-
浅谈实时计算
01 引言
说到实时计算,首先我们需要了解其概念。
实时计算 是一种持续、低时延、事件触发的计算作业
实时计算有如下三种特点:
- 实时(Realtime)且无界(Unbounded)的数据流:实时计算面对的数据是实时且流式的,这些数据按照时间发生顺序被实时计算订阅和消费,例如网站的访问单击日志流,只要网站不关闭,其单击日志流将不停产生并进入实时计算系统;
- 持续(Continous)且高效的计算:实时计算是一种事件触发的计算模式,触发源为无界流式数据,一旦有新的流数据进入实时计算系统,它就立刻发起并进行一次计算任务,因此整个过程是持续进行的;
- 流式(Streaming)且实时的数据集成:被流数据触发的计算结果,可以被直接写入目的数据存储,例如将计算后的报表数据直接写入关系型数据库进行报表展示,因此流数据的计算结果可以同流式数据一样,持续被写入目的数据存储。
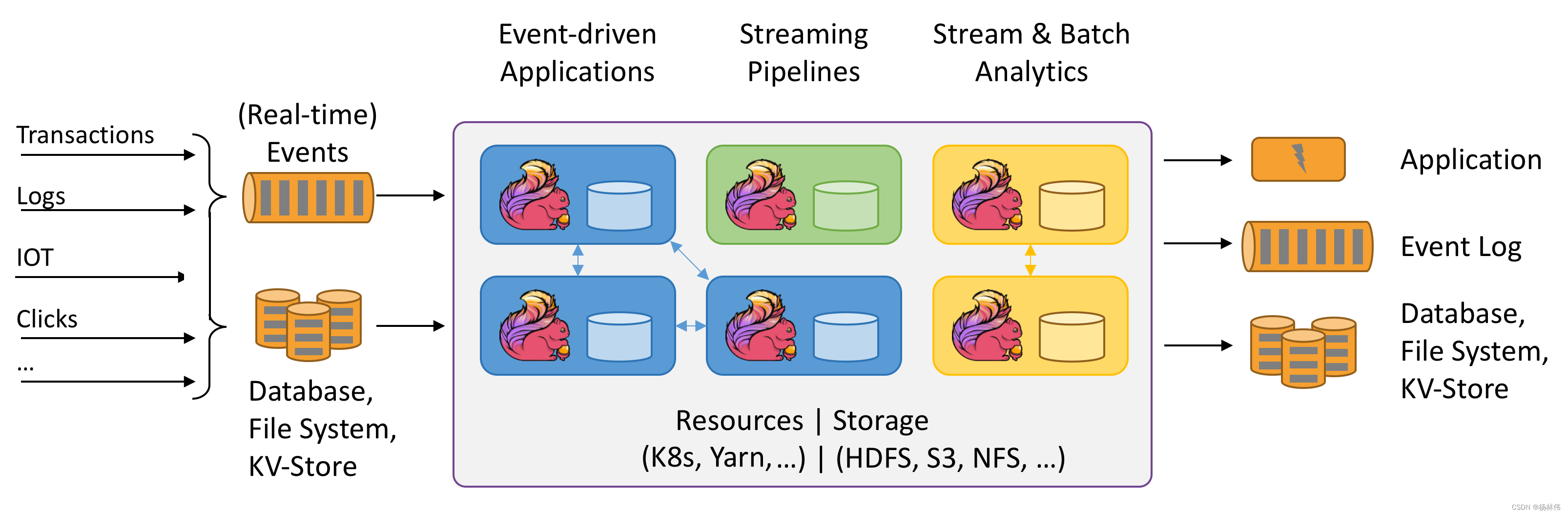
说到实时计算的实现,有很多种技术手段,目前主流的技术实现是Flink,博主曾经开过
Flink的专栏,有兴趣的同学可以了解下《Flink专栏》。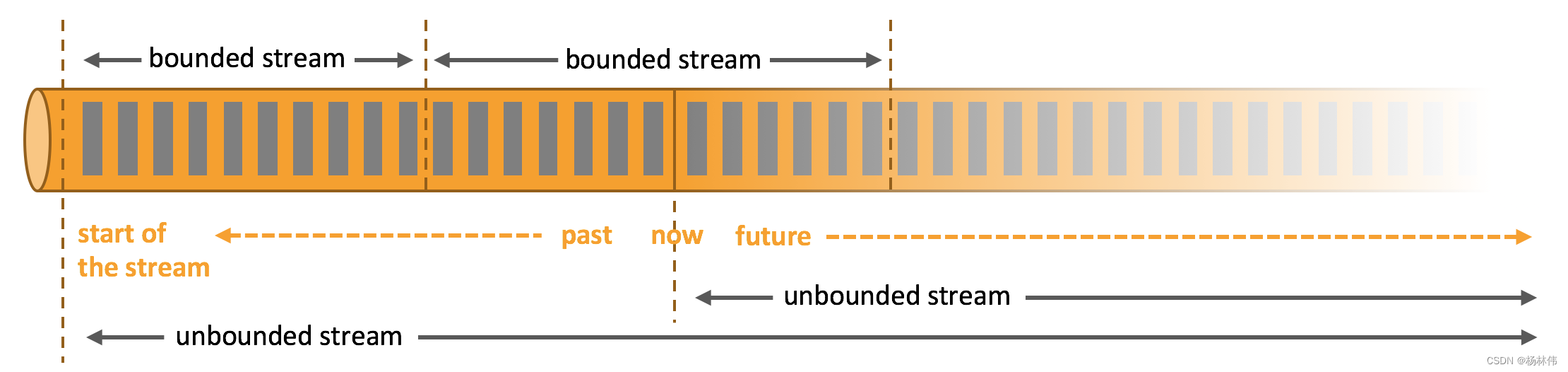
02 为何选择Flink?
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算,Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
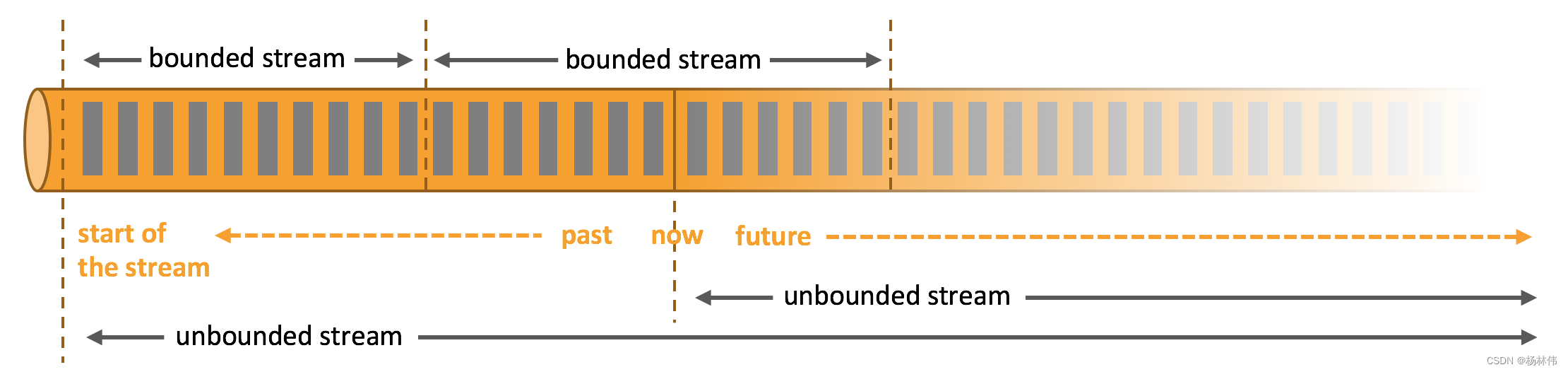
2.1 处理无界和有界数据
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用,有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
- 无界数据:有定义流的开始,但没有定义流的结束,它们会无休止地产生数据,无界流的数据必须持续处理,处理无界数据通常要求以特定顺序摄取事件,例如:事件发生的顺序,以便能够推断结果的完整性,可以理解为流处理;
- 有界数据:有定义流的开始,也有定义流的结束,有界流可以在摄取所有数据后再进行计算,有界流所有数据可以被排序,所以并不需要有序摄取,有界流处理通常被称为批处理。
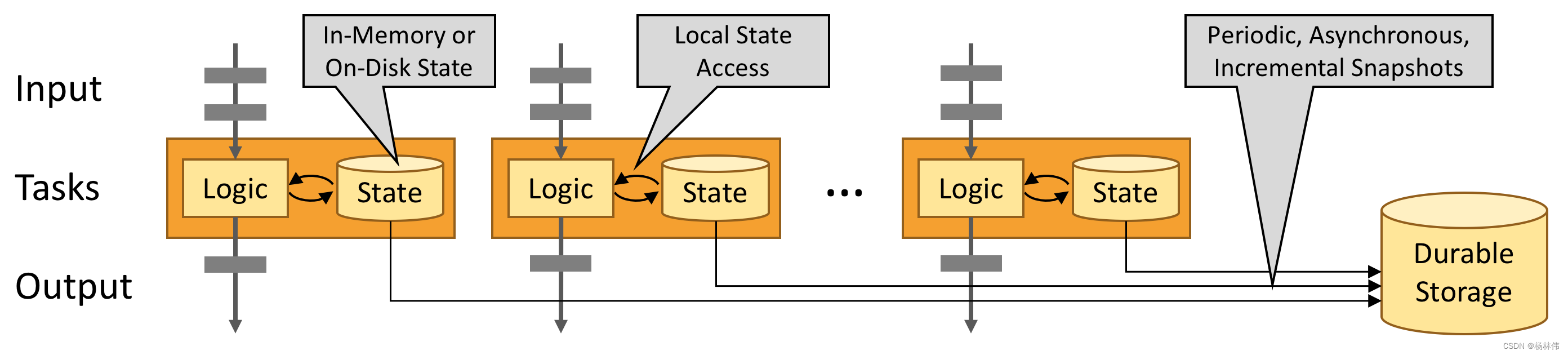
2.2 利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。
- 任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟;
- Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
2.4 运维部署
2.4.1 高可用
Flink通过几下多种机制维护应用可持续运行及其一致性:
- 检查点的一致性:
Flink的故障恢复机制是通过建立分布式应用服务状态一致性检查点实现的,当有故障产生时,应用服务会重启后,再重新加载上一次成功备份的状态检查点信息。结合可重放的数据源,该特性可保证精确一次(exactly-once)的状态一致性; - 高效的检查点: 如果一个应用要维护一个
TB级的状态信息,对此应用的状态建立检查点服务的资源开销是很高的,为了减小因检查点服务对应用的延迟性(SLAs服务等级协议)的影响,Flink采用异步及增量的方式构建检查点服务。 - 端到端的精确一次:
Flink为某些特定的存储支持了事务型输出的功能,及时在发生故障的情况下,也能够保证精确一次的输出。 - 集成多种集群管理服务:
Flink已与多种集群管理服务紧密集成,如 Hadoop YARN, Mesos, 以及 Kubernetes。当集群中某个流程任务失败后,一个新的流程服务会自动启动并替代它继续执行。 - 内置高可用服务: Flink内置了为解决单点故障问题的高可用性服务模块,此模块是基于Apache ZooKeeper 技术实现的,Apache ZooKeeper是一种可靠的、交互式的、分布式协调服务组件。
2.4.2 部署至任意地方
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(
resource-manager-specific)的部署模式实现的,Flink 可以采用与当前资源管理器相适应的方式进行交互。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成。Apache Flink 是一个分布式系统,它除了可以作为独立集群运行,同时需要计算资源来执行应用程序,Flink 集成了所有常见的集群资源管理器,例如:
2.4.3 运行任意规模应用
除此,Flink可以运行任意规模应用。应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行,所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO,而且 Flink 很容易维护非常大的应用程序状态,其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
03 解决方案
好了,至此已经讲完了为何选择Flink作为实时计算的技术实现的原因了,那么目前的市面上是否有实时计算的解决方案呢?其实在Flink的官方网站已经提供了一些供应商的解决方案参考:https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/deployment/overview/。
下面来举几个例子。
3.1 阿里云 - 实时计算Flink版
实时计算Flink版:https://help.aliyun.com/product/45029.html
操作参考文档:
- SQL 作业:https://help.aliyun.com/document_detail/333392.html
- JAR 作业:https://help.aliyun.com/document_detail/338405.html

3.2 腾讯云 - 数据开发
数据开发治理平台(Wedata):https://cloud.tencent.com/document/product/1267
操作参考文档:https://cloud.tencent.com/document/product/1267/72515
目前的产品其实已经支持了,只是官方的文档没有更新
3.3 华为云 - DLI
操作文档参考:https://support.huaweicloud.com/usermanual-dli/dli_01_0403.html
3.4 青云科技 - 大数据工作台
青云科技: https://docsv3.qingcloud.com/bigdata/dataomnis/intro/introduction/
操作文档:https://docsv3.qingcloud.com/bigdata/dataomnis/quickstart/summary/
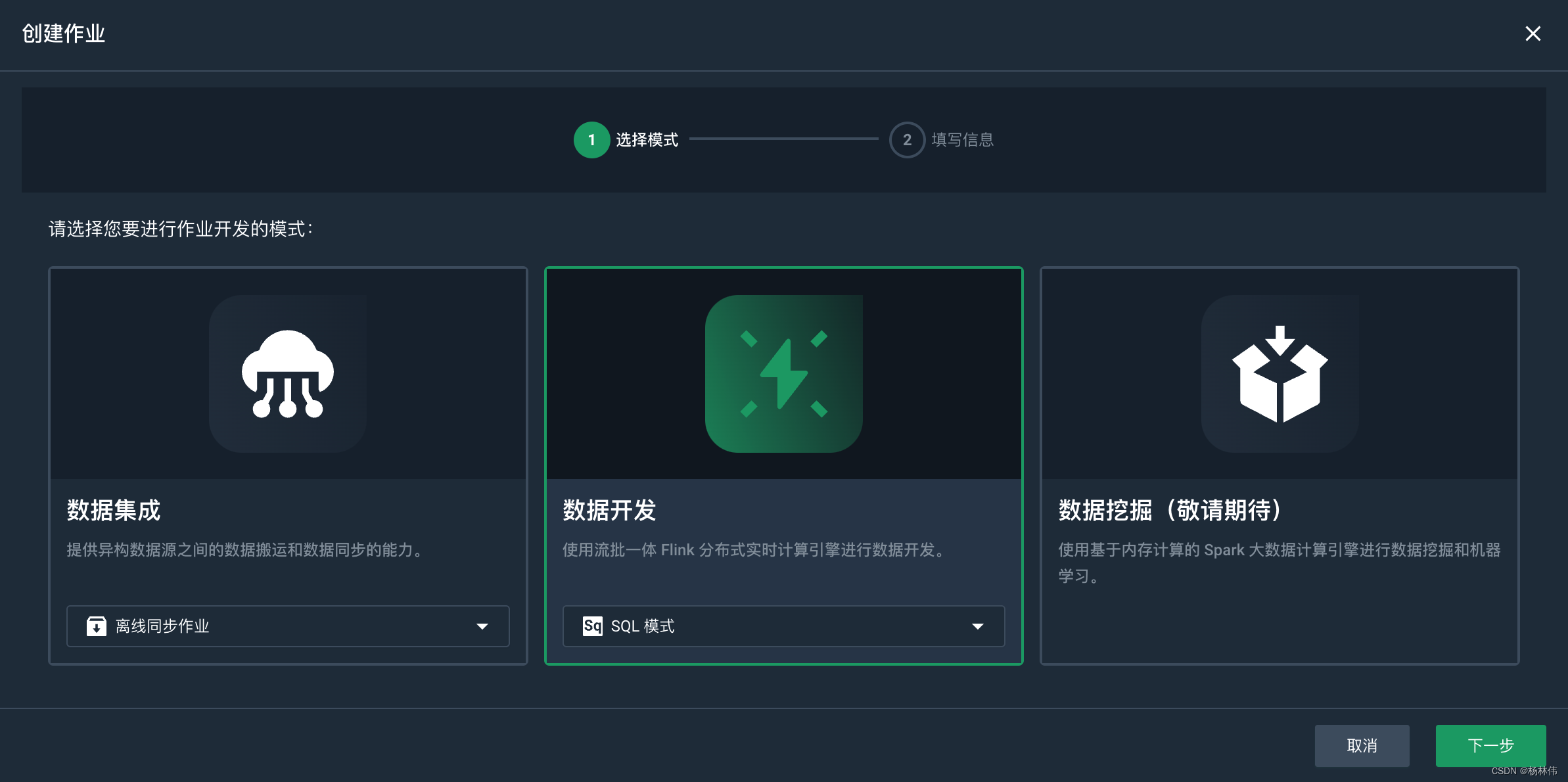
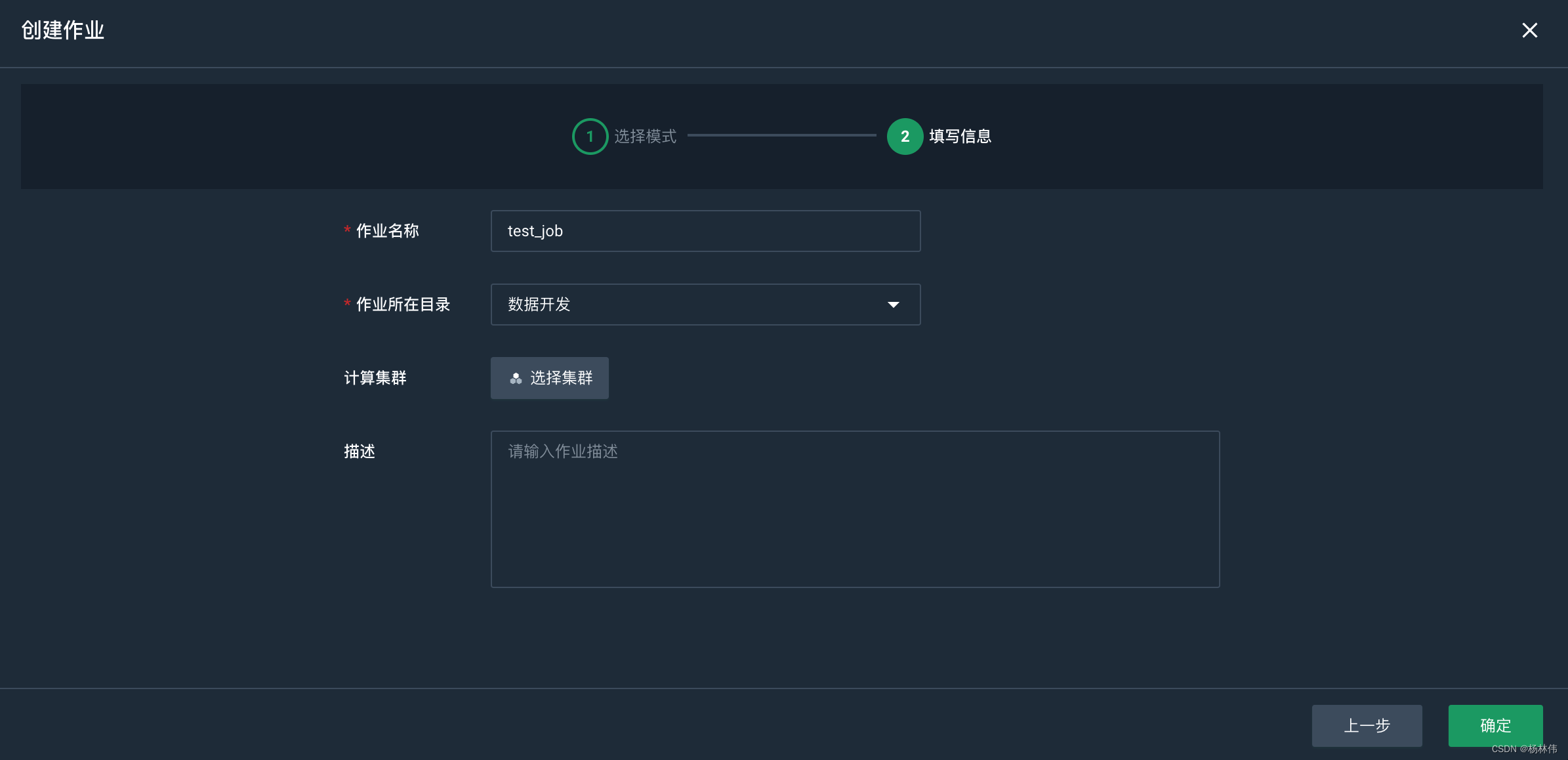
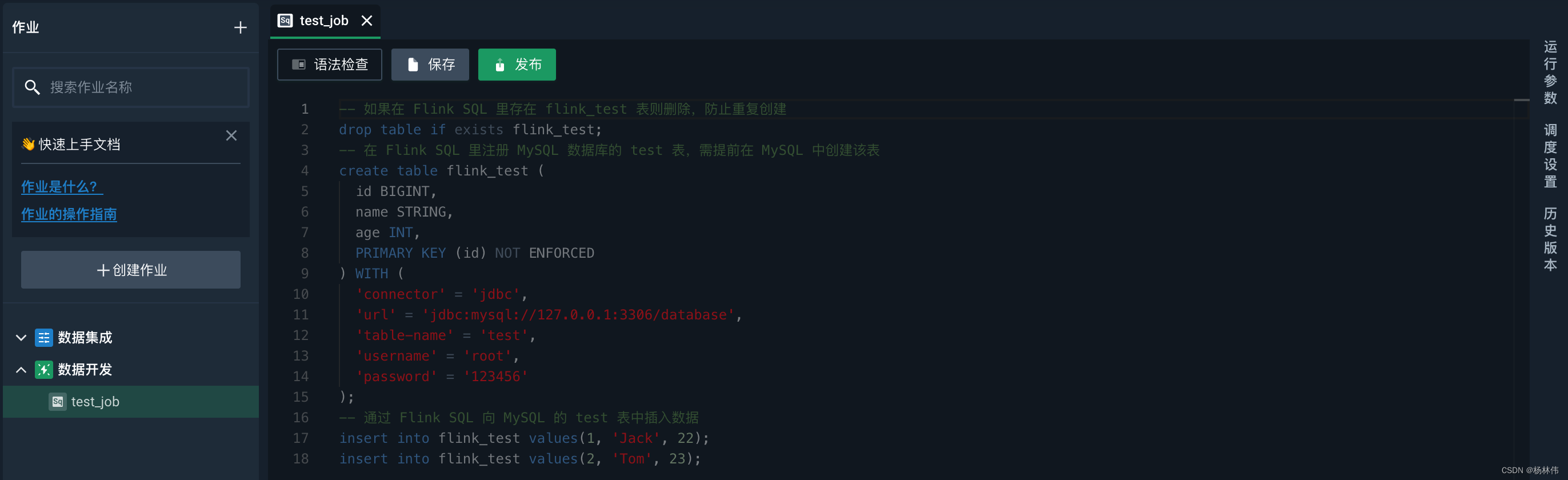

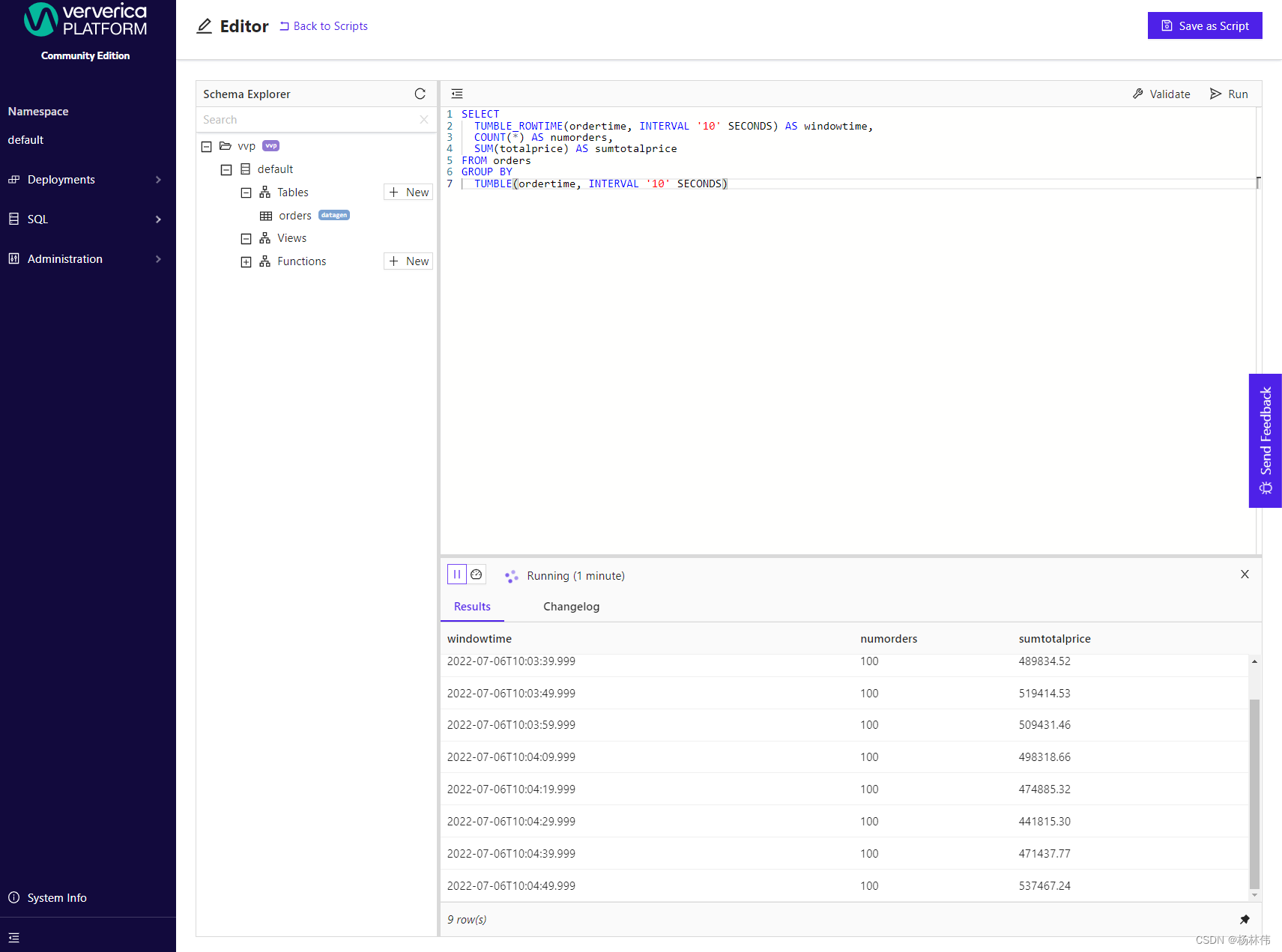
3.5 ververica
操作文档:https://docs.ververica.com/getting_started/index.html
04 文末
本文主要讲解了实时计算的一些概念、实时计算的Flink技术实现、实时计算的解决方案参考,希望能帮助到大家,谢谢大家的阅读,本文完!
-
相关阅读:
k8s学习笔记一(搭建&部署helloworld应用)
协程: Flow 异步流 /
docker 笔记11: Docker容器监控之CAdvisor+InfluxDB+Granfana
Redis使用ZSET实现消息队列使用总结一
0基础学习PyFlink——用户自定义函数之UDAF
[管理与领导-120]:IT基层管理 - 决策者和管理者的灵活变通与执著坚持的平衡
【Python报错】Python安装模块时报错Fatal error in launcher
【扩散模型】4、Improved DDPM | 引入可学习方差和余弦加噪机制来提升 DDPM
SpringMVC完整版详解
IS31FL3737B 通用12×12 LED驱动器 I2C 42mA 40QFN
- 原文地址:https://blog.csdn.net/qq_20042935/article/details/126739285