-
Pandas的DataFrame & Series【详解】
Pandas数据结构
1.Series
2.DataFrame
3.从DataFrame中查询出SeriesDataFrame: 二维数据、整个表格、多行多列
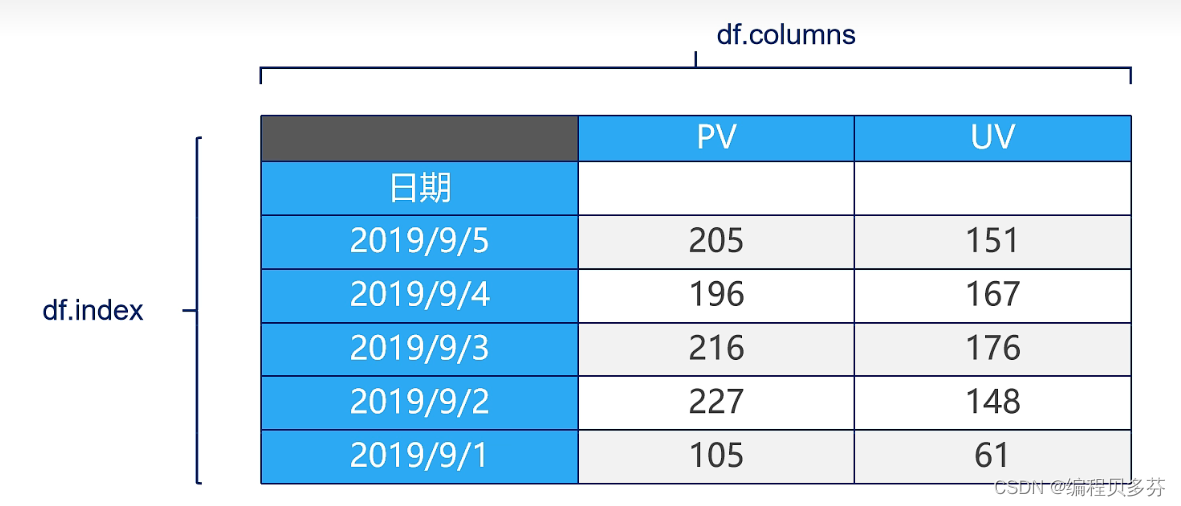
Series:一维数据,一行或者一列

- import pandas as pd
- import numpy as np
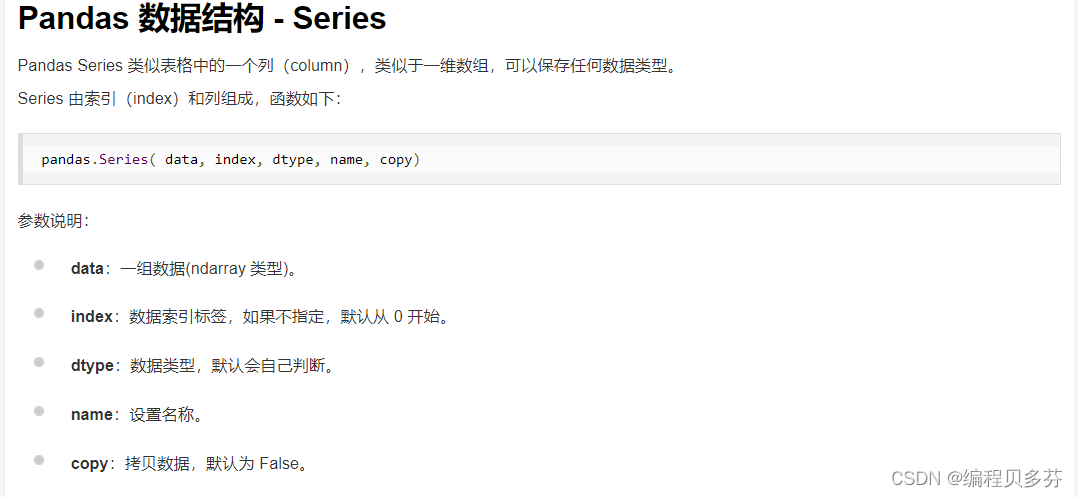
1、Series
Series是一种类似于一维数组的对象,它由一组数据〈不同数据类型)以及一组与之相关的数据标签(即索引)组成。
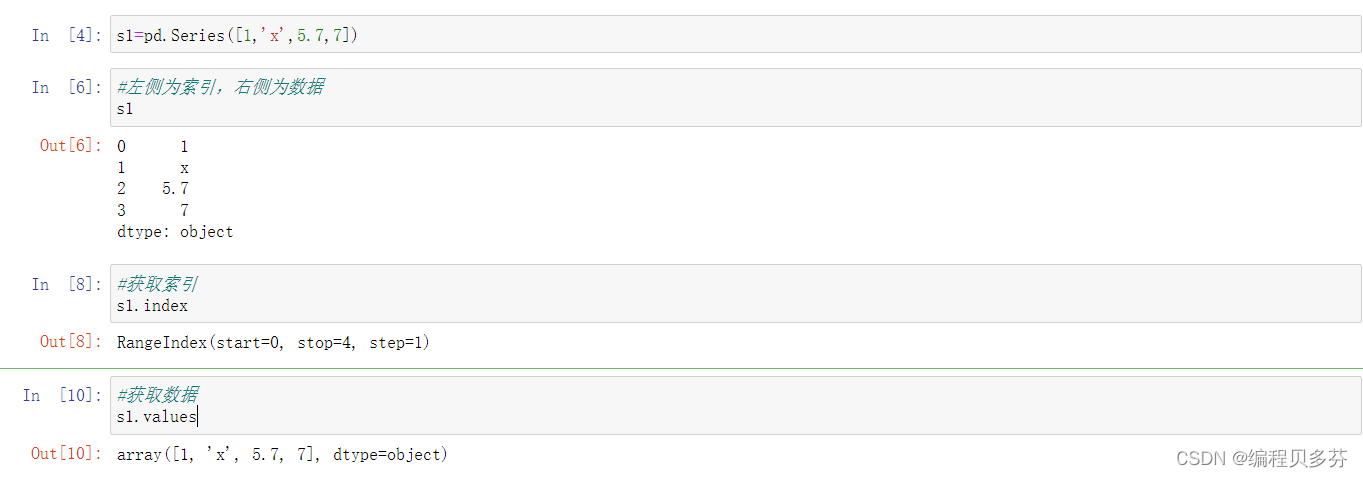
1.1仅有数据列表即可产生最简单的Series
左侧为索引,右侧为数据
- s1=pd.Series([1,'x',5.7,7])
- #左侧为索引,右侧为数据
- s1
获取索引
s1.index- 获取索引
- s1.index
获取数据
s1.values- #获取数据
- s1.values
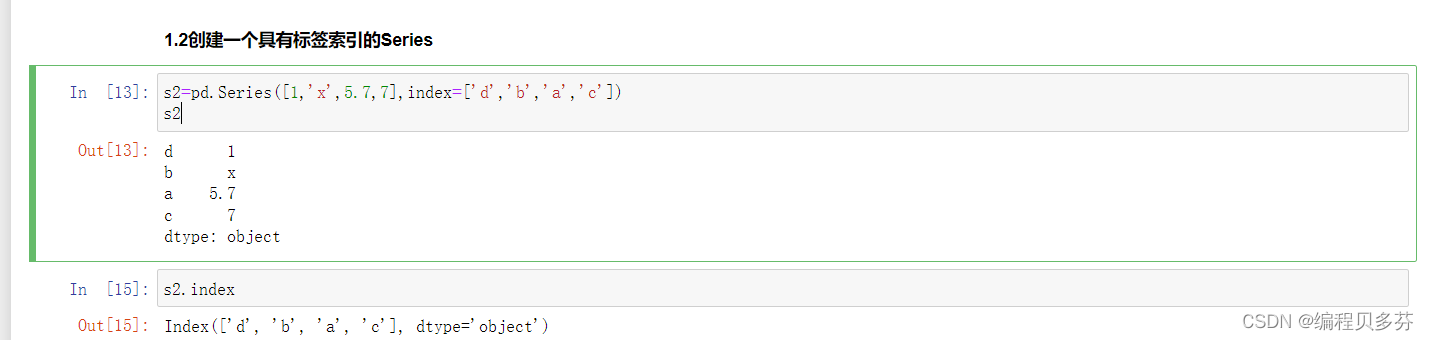
1.2创建一个具有标签索引的Series
- s2=pd.Series([1,'x',5.7,7],index=['d','b','a','c'])
- s2
- s2.index
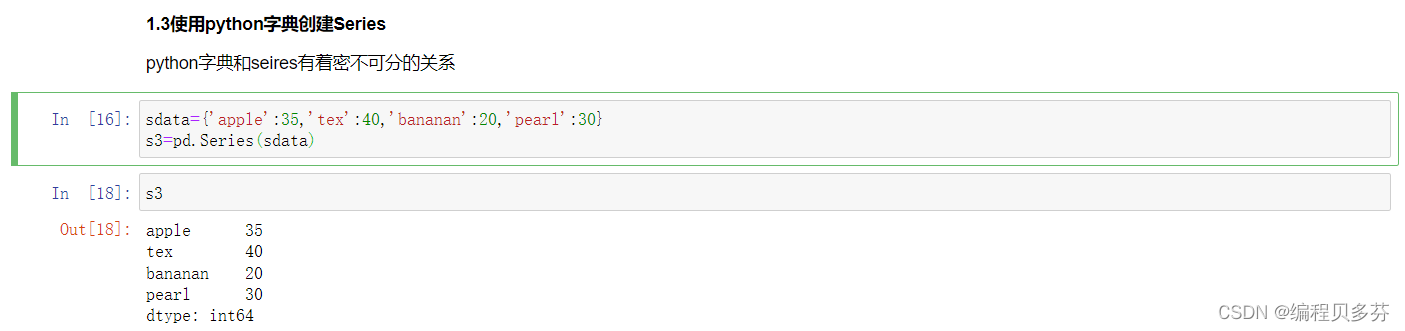
1.3使用python字典创建Series
python字典和seires有着密不可分的关系
- sdata={'apple':35,'tex':40,'bananan':20,'pearl':30}
- s3=pd.Series(sdata)
- s3
1.4根据标签索引查询数据
----类似pthon的字典dict
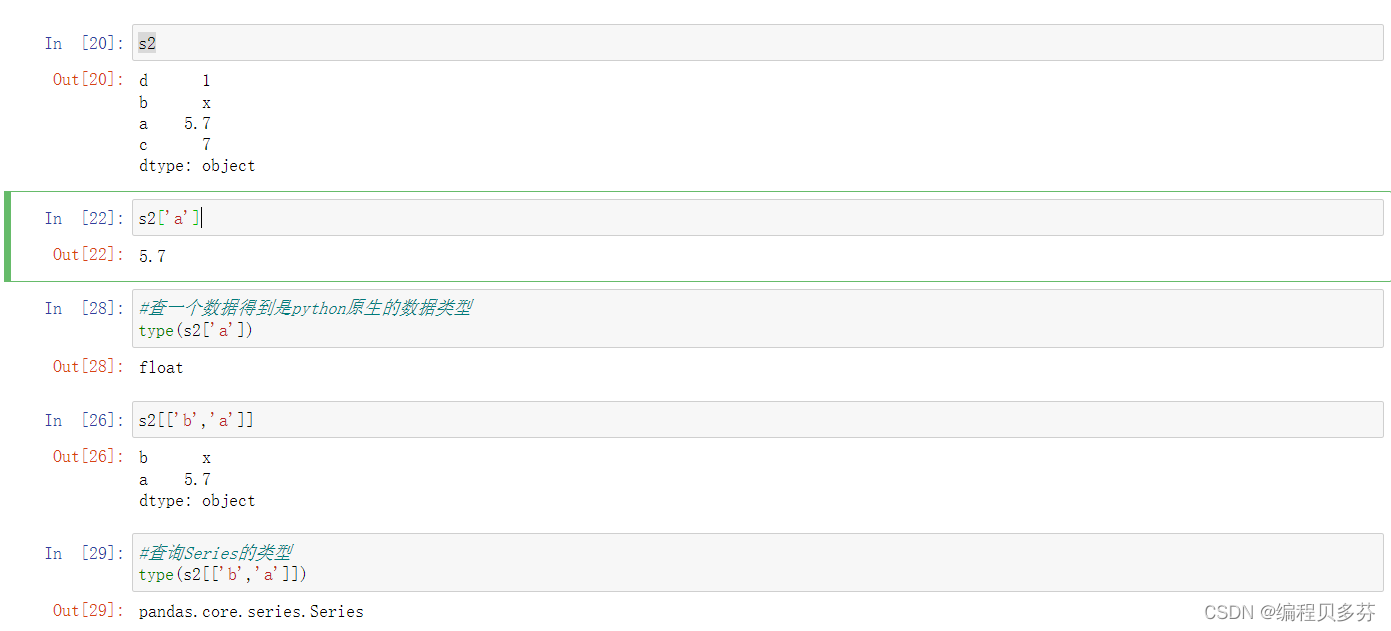
- s2
- s2['a']
查一个数据得到是python原生的数据类型
- #查一个数据得到是python原生的数据类型
- type(s2['a'])
- s2[['b','a']]
查询Series的类型 type(s2[['b','a']])
- #查询Series的类型
- type(s2[['b','a']])
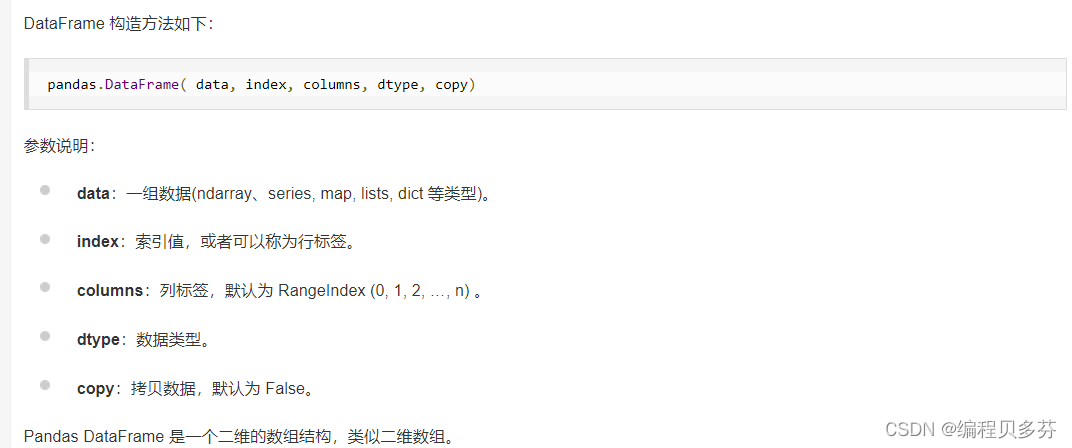
2.DataFrame
DataFrame是一个表格型的数据结构¶
①每列可以是不同的值类型(数值、字符串、布尔值等)
②既有行索引index,也有列索引columns
③可以被看做由Series组成的字典
④创建dataframe最常用的方法,见读取纯文本文件、excel、mysql数据库2.1根据多个字典序列创建dataframe
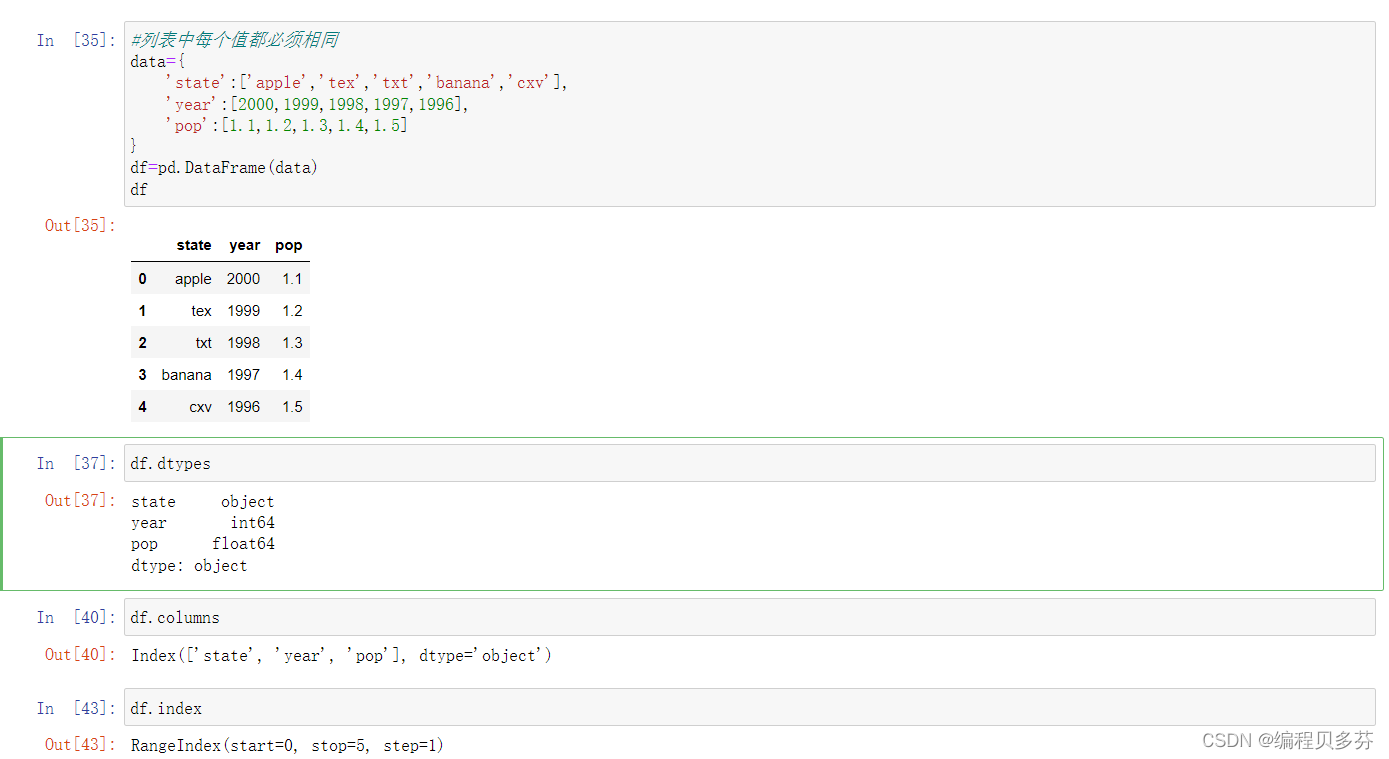
列表中每个值的个数都必须相同
- #列表中每个值都必须相同
- data={
- 'state':['apple','tex','txt','banana','cxv'],
- 'year':[2000,1999,1998,1997,1996],
- 'pop':[1.1,1.2,1.3,1.4,1.5]
- }
- df=pd.DataFrame(data)
- df
- df.dtypes
- df.columns
- df.index
3.从DataFrame中查询出Series
如果只查询一列,一行,返回的是pd.Series
如果查询多行、多列,返回的是pd.DataFramedf
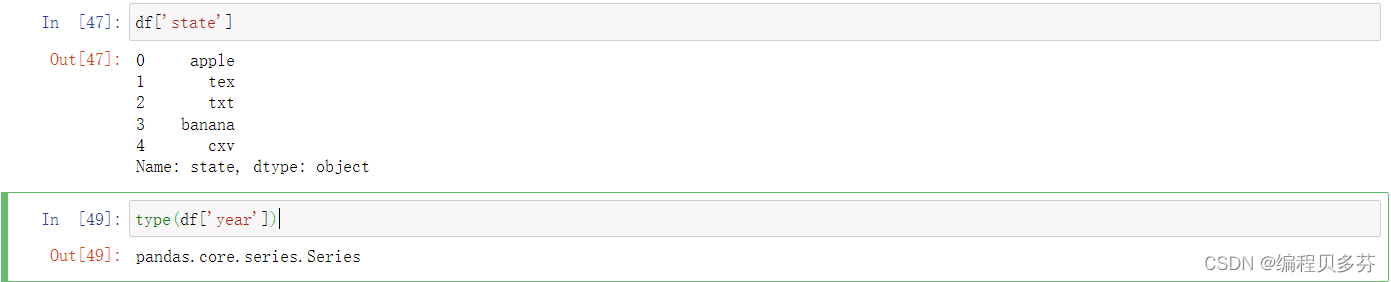
3.1查询一列,结果是一个pd.Series
- df['state']
- type(df['year'])
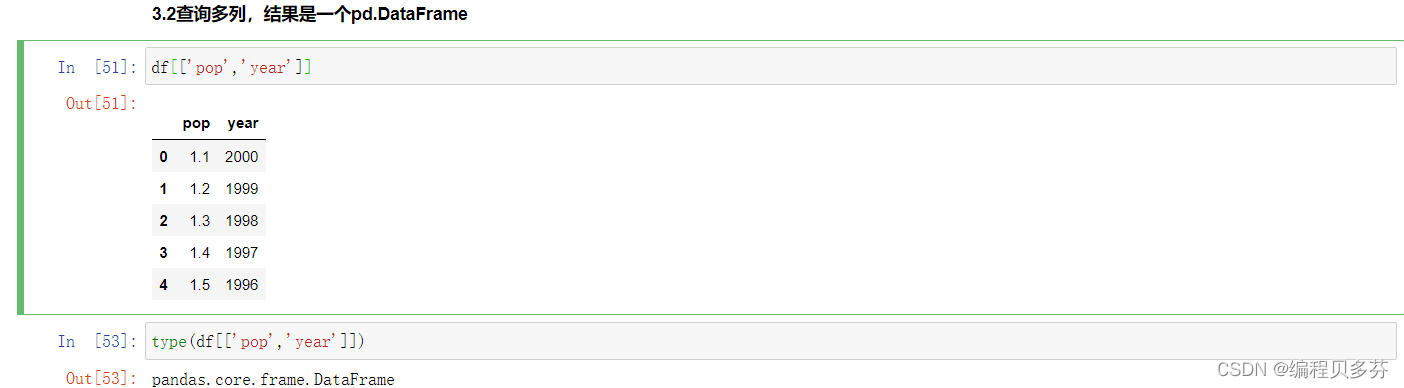
3.2查询多列,结果是一个pd.DataFrame
- df[['pop','year']]
- type(df[['pop','year']])
3.3查询一行,结果是一个pd.Series
loc(1)代表查询一行
- df.loc[1]
- type(df.loc[1])
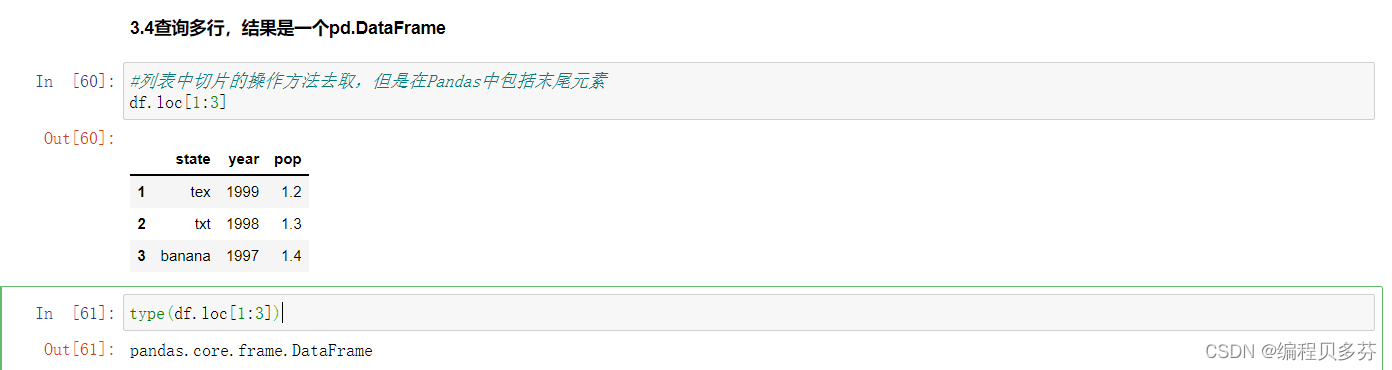
3.4查询多行,结果是一个pd.DataFrame
列表中切片的操作方法去取,但是在Pandas中包括末尾元素
- #列表中切片的操作方法去取,但是在Pandas中包括末尾元素
- df.loc[1:3]
- type(df.loc[1:3])
总结:
-
相关阅读:
Iptables官方教程-学习笔记5
E4991B 阻抗分析仪,1 MHz 至 500 MHz/1 GHz/3 GHz
80W美团架构师整理分享出了Spring5企业级开发实战文档
数据库选型参考
WR | 水源水耐药基因稳定赋存的关键:以致病菌为“源”,群落构建主导菌为“汇”...
设计模式(八)组合
GlusterFs分布式文件系统
无人机倾斜摄影测量技术标准及关键技术研究
RDMA概览
远程发送剪切板,屏幕截图
- 原文地址:https://blog.csdn.net/qq_46044325/article/details/126797541