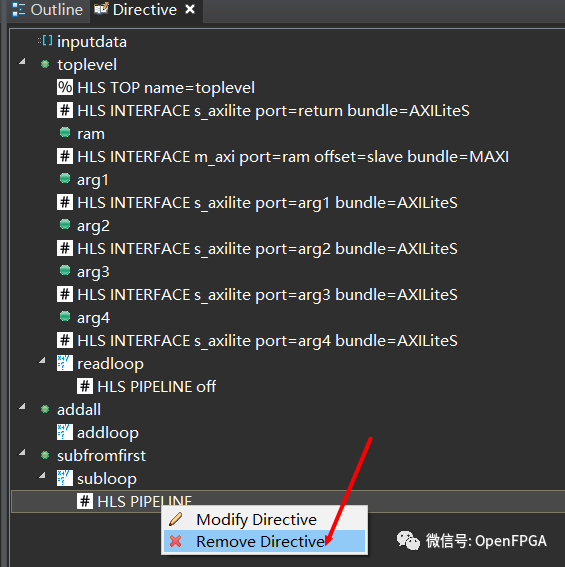
右键单击 addloop 指令面板中的循环,然后选择插入指令,选择 UNROLL。
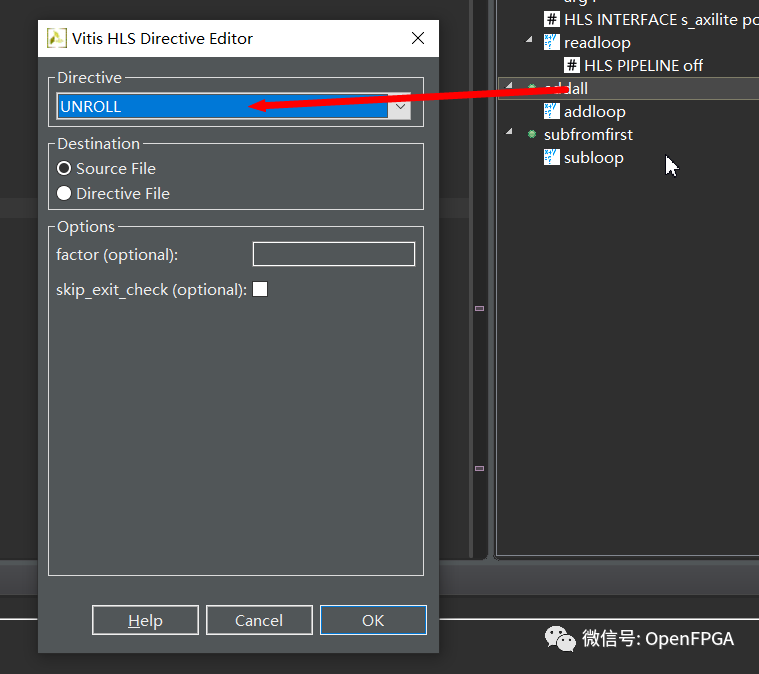
添加指令时,可以选择将指令放在源文件中(作为#pragma指令)或单独的指令文件。我更喜欢使用指令文件,但总的来说没关系。
我们可以在此处添加一个因素来限制展开,但让其留空以表示尽可能展开。单击subloop并重复上诉操作 ,再综合。
现在我们的设计延迟降低到大约 415 个周期,这意味着我们的整体运行速度几乎是原始设计(没有指令)的两倍。然而,我们现在使用了大约 7200 个 LUT——我们的大小超过了 3 倍!HLS 还决定使用 4 个 Block RAM 作为内存而不是 1 个,以便可以并行访问更多数据。这是一个经典的速度/资源权衡,请注意,如果在综合报告中展开“Loop”,则现在只有 readloop。另外两个不见了,因为它们已经完全展开。

单击Analysis透视图。我们的设计看起来完全不同!
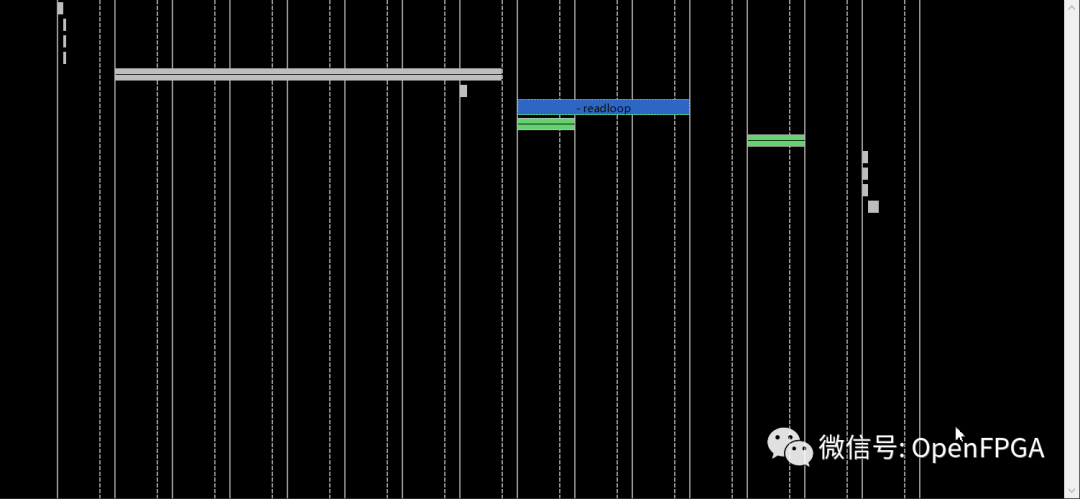
我们注意到的第一件事是函数是可见的。这是因为以前函数非常简单,HLS已经自动内联了它们。现在它们是巨大的硬件,所以它没有。因此,硬件在启动subfromfirst函数之前完成addall函数。让我们强制它内联这些函数,这样它就可以将两个函数的操作安排在一起。将INLINE指令添加到addall和subfromfirst函数中,然后重新综合。
现在我们减少到 364 个周期,并且我们节省了一些硬件,因为 HLS 已经能够优化这两个功能。尽管如此,我们仍然可以做得更好!
为 LUT 交换 Block RAM
让我们告诉 HLS 不要使用 Block RAM,而只使用普通寄存器。在某些设计中,Block RAM 非常 昂贵,但它将允许真正的并行访问。 关闭 Performance 选项卡并返回 Synthesis 透视图。右键单击 inputdata 指令选项卡并选择插入指令。插入 ARRAY_PARTITION 类型的指令 complete。它将询问将其应用于哪个功能。选择 toplevel。
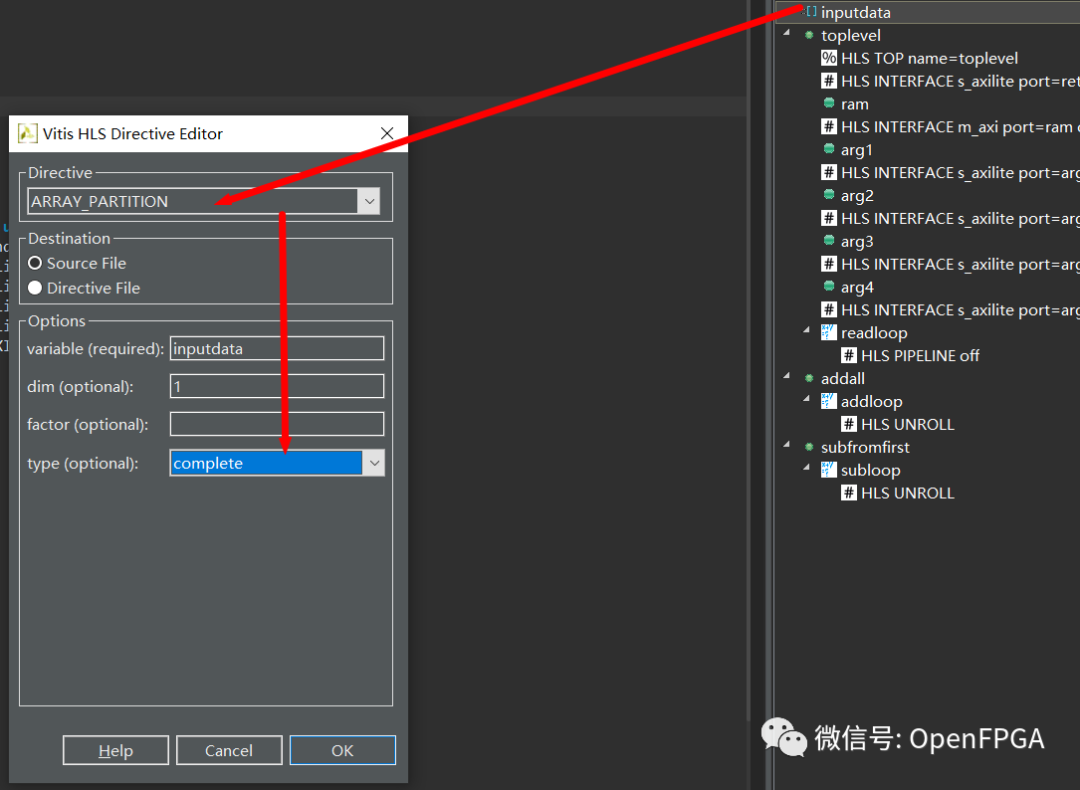
此外,也适用 UNROLL 于 readloop ,因此我们可以完全利用分布式 RAM。
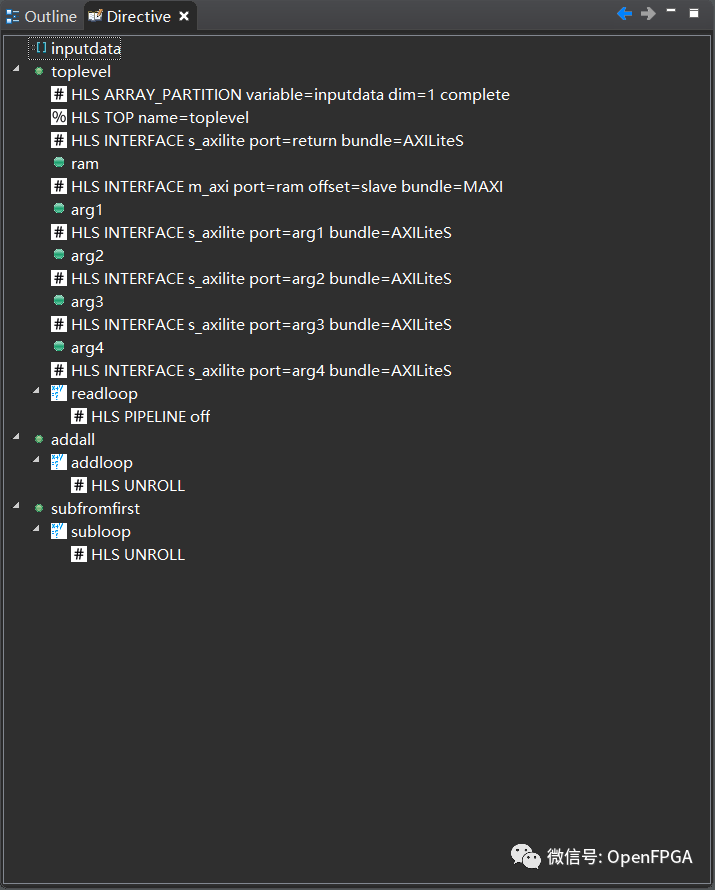
你应该有上面的指令,再综合。

我们现在只有 333 个周期的微小设计延迟。因为设计读取 100 个数据项,我们知道我们的设计永远不会快于 101 个周期,所以这非常好!另请注意,现在我们的 Block RAM 数量减少了,我们的LUT 使用量再次增加。通常ARRAY_PARTITION会显着增加 LUT 的使用,但在这种情况下,我们之前的设计有很多中间存储寄存器,我们基本上已经在这样做了,所以增加并不算太糟糕。请记住,第一次展开使我们的 LUT 使用量增加了 3 倍。这表明了试验指令的重要性,并使用分析视角来计算并行发生的事情。
所以我们现在有一个非常快的设计,但如果我们需要通过流水线而不是展开来使其更小(和更慢),我们也知道如何使其更小(和更慢)。
真正实现它
我们现在将使用测试平台纯粹在 HLS 内部工作。以后的实践将采用 HLS 设计并将它们连接到 ARM 处理系统。
总结
这是《FPGA高层次综合HLS》系列教程第三篇,后面会按照专题继续更新,文章有什么问题,欢迎大家批评指正~感谢大家支持。
-
相关阅读:
项目实战-智慧监督下的合同预付款控制策略-物料价格下行-智慧监督-合同预付款预警推送大数据
数据可视化模块 Matplotlib详解
P1631 序列合并,思维,优先队列
千万支持补助让人心动?成都市关于加快发展先进制造业实现工业转型升级发展若干政策的意见
什么软件可以识别图片上的文字?分享三个实用的识别软件
Python ChatGPT API 新增的函数调用功能演示
Qt5.5.1获取xml文件时,Content-Length为0
Pluma 插件管理框架
Java自定义注解以及Spring的AOP详解,通过AOP和自定义注解实现日志记录
(js)如何删除数组的最后一项
- 原文地址:https://blog.csdn.net/Pieces_thinking/article/details/126792115
