-
猿创征文|Redis新增数据类型
📃个人主页:不断前进的皮卡丘
🌞博客描述:梦想也许遥不可及,但重要的是追梦的过程,用博客记录自己的成长,记录自己一步一步向上攀登的印记
🔥个人专栏:微服务专栏Bitmaps
基本介绍
- 计算机底层以二进制存储数据
- "abc"是由3个字节组成,但是在计算机中的实际存储是以二进制来表示,"abc"分别对应的ASCII码是97,98,99
- 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。
- Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作。

命令
命令 功能 setbit 设置Bitmaps中某个偏移量的值(0或1)offset:偏移量从0开始 getbit 获取Bitmaps中某个偏移量的值 bitcount [start end] 统计字符串从start字节到end字节比特值为1的数量 bitop and(or/not/xor) [key…] bitop是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中。 操作演示
每个独立用户是否访问过网站存放在Bitmaps中, 将访问的用户记做1, 没有访问的用户记做0, 用偏移量作为用户的id。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1, 6, 11, 15, 19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图
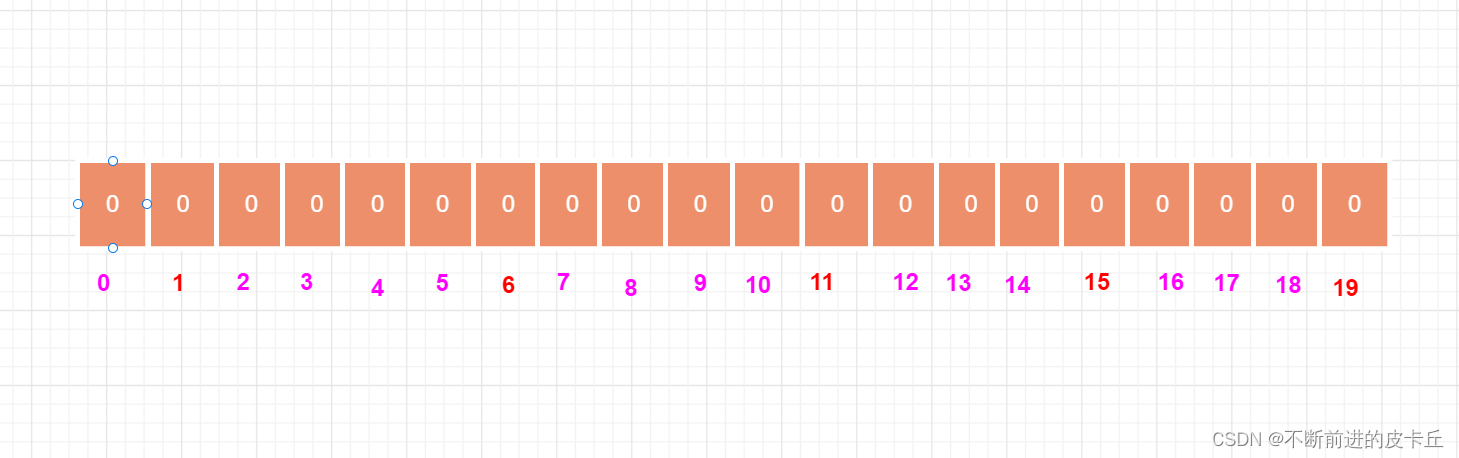
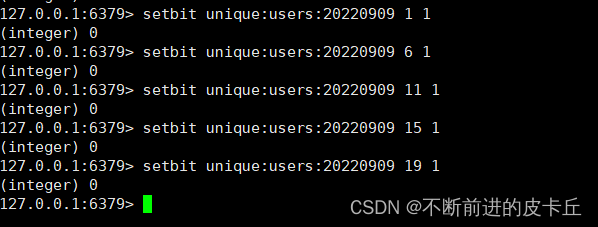
很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。


通过会对给定的整个字符串都进行计数,我们也可以通过 start 或 end 参数,只在特定的位上进行计数。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。
注意:redis的setbit设置或清除的是bit位置,而bitcount计算的是byte位置。

需要注意一点,虽然Bitmaps能够节省内存,但是并不适用所有情况。
假设网站有1000万用户,但是其中的活跃用户只有10万。此时Bitmaps存储了绝大多数的僵尸用户,但是bit位的值都是0,是无效的,只有百分之一的利用率,还是浪费了绝大部分的内存。
而如果使用map或者set存储这10万用户,可能还用不了这么多内存呢。
另外还有一种情况,统计日活数,如果用户的id是这样的:1000001、1000002、1000003等,前面存在100000这样的固定值,那么需要在存储bitmaps进行截取,以免造成内存浪费。HyperLogLog(可以用来去重)
基本介绍
✔️在实际生活中,我们很经常遇到要进行去重的操作,比如一个网址要统计访问的IP数,就需要用到去重,这样子即使是切换账号也会被发现。像这种集合中求去重后元素个数的问题就被称为是基数问题。
📖基数:比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
📖我们可以有下面几种方法来进行去重操作
1️⃣如果数据是存储在mysql里面的,我们可以使用distinct +count来计算去重后元素个数
2️⃣我们也可以使用Redis提供的hash、set、bitmaps等数据结构来处理
💢虽然上面的方法结果精确,但是随着数据的不断增加,就会导致占用空间越来越大,对于很大的数据集来说是不符合实际的。
🔥Redis推出了HyperLogLog,通过降低一定的精度来平衡存储空间
🍊Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常大时,计算基数所需的空间总是固定的、并且是很小的。
🍊在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
🍊但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。命令
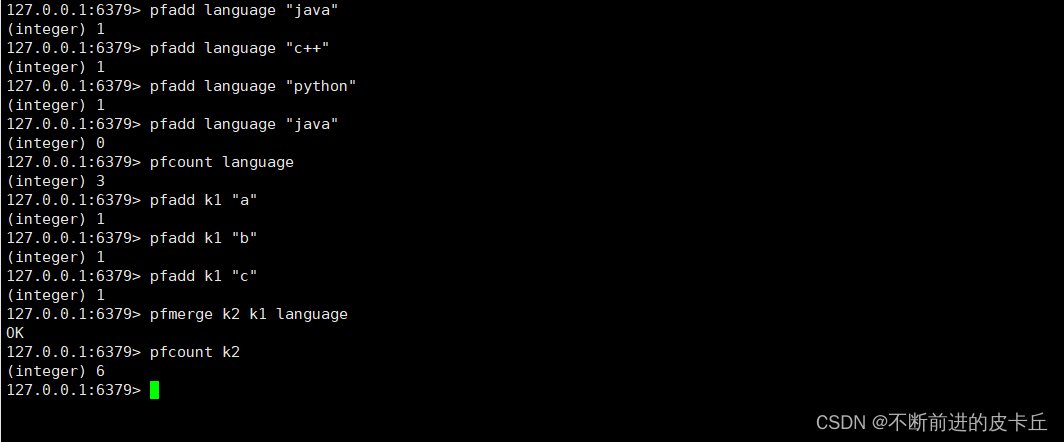
命令 功能描述 pfadd key element1 [element2]… 添加指定元素到HyperLogLog,如果执行后基数发生变化,则返回1,否则返回0 pfcount key1 [key2…] 计算HLL的基数,可以计算多个HLL,比如说用HLL存储每一天的UV,计算一周的UV(UniqueVisitor,独立访客)可以使用一周七天的UV合并计算 pfmerge destkey sourcekey1 sourcekey2… 把一个或多个HLL合并后的结果存储在另一个HLL中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得 操作演示
Geospatial
基本介绍
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
命令
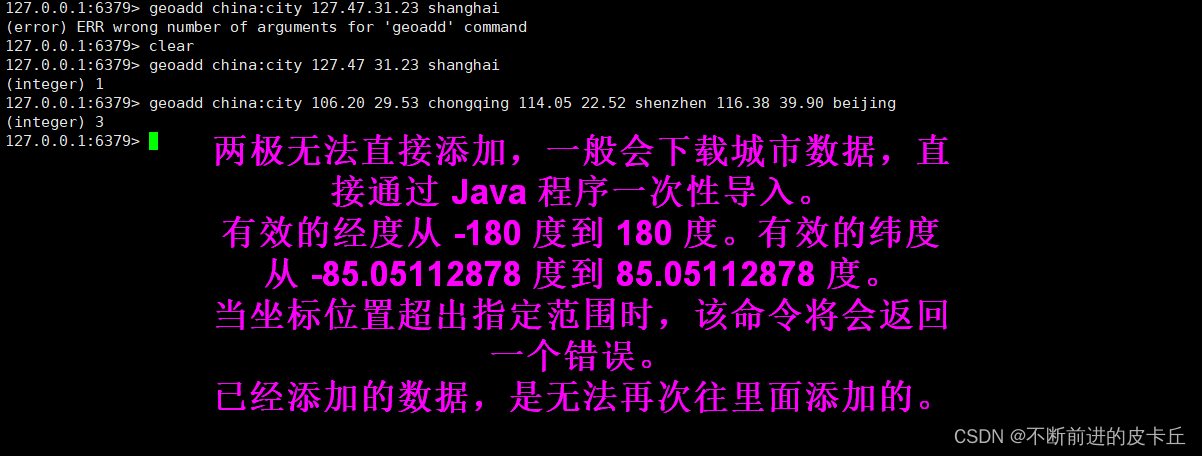
命令 功能描述 geoadd key longitude latitude member[ longitude latitude member] 添加地理位置(经度,纬度,名称) geopos key member[member…] 获得指定地区的坐标值 geodist key member1 member2[m|km|ft|mi] 获取两个位置之间的直线距离(m表示默认值为米,km表示千米,mi表示英里,ft表示英尺) georadius key longitude latitude radius m|km|ft|mi 以给定的经纬度为中心,找出某一半径内的元素 操作演示



-
相关阅读:
Maven开发环境搭建
揭秘计算机奇迹:探索I/O设备的神秘世界!
CANdb++数据库操作
GPT-4V的图片识别和分析能力
TS快速入门-函数
ref和reactive的区别?
微信小程序地图
文件上传OSS实现
横向对比 npm、pnpm、tnpm、yarn 优缺点
ChatGLM-中英对话大模型-6B试用说明
- 原文地址:https://blog.csdn.net/qq_52797170/article/details/126778346