-
数据排序 归并排序,计数排序以及快速排序的三路优化
数据排序 归并排序,计数排序以及快速排序的三路优化
之前的排序算法讲解: 部分排序算法讲解_sleepymonstergod的博客-CSDN博客

1.归并排序
在开始归并排序之前,我们先进行一个和归并排序类似思想的题目
21. 合并两个有序链表

思路:两个链表的节点一一对比,将数值小的放于新的升序链表中,然后依次进行该操作.
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){ struct ListNode* tmp1=list1; struct ListNode* tmp2=list2; struct ListNode*guard=(struct ListNode*)malloc(sizeof(struct ListNode)); guard->next=NULL; struct ListNode*tmp=guard; if(list1==NULL) { return list2; } if(list2==NULL) { return list1; } while(tmp1 && tmp2) { if(tmp1->val>tmp2->val) { tmp->next=tmp2; tmp2=tmp2->next; } else { tmp->next=tmp1; tmp1=tmp1->next; } tmp=tmp->next; } if(tmp1) { tmp->next=tmp1; } if(tmp2) { tmp->next=tmp2; } tmp=guard->next; free(guard); return tmp; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
归并排序也是这种思想
归并排序思路:
先分解
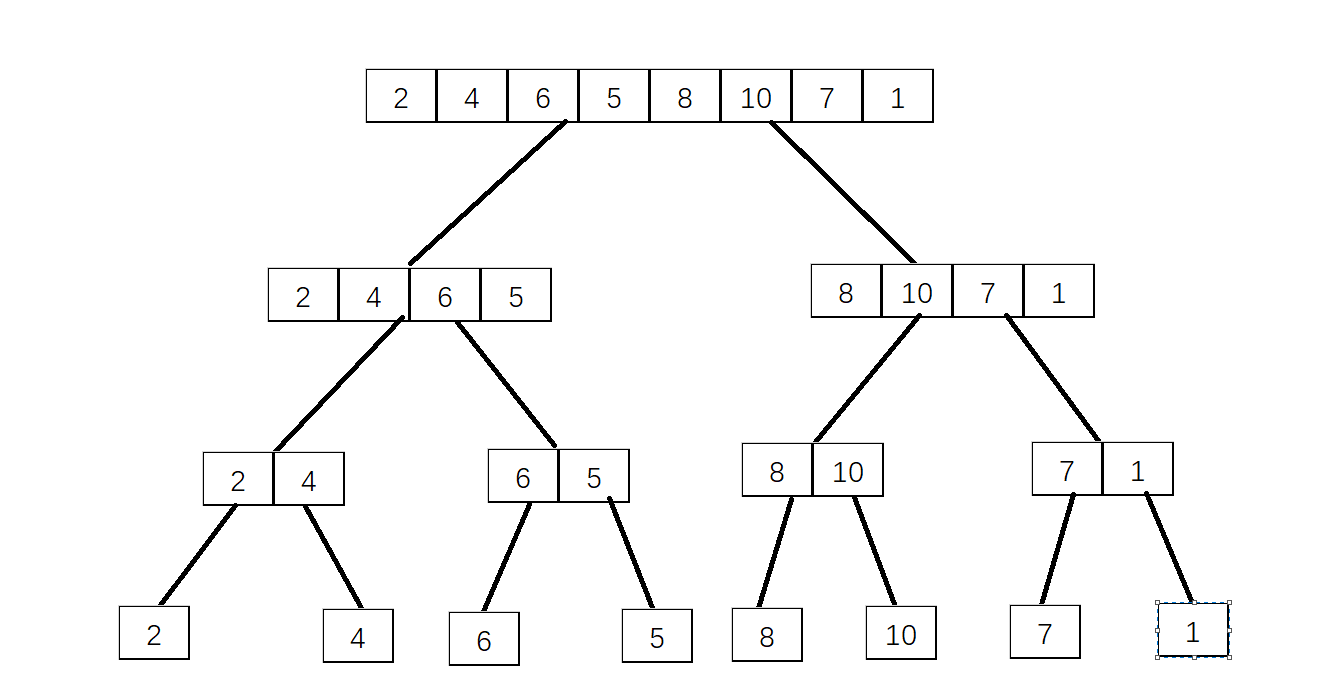
后合并
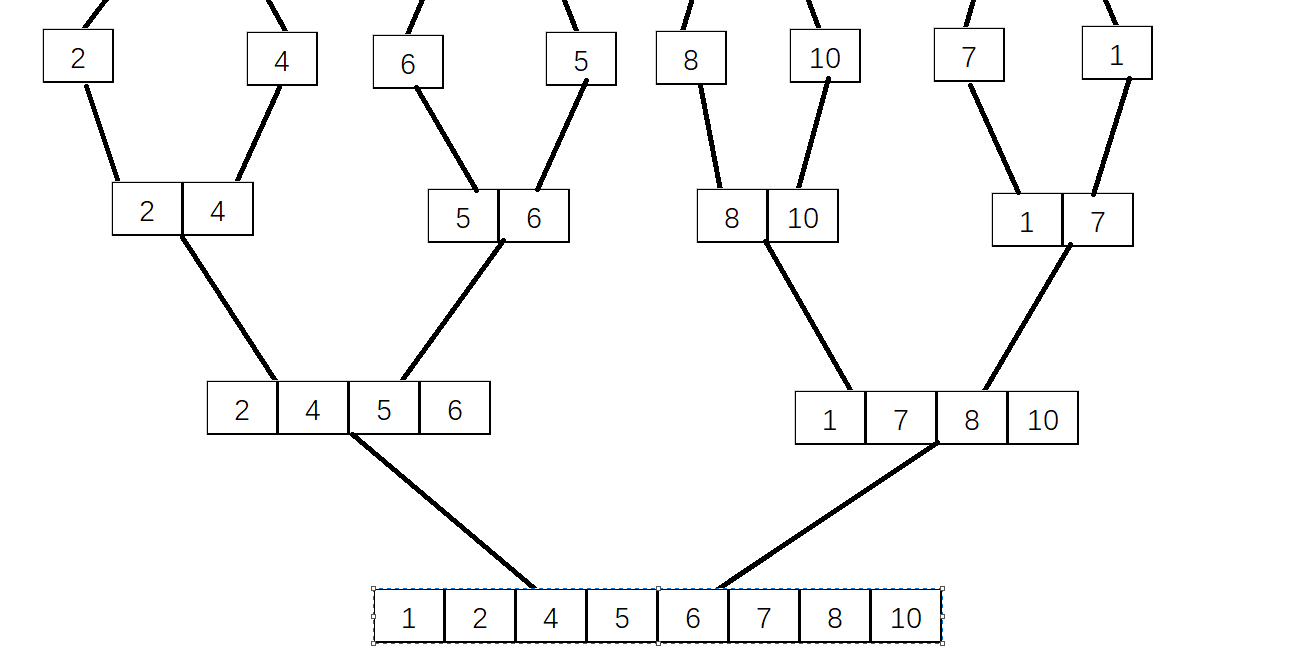
归并排序的核心思想是分治,我们需要将一个完整的数组先进行拆分,随后合并,合并的过程其实就是交换索引内容的过程,该过程中可以找到很多逆序对,在解决逆序对问题时可以考虑归并排序。
在合并过程中,不需要两边数据个数一样,只要两边都存在就可以.
归并排序在排序过程中,需要一个额外的数组tmp来进行合并操作,不推荐直接在原数组修改,会出现bug,且操作复杂.
归并排序实现
void _MergeSort(int* a, int begin, int end, int* tmp) { if (begin >= end) { return; } int mid = (end - begin) / 2 + begin; _MergeSort(a, begin, mid, tmp); _MergeSort(a, mid+1, end, tmp); int begin1 = begin, end1 = mid; int begin2 = mid + 1, end2 = end; int i = begin; while (begin1<=end1&&begin2<=end2) { if (a[begin1] <= a[begin2]) { tmp[i++] = a[begin1++]; } else { tmp[i++] = a[begin2++]; } } while(begin1 <= end1) { tmp[i++] = a[begin1++]; } while (begin2 <= end2) { tmp[i++] = a[begin2++]; } memcpy(a+begin,tmp+begin,sizeof(int)*(end-begin+1)); } void MergeSort(int* a, int n) { int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("malloc fail"); exit(-1); } _MergeSort(a,0,n-1,tmp); free(tmp); tmp = NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
归并排序的非递归实现
当归并排序非递归实现时,直接使用gap=1,gap=2,gap=4…来实现归并排序.
在使用时需要注意边界问题(边界处理情况在代码注释中解释)
代码实现
void MergeSortNonR(int* a, int n) { int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("malloc fail"); exit(-1); } int gap = 1; while (gap<n) { for (int j = 0; j < n; j += 2 * gap) { int begin1 = j, end1 = j + gap - 1; int begin2 = j + gap, end2 = j + 2 * gap - 1; int i = j; int begin = begin1; int end = end2; if (end1 >= n) { break; }//当end1越界时,即剩下一组数据,直接停止归并,因为后面没有归并的数据 if (begin2 >= n) { break; }//当begin2越界时,即剩下一组数据,直接停止归并,因为后面没有归并的数据 if (end2 >= n) { end2 = n - 1; end = end2; }//当end2越界时,说明剩下两组数据,需要进行归并,将end2的值改为n-1可以保证不越界 while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] <= a[begin2]) { tmp[i++] = a[begin1++]; } else { tmp[i++] = a[begin2++]; } } while (begin1 <= end1) { tmp[i++] = a[begin1++]; } while (begin2 <= end2) { tmp[i++] = a[begin2++]; } memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1)); } gap *= 2; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
2.计数排序
计数排序是非比较类排序算法,当数据比较集中时,使用计数排序会有很高的时间效率
实现原理 统计数组中各个数字出现的次数,再依据次数,按照一定的排序要求进行排序.
实现代码
此处,该代码只能排序20以内的数字.
void CountSort(int* a, int n) { int* tmp = (int*)calloc(20,sizeof(int)); int i = 0; for ( i = 0; i < n; i++) { tmp[a[i]]++; } i = 0; int loc = 0; while (i < 20) { if (tmp[i] == 0) { i++; } else { a[loc++] = i; tmp[i]--; } } free(tmp); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3.快速排序的三路优化
当数据中重复数据比较多时,快速排序的时间复杂度就会达到o(n^2),时间效率极低 ,例如
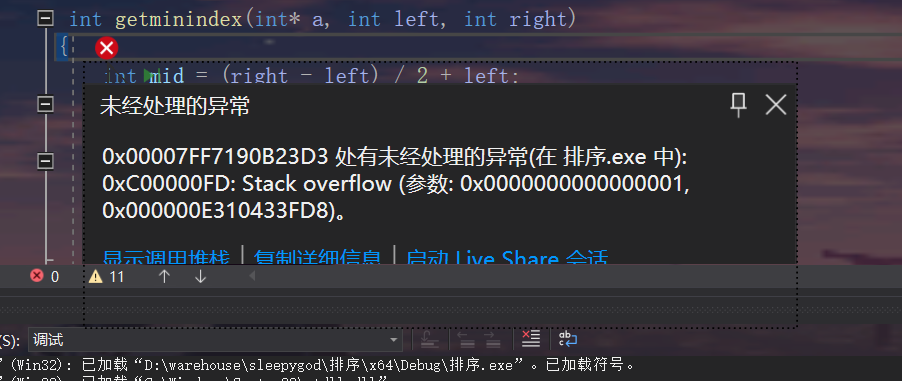
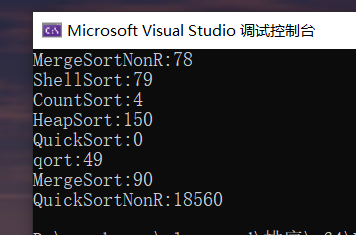
第一次运行100w个20以内的数排序,快速排序直接爆栈.
第二次运行未快速排序递归方式参与,非递归的时间效率极低.
所以在此处,我们将对最开始的快速排序进行一些优化.此处选用三路优化的方法
实现模拟图:
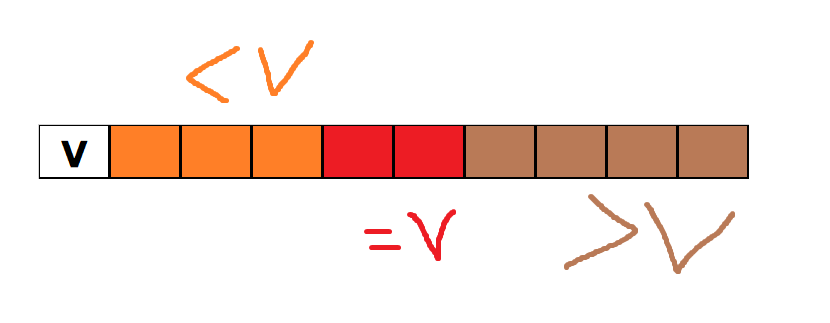
之前快速排序是分为小于等于v和大于等于v两部分,现在我们将其分为三个部分小于等于和大于,等于的部分不在参与后续排序过程,此处大大的提高了时间效率.
代码实现
void swap(int* a, int* b) { int tmp = *a; *a = *b; *b = tmp; } void InsertSort(int* a, int n) { //[0,end]有序 for (int i = 0; i <n-1; i++) { int end = i; int tmp = a[end + 1]; while (end >= 0) { if (tmp < a[end]) { a[end + 1] = a[end]; end--; } else { break; } } a[end + 1] = tmp; } } int getminindex(int* a, int left, int right) { int mid = (right - left) / 2 + left; if (a[mid] > a[left]) { if (a[mid] <= a[right]) { return mid; } else//a[mid]>a[right] { if (a[right] > a[left]) { return right; } else { return left; } } } else //a[mid]<=a[left] { if (a[mid] >= a[right]) { return mid; } else //a[mid]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
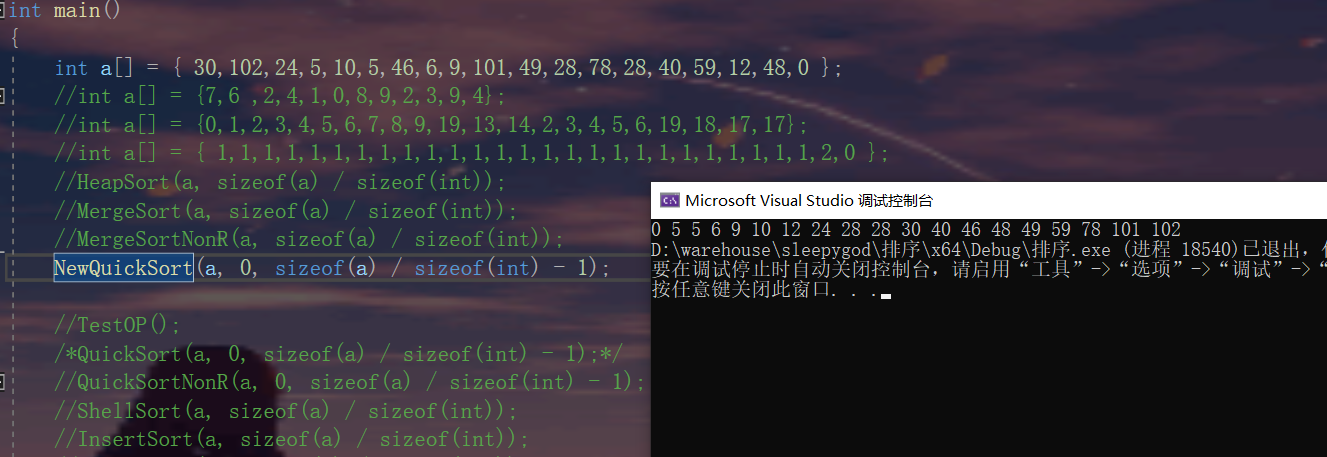
100w个随机数
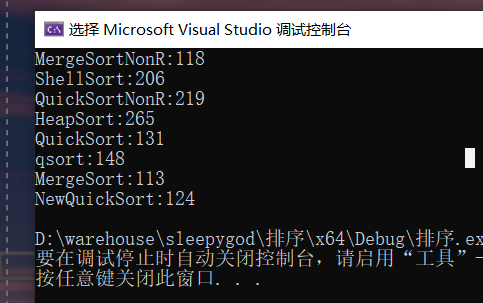
100w个20以内的数 快速排序递归形式会爆栈,此处不再运行
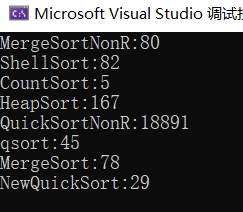
1000w个随机数
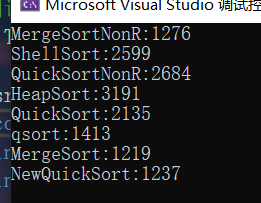
100w个20以内的数 快速排序递归形式会爆栈,此处不再运行
1000w个随机数
1000w个20以内的数
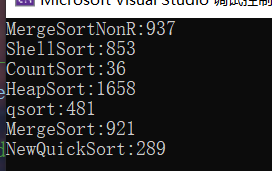
优化后的快速排序,当重复数字较多时,效率会很高,都在一般情况下,效率会比一般的快速排序低一点,但平均下来,我会更推荐三路优化版本,综合性能会超过普通版本的快速排序.
-
相关阅读:
《数据在外设中的存储》
命令解压aar、文件压缩成aar图文详解
RISC-V 架构寄存器规范
SpringBoot电商项目实战Day7 堆
Llama 3.1论文中文对照翻译
主播产品话术
PID学习
如何利用产品帮助中心提升用户体验
HEVC熵编码核心点介绍
Hadoop3教程(三十):(生产调优篇)纠删码
- 原文地址:https://blog.csdn.net/gemgod/article/details/126796941
