-
Python科学计算库练习题
1.1python概述
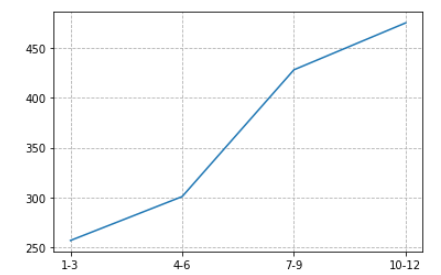
案例一:Matplotlib图表初体验
import matplotlib.pyplot as plt x=["1-3","4-6","7-9","10-12"] #设置X轴数值 y=[257,301,428,475] #设置Y轴数值 plt.plot(x,y) #绘制折线图 plt.grid(True, linestyle='--', alpha=1) #添加网格线 plt.show() #展示- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.2Numpy数据计算
案例一:一维数组的创建、索引及切片
任务说明:
(1)NumPy提供的array函数可以创建一维数组或多维数组。使用array函数把如下图示的员工的年龄创建为一维数组
(2)使用数组的索引,分别获取“Mary”和“LiLi”的年龄
(3)对数组进行分割,同时获取“Mary”和“LiLi”的年龄、“LiLi”和“Cendy”的年龄以及“Mary”和“Cendy”的年龄代码实现:
#(1)创建出数组 import numpy as np score=np.array([["Mary",22,95.5],["LiLi",23,56],["Cendy",22,90]]) score #(2)对数据进行切片(先行后列) score[:2,1] #(3)数组分割- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
案例二:Numpy常用的函数
任务说明:
(1)算术函数
使用NumPy 算术函数add()、subtract()、multiply()、divide()实现如下两个数组之间的加减乘除。代码实现:
import numpy as np n1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) n2 = np.array([1, 2, 3]) # 一维数组 n3=np.add(n1,n2) n4=np.subtract(n1,n2) n5=np.divide(n1,n2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2)排序函数
import numpy as np dt = np.dtype([('name',"S10"),('age',int),('KPI',int)]) n1=np.array([('Mary', 22, 95.5), ('LiLi', 23, 56), ('Cendy', 22, 90)],dtype = dt) n1.sort(axis=0,order="KPI") n1- 1
- 2
- 3
- 4
- 5
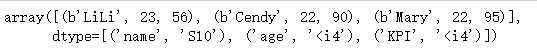
1.3Pandas数据分析
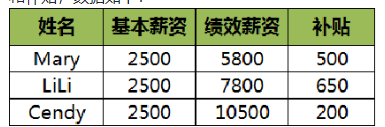
案例一:创建DataFrame)对象
任务说明:以员工薪资构成为例,其包含基本薪资、绩效薪资和补贴,数据如下:
代码实现:
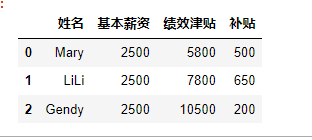
import pandas as pd data=[['Mary',"2500","5800","500"],["LiLi","2500","7800","650"],["Gendy","2500","10500","200"]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df- 1
- 2
- 3
- 4
- 5
import numpy as np arr = np.array([4, 7, 1, 6, 1, 8, 4, 9, 1, 6]) arr1=np.unique(arr) arr1 #array([1, 4, 6, 7, 8, 9])- 1
- 2
- 3
- 4
- 5
- 6
案例二: 数据抽取、增加、修改及删除
任务说明:
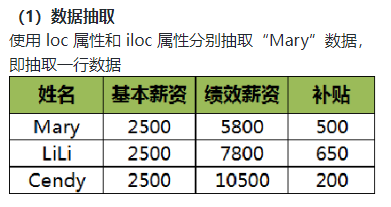
代码实现:
#(1)使用loc属性和iloc属性抽取第一行数据 import pandas as pd data=[['Mary',"2500","5800","500"],["LiLi","2500","7800","650"],["Gendy","2500","10500","200"]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.loc[0]- 1
- 2
- 3
- 4
- 5
- 6

#(2)增加奖金列方式一:直接赋值法 import pandas as pd data=[['Mary',"2500","5800","500"],["LiLi","2500","7800","650"],["Gendy","2500","10500","200"]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df['奖金']=['122','222','333'] df- 1
- 2
- 3
- 4
- 5
- 6
- 7
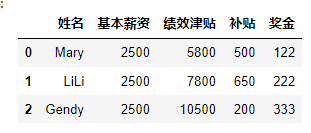
#(2)增加奖金列方式二:loc属性法 import pandas as pd data=[['Mary',"2500","5800","500"],["LiLi","2500","7800","650"],["Gendy","2500","10500","200"]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.loc[:,'奖金']=['122','222','333'] df- 1
- 2
- 3
- 4
- 5
- 6
#(2)增加奖金列方式三:指定位置插入 import pandas as pd data=[['Mary',"2500","5800","500"],["LiLi","2500","7800","650"],["Gendy","2500","10500","200"]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.insert(loc=2, column='奖金', value=100) # 在最后一列后,插入值全为3的c列 df- 1
- 2
- 3
- 4
- 5
- 6
- 7
#(3)增加行数据:在指定行,加入指定数据 import pandas as pd data=[['Mary',"2500","5800","500"],["LiLi","2500","7800","650"],["Gendy","2500","10500","200"]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.insert(loc=2, column='奖金', value=100) # 在最后一列后,插入值全为3的c列 df.loc[3]=['Alice','1000','1000','1000','100'] df- 1
- 2
- 3
- 4
- 5
- 6
- 7
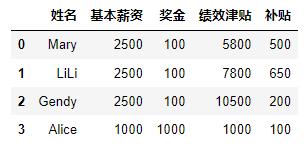
(3)增加多行数据 import pandas as pd data=[['Mary',"2500","5800","500"],["LiLi","2500","7800","650"],["Gendy","2500","10500","200"]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.insert(loc=2, column='奖金', value=100) # 在最后一列后,插入值全为3的c列 df.loc[3]=['Alice','1000','1000','1000','100'] # 在指定行添加数据 data1=[['Liming',"2500","5800","500"],["LiLi1","2500","7800","650"],["Gendy1","2500","10500","200"]] df1=pd.DataFrame(data1,columns=['姓名','基本薪资','绩效津贴','补贴']) df1 df.append(df1,ignore_index=True)#让索引重写进行排序- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
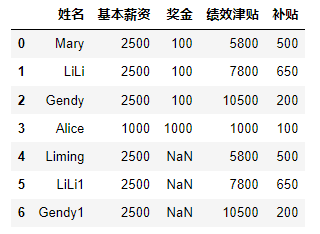
案例三:数据缺失值处理
任务说明:
1)删除缺失值
使用 dropna 函数删除含有缺失值的行2)填充缺失值
DataFrame 对象中的 fillna 函数可以实现填充缺失数据代码实现:
#(1)查看缺失值 import pandas as pd df = pd.read_csv('property-data.csv') df.info()- 1
- 2
- 3
- 4
- 5
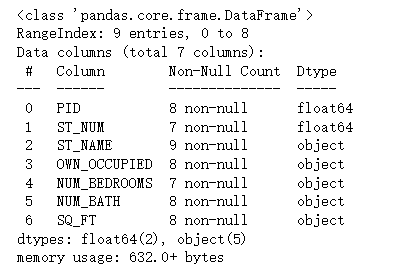
#(2)删除含有缺失值的行 import pandas as pd df = pd.read_csv('property-data.csv') new_df=df.dropna() new_df- 1
- 2
- 3
- 4
- 5
- 6
默认情况下,dropna() 方法返回一个新的 DataFrame,不会修改源数据。
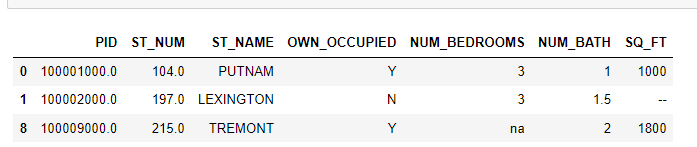
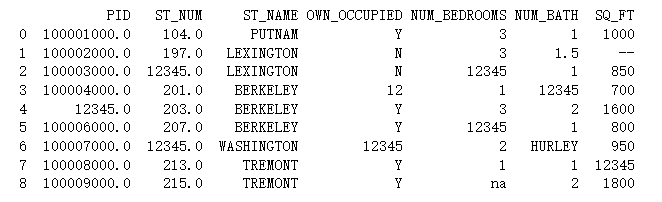
#(3)对空值进行填充替代 import pandas as pd df = pd.read_csv('property-data.csv') df.fillna(12345, inplace = True) print(df.to_string())- 1
- 2
- 3
- 4
- 5
- 6
案例四:数据的计算函数
任务说明:
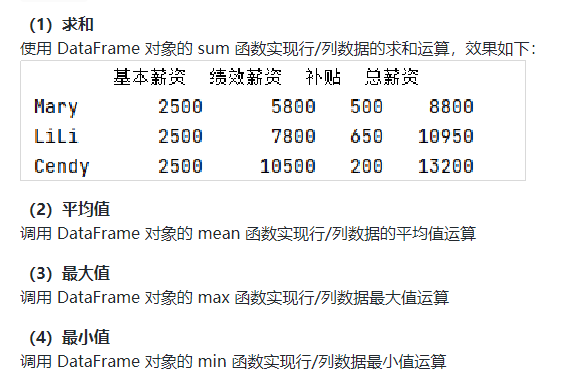
代码实现:
#(1)任务1:使用 DataFrame 对象的 sum 函数实现行/列数据的求和运算,效果如下: import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df['奖金']=['122','222','333'] df.loc[:,'总薪资']=df.sum(axis=1) df- 1
- 2
- 3
- 4
- 5
- 6
- 7
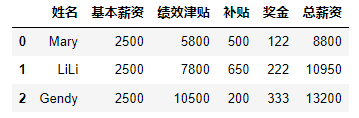
#(2)任务2:每行的平均数 import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df['奖金']=['122','222','333'] df.loc[:,'总薪资']=df.mean(axis=1) df- 1
- 2
- 3
- 4
- 5
- 6
- 7
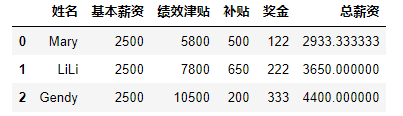
#该行最大值 import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df['奖金']=['122','222','333'] df.loc[:,'总薪资']=df.max(axis=1) df #该行最小值 import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df['奖金']=['122','222','333'] df.loc[:,'总薪资']=df.max(axis=0) df- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
下面的内容为每一列的求和与计算:
import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.loc[3]=df.iloc[:,1:5].max(axis=0)#求每一列的最大值 df- 1
- 2
- 3
- 4
- 5
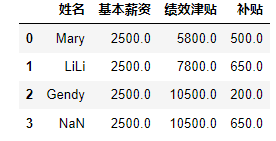
import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.loc[3]=df.iloc[:,1:5].mean(axis=0)#求出每一列的平均值 df- 1
- 2
- 3
- 4
- 5
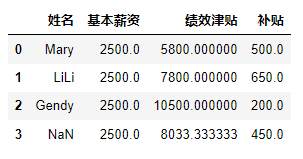
import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.loc[3]=df.iloc[:,1:5].min(axis=0)#求出每一列的最小值 df- 1
- 2
- 3
- 4
- 5
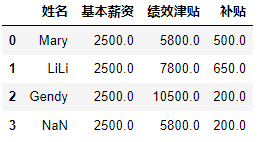
import pandas as pd data=[['Mary',2500,5800,500],["LiLi",2500,7800,650],["Gendy",2500,10500,200]] df=pd.DataFrame(data,columns=['姓名','基本薪资','绩效津贴','补贴']) df.loc[3]=df.iloc[:,1:5].sum(axis=0) #求出每一列的和 df- 1
- 2
- 3
- 4
- 5
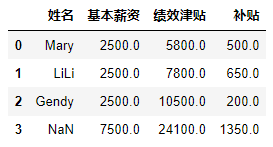
1.4Matplotlib数据可视化
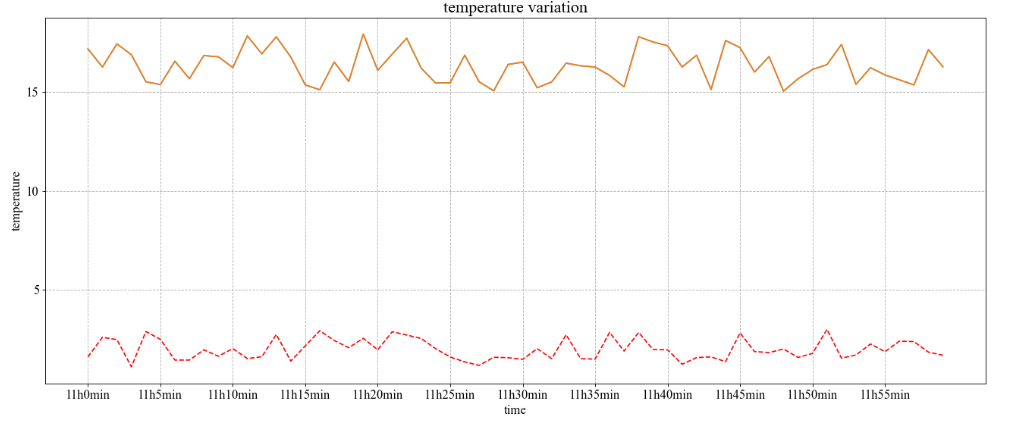
import matplotlib.pyplot as plt import random # 画出温度变化图 # 0.准备x, y坐标的数据 x = range(60) y_shanghai = [random.uniform(15, 18) for i in x] # 创建画布 plt.figure(figsize=(20, 8), dpi=80) # 绘制折线图 plt.plot(x, y_shanghai) #添加网格 plt.grid(True, linestyle='--', alpha=1) # 构造x轴刻度标签 x_ticks_label = ["11h{}min".format(i) for i in x] # 构造y轴刻度 y_ticks = range(40) # 修改x,y轴坐标的刻度显示 plt.xticks(x[::5], x_ticks_label[::5]) plt.yticks(y_ticks[::5]) # 增加北京的温度数据 y_beijing = [random.uniform(1, 3) for i in x] # 绘制折线图 plt.plot(x, y_shanghai) # 使用多次plot可以画多个折线 plt.plot(x, y_beijing, color='r', linestyle='--') plt.xlabel("time") plt.ylabel("temperature") plt.title("temperature variation", fontsize=20) # 显示图像 plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
-
相关阅读:
数据库-多表查询-子查询
错误记录:从把项目从Tomcat8.5.37转到Tomcat10.1.7
Outlook无需API开发连接钉钉群机器人,实现新增会议日程自动发送群消息通知
【C语言经典100例题-68】有n个整数,使其前面各数顺序向后移m个位置,最后m个数变成最前面的m个数
DRY 原则—Don‘t Repeat Yourself, 不要重复
GCC编译器
智能护栏碰撞监测系统:强化道路安全的智能守卫
pytest脚本常用的执行命令
java计算机毕业设计springboot+vue南天在线求助系统
Unity动态创建Avatar骨骼映射
- 原文地址:https://blog.csdn.net/m0_58022371/article/details/126798551