-
postgres源码解析 缓冲池管理器--1
背景
缓冲区管理器管理共享内存和持久存储之间的数据传输,对 DBMS 的性能产生重大影响。 PostgreSQL也不例外,良好缓冲区管理可减少对磁盘的IO操作。
Shared buffer pool 管理
参考The Internals of PostgreSQL Buffer Manager
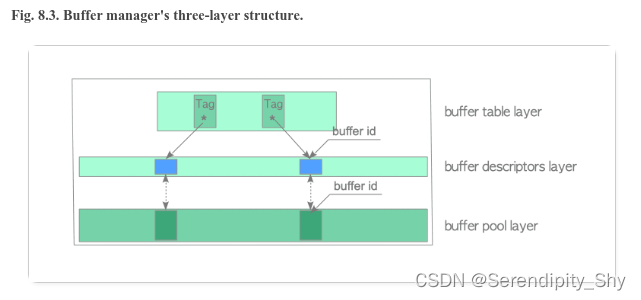
postgres 缓冲池管理分为三个层级结构,包括缓冲池表、缓冲区描述符和缓冲池,其中
每个缓冲区描述符对应缓冲池中的一个缓冲区。共享缓冲池处于共享内存区域,在系统启动时
调用 InitBufferPool函数会对共享缓冲池进行初始化。在共享缓冲池管理中,使用全局数组BufferDescriptors管理缓冲池中的缓冲区,其数组元素为BufferDesc,数组元素个数为NBuffers
[默认为1000]。该元素是一个描述符结构体,记录相应缓冲池的状态信息1 缓冲区描述符 BufferDesc
/* * BufferDesc -- shared descriptor/state data for a single shared buffer. typedef struct BufferDesc { BufferTag tag; /* ID of page contained in buffer */ int buf_id; /* buffer's index number (from 0) */ //数组下标 /* state of the tag, containing flags, refcount and usagecount */ pg_atomic_uint32 state; // 状态信息 int wait_backend_pid; /* backend PID of pin-count waiter */ int freeNext; /* link in freelist chain */ //空闲链表的链接 LWLock content_lock; /* to lock access to buffer contents */ } BufferDesc;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
其中 BufferTag记录了该缓冲区对应的物理数据页信息,比如什么文件[普通表、FSM或VM],数据页在文件中的偏移量,即块号等;
/* * Buffer tag identifies which disk block the buffer contains. * * Note: the BufferTag data must be sufficient to determine where to write the * block, without reference to pg_class or pg_tablespace entries. It's * possible that the backend flushing the buffer doesn't even believe the * relation is visible yet (its xact may have started before the xact that * created the rel). The storage manager must be able to cope anyway. * * BufferTag的设计目的的是为了加速确定写入块号,无需引用系统表信息。 * * Note: if there's any pad bytes in the struct, INIT_BUFFERTAG will have * to be fixed to zero them, since this struct is used as a hash key. */ typedef struct buftag { RelFileNode rnode; /* physical relation identifier */ ForkNumber forkNum; BlockNumber blockNum; /* blknum relative to begin of reln */ } BufferTag; 与BufferTag相关的操作: clear + init + equal #define CLEAR_BUFFERTAG(a) \ ( \ (a).rnode.spcNode = InvalidOid, \ (a).rnode.dbNode = InvalidOid, \ (a).rnode.relNode = InvalidOid, \ (a).forkNum = InvalidForkNumber, \ (a).blockNum = InvalidBlockNumber \ ) #define INIT_BUFFERTAG(a,xx_rnode,xx_forkNum,xx_blockNum) \ ( \ (a).rnode = (xx_rnode), \ (a).forkNum = (xx_forkNum), \ (a).blockNum = (xx_blockNum) \ ) #define BUFFERTAGS_EQUAL(a,b) \ ( \ RelFileNodeEquals((a).rnode, (b).rnode) && \ (a).blockNum == (b).blockNum && \ (a).forkNum == (b).forkNum \ )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
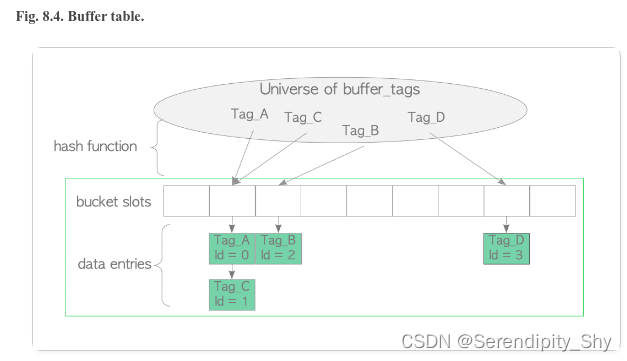
2 Buffer Table 缓冲池表层
为进一步加速获取数据页面所对应的缓冲区,采用hash table通过Tag信息 + 哈希函数实现。在初始化过程会在共享内存中
创建与之对应的hash表。由于Tag标识为缓冲块对应数据页的 物理信息,具有唯一性,在查找的时候以其为hash key,
查询哈希表返回数据页对应的缓冲区在缓冲池数组中的位置。
缓冲池层
缓冲池是一个缓冲槽数组,每一个缓冲槽存放了从磁盘文件读取的数据或者是即将刷盘的脏数据。缓冲槽大小为8KB,
与数据页大小相等,即一个槽对应一个数据页。缓冲池的初始化
void InitBufferPool(void) { bool foundBufs, foundDescs, foundIOCV, foundBufCkpt; /* Align descriptors to a cacheline boundary. */ BufferDescriptors = (BufferDescPadded *) // 申请缓冲池描述符数组 ShmemInitStruct("Buffer Descriptors", NBuffers * sizeof(BufferDescPadded), &foundDescs); BufferBlocks = (char *) // 申请缓冲块 ShmemInitStruct("Buffer Blocks", NBuffers * (Size) BLCKSZ, &foundBufs); /* Align condition variables to cacheline boundary. */ BufferIOCVArray = (ConditionVariableMinimallyPadded *) ShmemInitStruct("Buffer IO Condition Variables", NBuffers * sizeof(ConditionVariableMinimallyPadded), &foundIOCV); /* * The array used to sort to-be-checkpointed buffer ids is located in * shared memory, to avoid having to allocate significant amounts of * memory at runtime. As that'd be in the middle of a checkpoint, or when * the checkpointer is restarted, memory allocation failures would be * painful. */ //申请CkptBufferIds,用于检查点排序刷脏使用,避免在运行是分配,其目的是防止检查点意外重启 // 内存分配失败 CkptBufferIds = (CkptSortItem *) ShmemInitStruct("Checkpoint BufferIds", NBuffers * sizeof(CkptSortItem), &foundBufCkpt); if (foundDescs || foundBufs || foundIOCV || foundBufCkpt) { /* should find all of these, or none of them */ Assert(foundDescs && foundBufs && foundIOCV && foundBufCkpt); /* note: this path is only taken in EXEC_BACKEND case */ } else { int i; /* * Initialize all the buffer headers. */ for (i = 0; i < NBuffers; i++) { BufferDesc *buf = GetBufferDescriptor(i); // 分配bufferDesc CLEAR_BUFFERTAG(buf->tag); pg_atomic_init_u32(&buf->state, 0); // 初始化 state信息 buf->wait_backend_pid = 0; // buf->buf_id = i; /* * Initially link all the buffers together as unused. Subsequent * management of this list is done by freelist.c. */ buf->freeNext = i + 1; LWLockInitialize(BufferDescriptorGetContentLock(buf), LWTRANCHE_BUFFER_CONTENT); ConditionVariableInit(BufferDescriptorGetIOCV(buf)); } /* Correct last entry of linked list */ // GetBufferDescriptor(NBuffers - 1)->freeNext = FREENEXT_END_OF_LIST; } /* Init other shared buffer-management stuff */ StrategyInitialize(!foundDescs); // 这里初始化hash表和访问策略 /* Initialize per-backend file flush context */ // 初始化会写上下文 WritebackContextInit(&BackendWritebackContext, &backend_flush_after); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
-
相关阅读:
coding持续集成
JDK、JRE、JVM 三者关系
项目管理软件应该具备哪些功能
伐木猪小游戏
Postman 教程使用详解:如何安装和使用 Postman 进行 API 测试
Auto.js脚本程序打包
第27天:安全开发-PHP应用&TP框架&路由访问&对象操作&内置过滤绕过&核心漏洞
6.英语的十六种时态(三面旗):主动、被动、肯定、否定、一般疑问句、特殊疑问句。
少儿编程 电子学会图形化编程等级考试Scratch三级真题解析(选择题)2022年6月
MIPS汇编语言学习-01-两数求和以及环境配置、如何运行
- 原文地址:https://blog.csdn.net/qq_52668274/article/details/126752413
