-
前端面试宝典React篇13 如何分析和调优性能瓶颈?
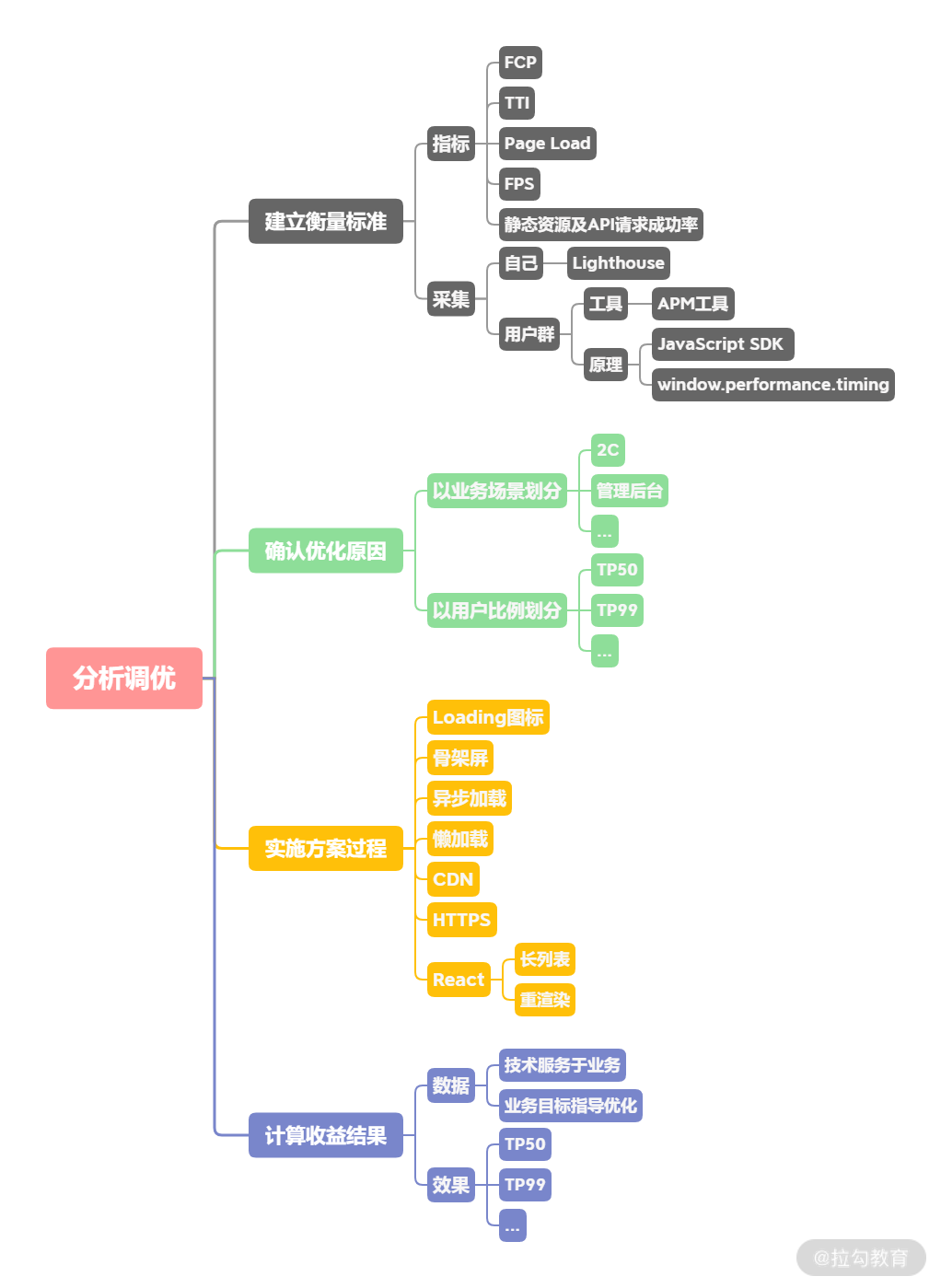
如何做性能优化是一个老生常谈的问题了,但很多同学还是不能答到点儿上。所以这讲,我将为你讲解“如何分析和调优性能瓶颈”,这个面试题该如何回答。
破题
做优化应该是一个有指标、有比较、有数据的过程,就和上一讲我们提到的一样:做工程,应该有调研、有方案、有结果。而很多同学只是回答自己做了方案,比如说自己拆了包、做了懒加载等,对于为什么要这样做,做了有什么收益完全讲不清楚。
这主要是缺乏基准测试,即没能建立起衡量当前性能指标的基线。比如,一个前端页面从打开到完全可用需要耗费 3 秒:
-
这对于 C 端而言是无法接受的;
-
而对于管理后台而言,这样的加载速度是可以接受的。
所以在没有衡量标准的情况下,你很难解释清楚为什么要做优化,优化的收益在哪里。
其实一个问题的解决方案的逻辑应该是自洽的,方案也不是只有代码,并不能把代码等同于你的工作。一个完整的解决方案应该是说清楚标准,讲清楚缘由,理清楚过程,算清楚结果,最后用数据与收益来说明你的工作成果。
审题
整理以上的思路可以得到这样一个答题流程。
-
建立衡量标准,这样可以为优化后计算收益提供指标。衡量标准应该是可量化的,所以要制定可量化的指标。在确认指标之后,还需要有量化基础,有数据积累,那么就需要考虑如何进行数据采集。
-
确认优化原因:有了数据基础后,还需要根据实际场景分析优化能转化多少价值,确认是否需要优化。
-
实施方案:在有了优化点以后,需要制定具体的提升方案并实施。
-
计算收益:在优化方案实施后,需要通过数据描述收益效果。
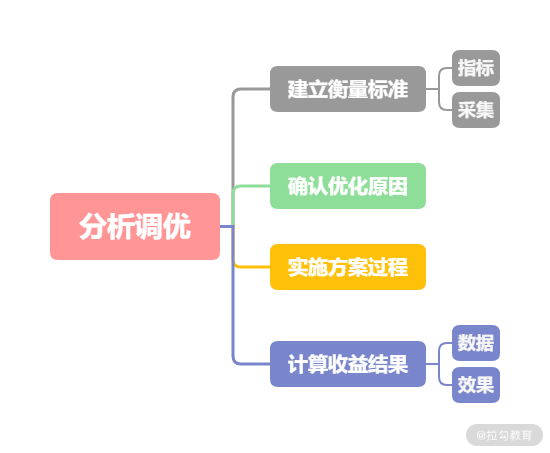
那接下来我们就将“衡量、排查、实施、收益”四个过程展开聊一聊。
入手
衡量
理论基础
分析调优的第一步是要知道问题出在哪儿?就好比看病得先找到病灶。找病灶就需要先体检,看指标,才能找到病因,然后对症下药。
在前端项目中,有开发经验的同学一定有过这样的经历:用户反馈页面慢、页面卡。但用户反馈的慢、卡与开发人员理解的慢、卡是不一样的。我就曾经遇到过这样的用户反馈,他认为每次操作时出现的 Loading 提示都是页面卡的表现,所以他认为整个系统完全没法用。还有的用户会把后端 API 响应慢,认为是网页慢,要求前端工程师去做优化。以上的例子说明,在没有对齐标准的情况下,你很难发现真正的问题在哪儿?那么怎么建立一个标准呢?不妨看看业界是怎么做的?
Google 的 DoubleClick 小组做过一个研究,证明了网页性能在一定程度上影响用户留存率。他们的研究显示,如果一个移动端页面加载时长超过 3 秒,用户就会放弃而离开。这很有意思,结论非常简单,却是可量化的。
显然,数字在沟通上具有降低理解成本、加强印象的魔力,可以说没有比这更好的表达方式了。在此基础上,Google 的 Chrome 小组进一步提出了以用户为核心的 RAIL 模型,用更多的数字维度去阐释网页性能。
RAIL 指响应(Response)、动画(Animation)、浏览器空闲时间(Idle)、加载(Load)四个方面。
-
响应:应在 50 毫秒内完成事件处理并反馈给用户;
-
动画:10 毫秒内生成一帧;
-
浏览器空闲时间:最大化利用浏览器空闲时间;
-
加载:在 5 秒内完成页面资源加载且使页面可交互。
衡量工具
有了标准就要有测量的工具,总不能用肉眼比对吧?Chrome 团队在理论基础上,又进一步提出了名为 Lighthouse 的测量工具。
Lighthouse 内置在 Chrome 中,开启开发者工具就可以找到它。如下图所示:

这个工具用起来也很简单,点击generate report,就可以直接生成一份网站性能报告。如下图所示:
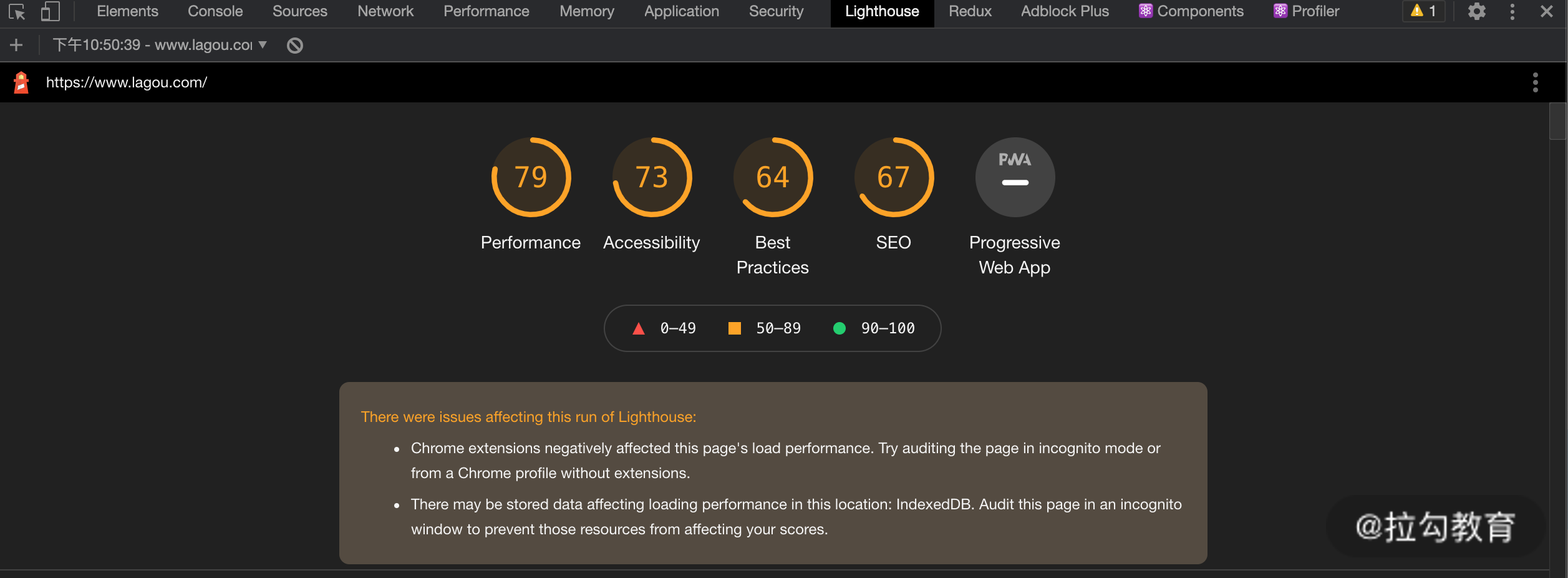
在报告中会对诸如初次内容渲染、可交互时间、加载等进行具体的数值量化并打分,最后还会为整体性能给出一个总体的分数,如下图所示,这里是 79 分。
-
黄色代表当前处于一个用户尚可接受的状态;
-
绿色就代表了表现优异。
那么拉到最底部会有如何优化当前性能指标的指导意见。整份报告不仅包含了当前页面的性能数据,还囊括了最佳实践指南,对于前端开发是非常有指导意义的。如下图所示:
那么既然有了 Lighthouse,照着工具去优化不就完事了吗?道理似乎是这样,但有一个问题需要回答,Lighthouse 是否能反应用户的真实情况呢?
真实情况
作为一个程序员,我们都经历过这样一种情况,QA 不断强调他的电脑打开页面很慢,而你在自己的电脑上通过不断刷新网页证明了加载速度很快。同一个页面在不同的环境下,是否存在性能差异?那么是否需要根据不同的网络环境、不同的浏览器单独衡量呢?
其次是开篇提到的一个问题,对于管理后台而言,需要对标 C 端的加载速度吗?那显然是不需要的。
从以上场景可以看出:
-
Lighthouse 并不能真实地反映出每个用户的设备的实际性能数据;
-
Lighthouse 的分数反应的是业界的标准,而非项目实际需求的标准。
基于以上原因,我们需要自行完成性能指标的采集。一般在大厂,公司相关基建比较成熟,有现成的工具可以直接使用。如果没有呢,你可以考虑使用网页 APM 工具:
-
其中国际上比较老牌的就是 New Relic,做了很多年,实力十分强悍;
-
国内的话可以直接考虑使用阿里云的 ARMS,建议你可以看下它的开发文档,有个基本概念,或者用开源项目自建。
但我个人并不太推荐使用开源项目自行搭建,因为数据的采集和处理都会消耗相当多的服务器资源,与成熟的产品服务相比,不管是投入的人力还是服务器运维成本都会更高。
无论是什么工具,它们都会对齐 Lighthouse 这样一个业界标准,所以完全不用担心指标会有差异,这是业界公认的一件事。所以在面试中,指标及指标的采集方式也会是一个考点。
采集过程
以阿里云的 ARMS 为例,采集通常是由一个 JavaScript SDK 完成的,就像下面这样一个在 script 标签中引入 bl.js 的示例一样:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
接着就是做指标采集工作。指标需要根据业界发展与业务需求去增减或者修改,所以经常会有变化,常用的指标一般有以下几个。
-
FCP(First Contentful Paint),首次绘制内容的耗时。首屏统计的方式一直在变,起初是通过记录 window.performance.timing 中的 domComplete 与 domLoading 的时间差来完成,但这并不具备交互意义,现在通常是记录初次加载并绘制内容的时间。

-
TTI(Time to Interact),是页面可交互的时间。通常通过记录 window.performance.timing 中的 domInteractive 与 fetchStart 的时间差来完成。
-
Page Load,页面完全加载时间。通常通过记录 window.performance.timing 中的 loadEventStart 与 fetchStart 的时间差来完成。
-
FPS,前端页面帧率。通常是在主线程打点完成记录。其原理是 requestAnimationFrame 会在页面重绘前被调用,而 FPS 就是计算两次之间的时间差。
let lastTime = performance.now() let frame = 0 let lastFameTime = performance.now() const loop = (time) => { const now = performance.now() lastFameTime = now frame++ if (now > 1000 + lastTime) { let fps = Math.round(frame / (( now - lastTime ) / 1000)) frame = 0 lastTime = now console.log(fps) } window.requestAnimationFrame(loop) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
静态资源及API 请求成功率。通常是通过 window.performance.getEntries( ) 来获取相关信息。

以上就是衡量的理论基础、指标体系与采集方式,那么接下来看一下如何优化。
排查
优化最难的地方在于定目标。
制定目标有一个前提,对象是谁?很多应聘者在描述优化的时候,喜欢讲页面在优化方案下,快了多少倍。正如前文所分析的,这是不准确的。如果我们要提升网页的加载速度,应该把关注点放在整个用户群,而不是只有自己。
我们不妨假设,现在已经收集到了用户页面的性能数据,比如 FCP 的数据是 1 秒,3 秒,4 秒,6 秒,7 秒,8 秒,65 秒。那提升性能就是去提升他的平均数值吗?平均数约 39 秒,并不能反映整体情况。如下图所示。
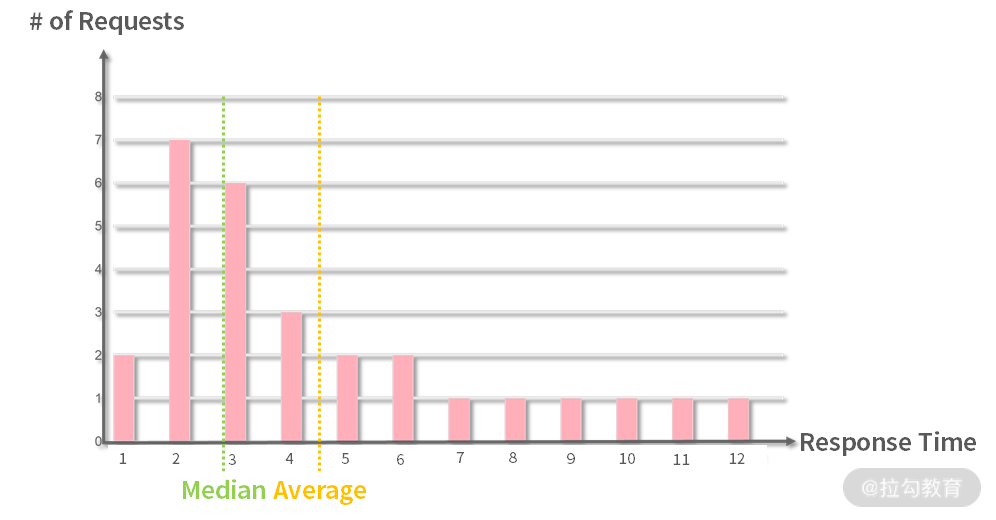
在性能监控中有一个概念叫TP(Top Percentile),比如 TP50、TP90、TP99 和 TP999 等指标,指高于 50%、90%、99% 等百分线的情况。如 TP50 就意味着,50% 的用户打开页面绘制内容的时间不超过 6 秒,90%的用户不超过 8 秒。如果要提升 FCP,那么就需要提升 TP 50、TP90、TP999 下的数据,这才是有正确方向的目标。
其次就是场景,如果是 2C 的页面,那么 FCP、TTI、FPS、Page Load、静态资源及 API 请求成功率等几个指标都很重要,会直接影响关键业务的转化率,而管理后台,更关注的是使用起来功能是否完整,运行是否流畅,对加载速度并没有很高的要求,所以通常只对 FPS 、静态资源及 API 请求成功率这三个指标更为关注。显然,指标的选择取决于你的业务形态。
这样对于优化大致就有一个落脚点了,接下来就可以探讨如何做实施工作了。
实施
这部分拿 FCP、TTI、Page Load、FPS、静态资源及 API 请求成功率这六个指标来进行讲解。
FCP
回到 React 的角度来看,加载一个 React 页面,通常是从白屏到直接显示内容。那么如果白屏时间很长,用户可能会流失,就需要在页面上绘制内容,给出一些反馈。
最早的优化方案是绘制一个Loading图标,写死在 HTML 的 CSS 里,等 JS 开始执行的时候再移除它。
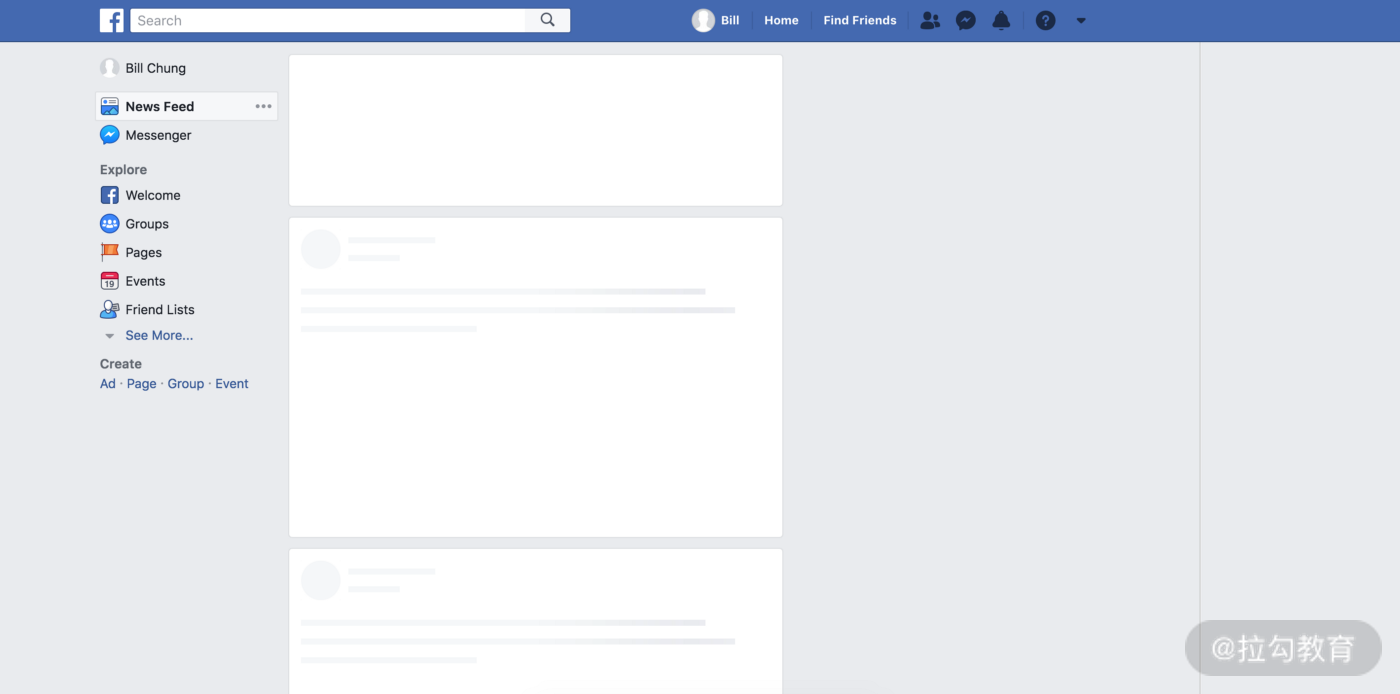
后来有了骨架屏的概念,如下面 Facebook 的网页显示。在内容还没有就绪的时候,先通过渲染骨架填充页面,给予用户反馈。
还有一种解决方案是SSR,也就是走服务端渲染路线,常用的方案有 next.js 等。
TTI
TTI 在实现上,可以优先加载让用户关注的内容,让用户先用起来。策略上主要是将异步加载与懒加载相结合。比如:
-
核心内容在 React 中同步加载;
-
非核心内容采取异步加载的方式延迟加载
-
内容中的图片采用懒加载的方式避免占用网络资源。
Page Load
页面完整加载时间同样可以通过异步加载的方式完成。异步加载主要由 Webpack 打包 common chunk 与异步组件的方式完成。
FPS
FPS 主要代表了卡顿的情况,在 React 中引起卡顿的主要原因有长列表与重渲染。长列表的解决方案很成熟,直接使用 react-virtualized 或者 react-window 就可以,相关的原理你可以自行学习;重渲染的问题比较复杂,下一讲我会详细讲解。
静态资源及 API 请求成功率
静态资源及 API 请求成功率的统计是非常有意义的。两者都有可能出现在用户的机器上失败,但在自己的电脑上毫无问题的情况。导致这个问题的原因千奇百怪。
-
你是直接从前端服务器拉取 JS 与 CSS 资源,还是从 CDN 拉取的?
-
解析 CDN 与 API 域名存在失败的情况。
-
运营商对静态资源及 API 请求做了篡改,导致请求失败。
那怎么解决这些问题呢?
-
对于静态资源而言,能用 CDN 就用 CDN,可以大幅提升静态资源的成功率。
-
如果域名解析失败,就可以采取静态资源域名自动切换的方案;还有一个简单的方案是直接寻求 SRE 的协助。
-
如果有运营商对内容做了篡改,我推荐使用 HTTPS。
收益
技术必须服务于业务,否则就只是技术团队的自嗨。
所以从技术角度讲收益,需要从业务实际效益出发。就像开篇所说的:“如果一个移动端页面加载时长超过 3 秒,用户就会放弃而离开。”那么将 TP999 从 5 秒优化到 3 秒以内,就可以得出具体的用户转化率数据。这样的技术优化才是对公司有帮助的。
答题
接下来我将用本文讲到的方案进行回答。
我负责的业务是 CRM 管理后台,用户付费进入操作使用,有一套非常标准的业务流程。在我做完性能优化后,整个付费率一下提升了 17%,效果还可以。
前期管理后台的基础性能数据是没有的,我接手后接入了一套 APM 工具,才有了基础的性能数据。然后我对指标观察了一周多,思考了业务形态,发现其实用户对后台系统的加载速度要求并不高,但对系统的稳定性要求比较高。我也发现静态资源的加载成功率并不高,TP99 的成功率大约在 91%,这是因为静态资源直接从服务器拉取,服务器带宽形成了瓶颈,导致加载失败。我对 Webpack 的构建工作流做了改造,支持发布到 CDN,改造后 TP99 提升到了 99.9%。
总结
本文中 React 相关的内容偏少,因为在做页面性能优化的工作时,无论你采用什么前端框架,工作流程都是一样的。需要结合业务形态与指标数据去思考要优化哪些指标,如果不优化是否可行。在实施部分,大致讲解了每个指标对应 React 的优化情况,因为方案都很成熟,所以你可以根据方案自行学习,了解下原理与使用方式。
其中重渲染是一个比较麻烦且容易出错的点,所以在下一讲中,将会着重为你介绍重渲染应该如何处理。
《大前端高薪训练营》
精选评论
**磊:
老师采集的开源项目,有什么推荐么?我想找个代码看看
讲师回复:
推荐三个吧,希望能帮到你。
第一个是灯塔,https://github.com/LianjiaTech/fee,old school,功能齐全完善,还有详细的手册阅读。
第二个是 https://github.com/wangweianger/zanePerfor,作者热忱极高,完整的从 0 到 1。
第三个是 rrweb,https://github.com/rrweb-io/rrweb 另辟蹊径,产品完善,实用性强。 -
-
相关阅读:
【App 抓包提示网络异常怎么破?】
typescript21-接口和类型别名的对比
记录前端通过XShell和xftp发布版本
如何看待三测?天王级项目Aleo三测预期收益的深度解读
利用快速排序的思想寻找第k小的元素
如何轻松打造属于自己的水印相机小程序?
Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation
es6新特性
第八章 字符输入输出和输入验证
一种用于肽图分析的烷化剂,Desthiobiotin-Iodoacetamide
- 原文地址:https://blog.csdn.net/fegus/article/details/126801930