-
Kafka分布式发布订阅消息系统
🙆♂️博主:发量不足
欢迎来到本博主主页逛逛
链接:发量不足的博客_CSDN博客https://blog.csdn.net/m0_57781407?type=blog
目录
Kafka 是一个高吞吐量的分布式发布订阅消息系统,它在实时计算系统中有着非常强大的功能。
Kafka 是一个高吞吐量的分布式发布订阅消息系统,它在实时计算系统中有着非常强大的功能。
Kafka的基础知识
一、消息传递模式简介
大数据系统面临的首要困难是海量数据之间该如何进行传输。
Kafka、RabbitMQ、ActiveMQ等,Kafka 是专门为分布式高吞吐量系统而设计开发的,它非常适合在海量数据集的应用程序中进行清息传递。
消息传递的两种模式:
①、点对点消息传递模式:消息是通过一个虚拟通道进行传递的,
生产 者发送一条数据,消息将持久化到一个队列中,此时将有一个或者 多个消费者会消费队列中 的数据,但是-条消息只能被消费次,并 且消费后的消息会从消息队列中删除。(总结:有多个消费者同时消费数据,数据都可以被有序处理)
②、发布订阅消息传递模式:发布订阅模式可以有多种不同的订阅者,发布者发布的消息会被持久化到一个主题中,与点对点模式不同的是,订阅者可以订阅一个或多个主题,订阅者可以读取该主题中的所有数据,同一条数据可以被多个订阅者消费,数据被消费后也不会立即删除。
二、Kafka简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,它使用Scala和Java语言编写,是一个基于Zookeeper系统的分布式发布订阅消息系统,该项目的设计初衷是为实时数据提供一个统一、高通量、低等待的消息传递平台。
①、Kafka的众多优点:其优点具体:
(1)解耦。Kafka 具备消息系统的优点,只要生产者和消费者数据两端遵循接口约束,就可以自行扩展或修改数据处理的业务过程。
(2)高吞吐量、低延迟。即使在非常廉价的机器上,Kafka也能做到每秒处理几十万条消息,而它的延迟最低只有几毫秒。
(3)持久性。Kafka 可以将消息直接持久化在普通磁盘上,且磁盘读写性能优异。
(4)扩展性。Kafka 集群支持热扩展,Kafka集群启动运行后,用户可以直接向集群添加新的Kafka服务。
(5)容错性。Kafka 会将数据备份到多台服务器节点中,即使Kafka集群中的某台节点宕机,也不会影响整个系统的功能。
(6)支持多种客户端语言。Kafka 支持Java.. NET .PHP、Python等多种语言。
Kafka使用消费组(Consumer Group)的概念统了点对点消息传递模式和发布订阅消息传递模式,当Kafka使用点对点模式时,它可以将待处理的工作任务平均分配给消费组。
Kafka工作原理
Kafka集群是由生产者(Producer)、消息代理服务器(Brroler Serber)、消费者(Consumer)组成的。
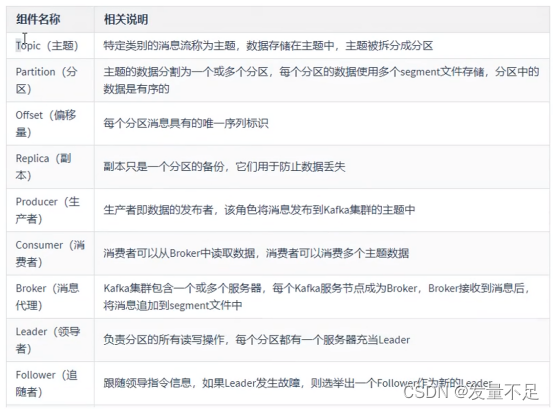
一、Kafka核心组件介绍
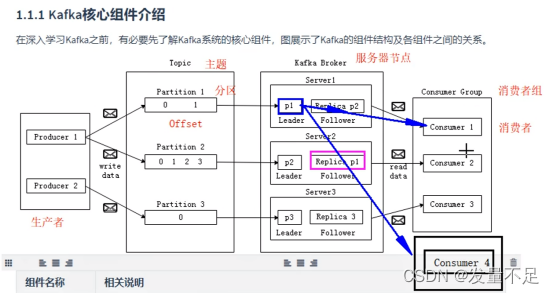
二、Kafka工作流程分析
Kafka的工作流程主要是生产者生产消息过程和消费者消费消息过程
- 、生产者生产消息过程:
最终主题的数据保存在Broker中,一个主题可以有多个分区,在物理节点上,每个分区 对应一个文件夹,该文件夹中存储的是当前分区的所有消息和索引文件。Kafka 针对每个 分区数据可以进行备份操作(在server. poperties配置文件中设置delault. rplicationfactor),若没有分区备份,一且Broker发生故障,其所有的分区数据都不会被消费。
Kafka分区策略:
Kafka默认的分区策略有3点,其一是如果在发消息的时候指定了分区,则消息发送到指定的分区中;其二是如果没有指定分区,但消息的Key不为空,则基于Key的哈希值来逸择一个分区:其三是如果既没有指定分区,且消息的Key值为空,则用轮询的方式选择一个分区。分区不仅可以方便地在集群中扩展,还可以提高并发读取消息的能力。
- 、消费者消费消息过程:
消息的消费模型有两种:推送模型(Push)和拉取模型(Pull)
基于推送模型的消息系统,是由消息代理记录消费者的消费状态,消息代理将消息数据推送给消费者后,就标记这条消息被消费了,如果此时消费者由于网络抖动或者宕机等原因造成消息数据丢失,这对于数据准确性要求高的业务来说后果是非常严重的。
消息发送速率是由Broker决定的,其目标是尽可能以最快的速度传递消息,但这样很容易造成网络阻塞。
Kafka采用拉取模型,由消费者记录消费状态,根据主题、Zookeeper集群地址和要消费消息的偏移量,每个消费者互相独立地按顺序读取每个分区的消息。
Kafka采用拉取模型的消费方式,可简化消息代理的设计,消费者可自主控制消费消息的速事以及消费万式(批量消费、逐条消费),同时还能选择不同的提交方式从而实现不同的传输语义。
小提示:
拉取模型也有缺虑如果Kafka集群申没有数据,消费者可能会陷入循环中,一直等待 消息到达,为了避免这种情况,可以在consumer. properties设置参数,允许消费者请求在等待数据到达的“长轮询”中进行阻塞(并且可选择等待到达给定的字节数,以确保传输数据的大小。
-
相关阅读:
torch.hub 记录
创建SpringBoot项目四种方式
Linux中Locate命令查找不全
NLP Step by Step -- How to use pipeline
中电金信:技术实践|Flink维度表关联方案解析
java上传文件到指定服务器
Vue引入Echarts图表的使用
新闻资讯|基于微信小程序的经济新闻资讯系统设计与实现(源码+数据库+文档)
《MySQL技术内幕-InnoDB存储引擎》总结
【11.2】【VP】Codeforces Round #728 (Div. 2)
- 原文地址:https://blog.csdn.net/m0_57781407/article/details/126800549