-
OpenGL - Deferred Rendering
我们现在一直使用的光照方式叫做
正向渲染(Forward Rendering)或者正向着色法(Forward Shading),它是我们渲染物体的一种非常直接的方式,在场景中我们根据所有光源照亮一个物体,之后再渲染下一个物体,以此类推。它对程序性能的影响也很大,因为对于每一个需要渲染的物体,程序都要对每一个光源每一个需要渲染的片段进行迭代,这是非常多的!因为大部分片段着色器的输出都会被之后的输出覆盖,正向渲染还会在场景中因为高深的复杂度(多个物体重合在一个像素上)浪费大量的片段着色器运行时间。延迟着色法(Deferred Shading),或者说是延迟渲染(Deferred Rendering),为了解决上述问题而诞生了,它大幅度地改变了我们渲染物体的方式。这给我们优化拥有大量光源的场景提供了很多的选择,因为它能够在渲染上百甚至上千光源的同时还能够保持能让人接受的帧率。它包含两个处理阶段:在第一个
几何处理阶段(Geometry Pass)中,我们先渲染场景一次,之后获取对象的各种几何信息,并储存在一系列叫做G缓冲(G-buffer)的纹理中;想想位置向量(Position Vector)、颜色向量(Color Vector)、法向量(Normal Vector)和/或镜面值(Specular Value)。场景中这些储存在G缓冲中的几何信息将会在之后用来做(更复杂的)光照计算。在第二个
光照处理阶段(Lighting Pass)中使用G缓冲内的纹理数据。在光照处理阶段中,我们渲染一个屏幕大小的方形,并使用G缓冲中的几何数据对每一个片段计算场景的光照;在每个像素中我们都会对`G缓冲进行迭代。我们对于渲染过程进行解耦,将它高级的片段处理挪到后期进行,而不是直接将每个对象从顶点着色器带到片段着色器。下面这幅图片很好地展示了延迟着色法的整个过程:
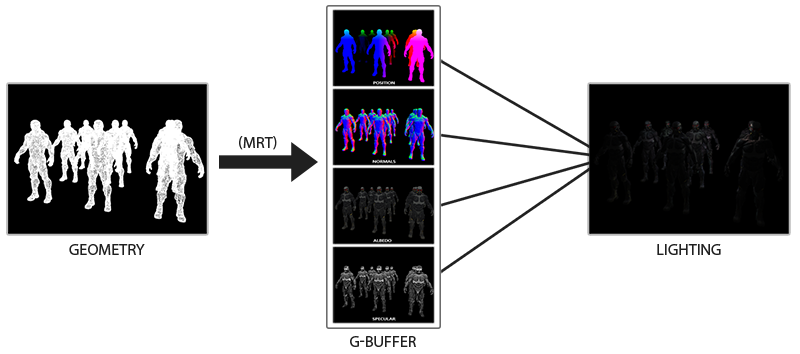
在几何处理阶段中填充G缓冲非常高效,因为我们直接储存像素位置,颜色或者是法线等对象信息到帧缓冲中,而这几乎不会消耗处理时间。在此基础上使用多渲染目标(Multiple Render Targets, MRT)技术,我们甚至可以在一个渲染处理之内完成这所有的工作。延迟着色法的其中一个缺点就是它不能进行
混合(Blending),因为G缓冲中所有的数据都是从一个单独的片段中来的,而混合需要对多个片段的组合进行操作。延迟着色法另外一个缺点就是它迫使你对大部分场景的光照使用相同的光照算法。当然延迟渲染之后仍然可以再正想渲染,但是要注意利用之前的深度缓冲。
延迟渲染一直被称赞的原因就是它能够渲染大量的光源而不消耗大量的性能。然而,延迟渲染它本身并不能支持非常大量的光源,因为我们仍然必须要对场景中每一个光源计算每一个片段的光照分量。真正让大量光源成为可能的是我们能够对延迟渲染管线引用的一个非常棒的优化:
光体积(Light Volumes)。隐藏在光体积背后的想法就是计算光源的半径,或是体积,也就是光能够到达片段的范围。由于大部分光源都使用了某种形式的
衰减(Attenuation),我们可以用它来计算光源能够到达的最大路程,或者说是半径。我们接下来只需要对那些在一个或多个光体积内的片段进行繁重的光照运算就行了。这可以给我们省下来很可观的计算量,因为我们现在只在需要的情况下计算光照。 -
相关阅读:
信息化与信息系统2
SQL常用语句 笔记
【云原生 | Kubernetes 系列】--K8s环境rdb,cefs的使用
win11系统如何访问ie浏览器(不用额外安装IE浏览器,使用win11系统自带功能即可访问ie浏览器)
Spring boot实现Activemq死信队列
【C++】list 容器的增删改查---模拟实现(图例超详细解析!!!)
麒麟KYLINOS2303系统上禁用新功能介绍页面
掌握这个技巧,你也能成为资产管理高手!
ssm信息安全资讯网站毕业设计-附源码191651
关于springboot创建kafkaTopic
- 原文地址:https://blog.csdn.net/qq_42403042/article/details/126794901