-
【web server】整体流程解析
本篇从
main函数开始,解析程序运行整体流程:
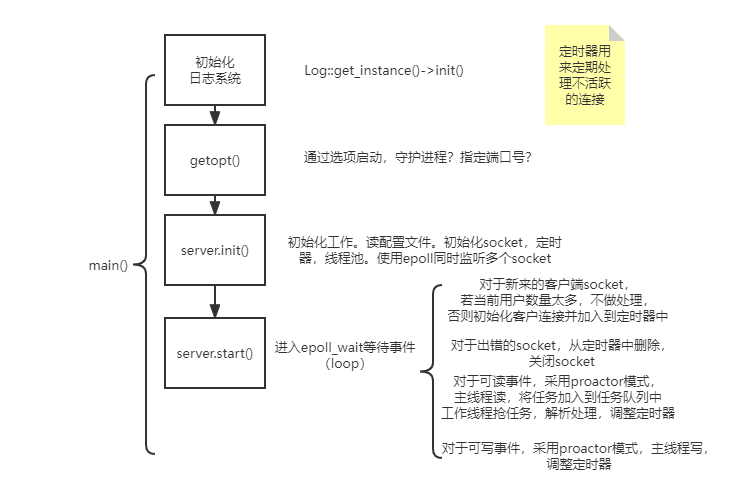
流程图非常清晰,开始时初始化日志系统,记录程序运行中产生的日志信息,通过getopt读取启动选项,之后进行server的初始化工作,并开启server。
启动选项可以选择是否以守护进程的方式运行,以及指定监听的端口号,若不指定端口号,则默认监听在配置文件server.conf中的8080端口。
之后进行server的初始化。包括读取配置文件,创建socket,初始化线程池,定时器等。线程池中创建多个线程抢任务队列中的任务执行。定时器用来计时,长时间不活跃的socket将会被关闭。
往下,进入epoll_wait阻塞,事件类型可以分为四种:新用户连接 出错事件 可读事件 可写事件- 1
- 2
- 3
- 4
对于四种事件,分别去做不同的处理。
其中可读可写事件,均采用proactor模式,即主线程负责读写,工作线程负责处理业务逻辑。if (events[i].events & EPOLLIN) { //可读事件 DBG("read\n"); //主线程读,proactor模式 if (m_pHttpUsers[iSockFd].read()) { //添加任务 m_pThreadPool->append(m_pHttpUsers + iSockFd); ... } } else if (events[i].events & EPOLLOUT) { //可写事件 DBG("out\n"); //主线程写,proactor模式 if (m_pHttpUsers[iSockFd].mwrite()) { ... } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
对于可读事件,主线程读取完数据后,将任务(读完了要解析数据的任务)加到任务队列中,多个线程抢任务执行:
//添加任务 templatebool threadpool ::append(T *request) { m_queuelocker.lock(); if (m_workqueue.size() > m_max_requests) { m_queuelocker.unlock(); return false; } m_workqueue.push_back(request); m_queuelocker.unlock(); m_queuestat.post(); return true; } //work template void *threadpool ::worker(void *arg) { threadpool *pool = (threadpool *)arg; pool->run(); return pool; } //等任务,取任务,执行 template void threadpool ::run() { while (!m_stop) { m_queuestat.wait(); m_queuelocker.lock(); if (m_workqueue.empty()) { m_queuelocker.unlock(); continue; } T *request = m_workqueue.front(); m_workqueue.pop_front(); m_queuelocker.unlock(); if (!request) { continue; } request->process(); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
在process中执行任务:
void Http::process() { //处理读进来的数据 HTTP_CODE read_ret = process_read(); if (read_ret == NO_REQUEST) { modfd(s_iEpollfd, m_iSockFd, EPOLLIN); return ; } bool write_ret = process_write(read_ret); if (!write_ret) { close_conn(); } modfd(s_iEpollfd, m_iSockFd, EPOLLOUT); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
首先处理(解析)读来的数据,当发现该请求需要返回时,执行写操作,修改该
socket为EPOLLOUT,这样主线程发现该socket可写,便执行写操作。这便是程序运行整体流程。
至于如何解析读来的数据,即解析
HTTP协议,以及定时器如何关闭长事件不活跃的连接,就可以单独作为一个模块,之后的文章将会总结。 -
相关阅读:
正则表达式?: ?= ?! 的用法详解
一文带你上手自动化测试中的PO模式!
(Linux)Ubuntu的软件升级 —— update、upgrade、dist-upgrade、full-upgrade
基于Docker与Nginx搭建Nacos2.0.4三节点集群
① 尚品汇的前台开发笔记【尚硅谷】【Vue】
计算机网络:IP
Webpack十大缺点:当过度工程化遇上简单的静态页面
[Shell]常用shell命令及测试判断语句总结
04MQ消息队列
微服务介绍
- 原文地址:https://blog.csdn.net/gaoyuelon/article/details/126802657
