-
基于Python的汉语分词系统
资源下载地址:https://download.csdn.net/download/sheziqiong/86776599
资源下载地址:https://download.csdn.net/download/sheziqiong/86776599
汉语分词系统
目录
汉语分词系统 1
摘要 1
1 绪论 1
2 相关信息 1
2.1 实验目标 1
2.2 编程语言与环境 2
2.3 项目目录说明 2
3 训练测试 3
4 词典构建 3
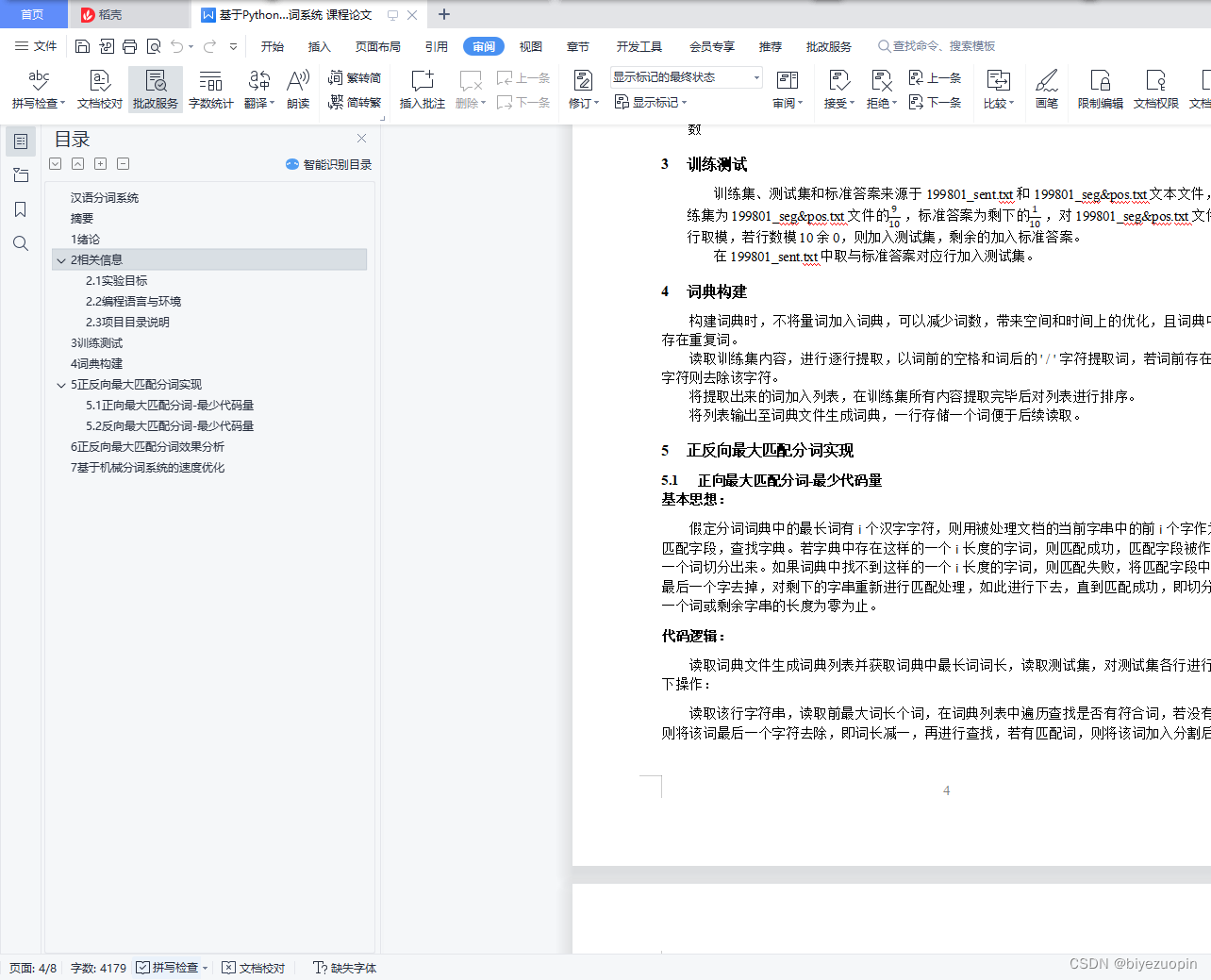
5 正反向最大匹配分词实现 3
5.1 正向最大匹配分词-最少代码量 3
5.2 反向最大匹配分词-最少代码量 4
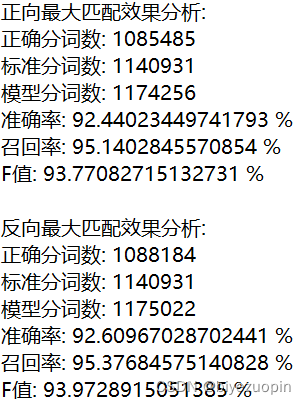
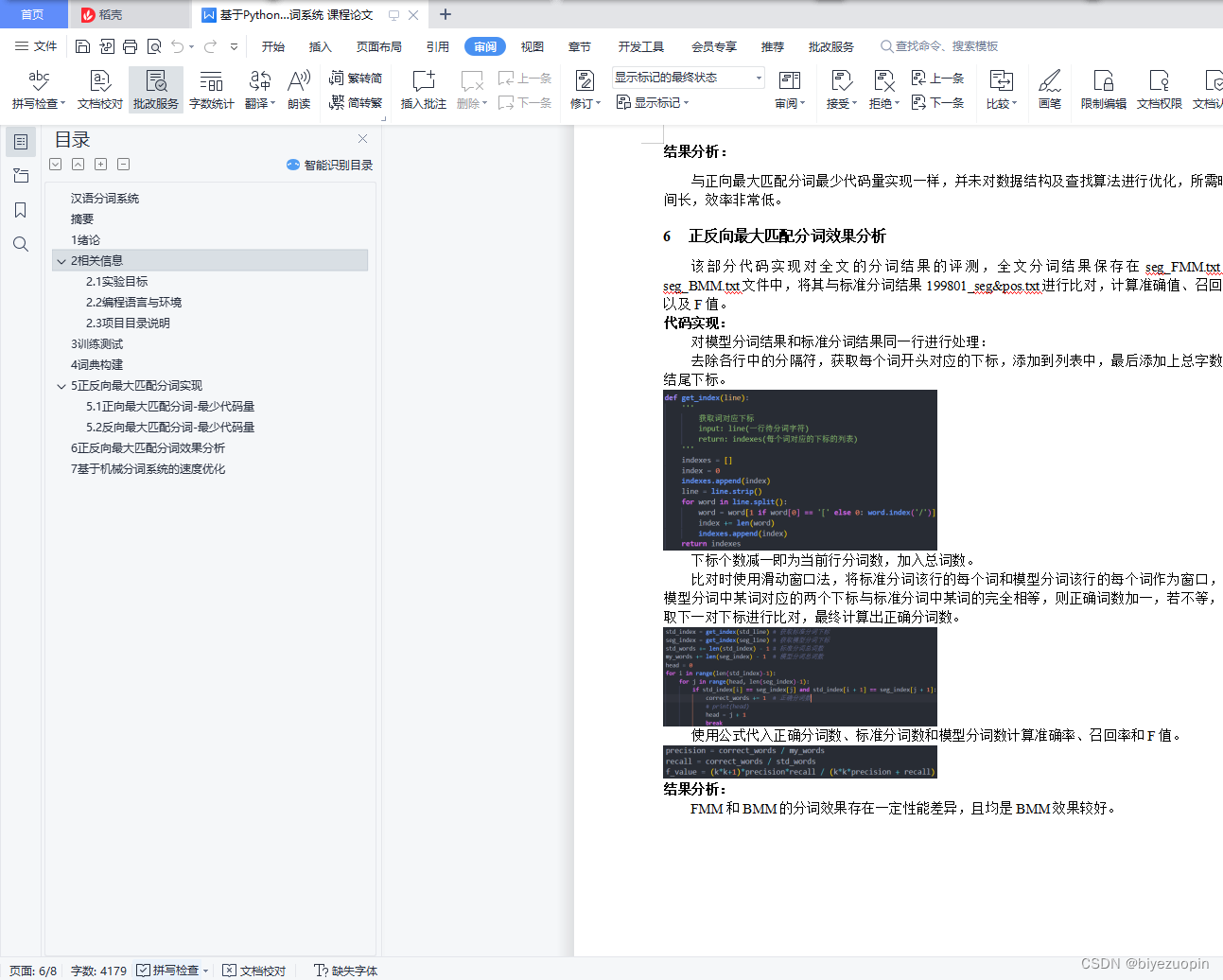
6 正反向最大匹配分词效果分析 5
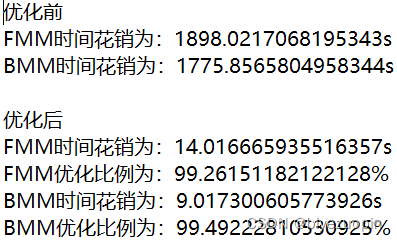
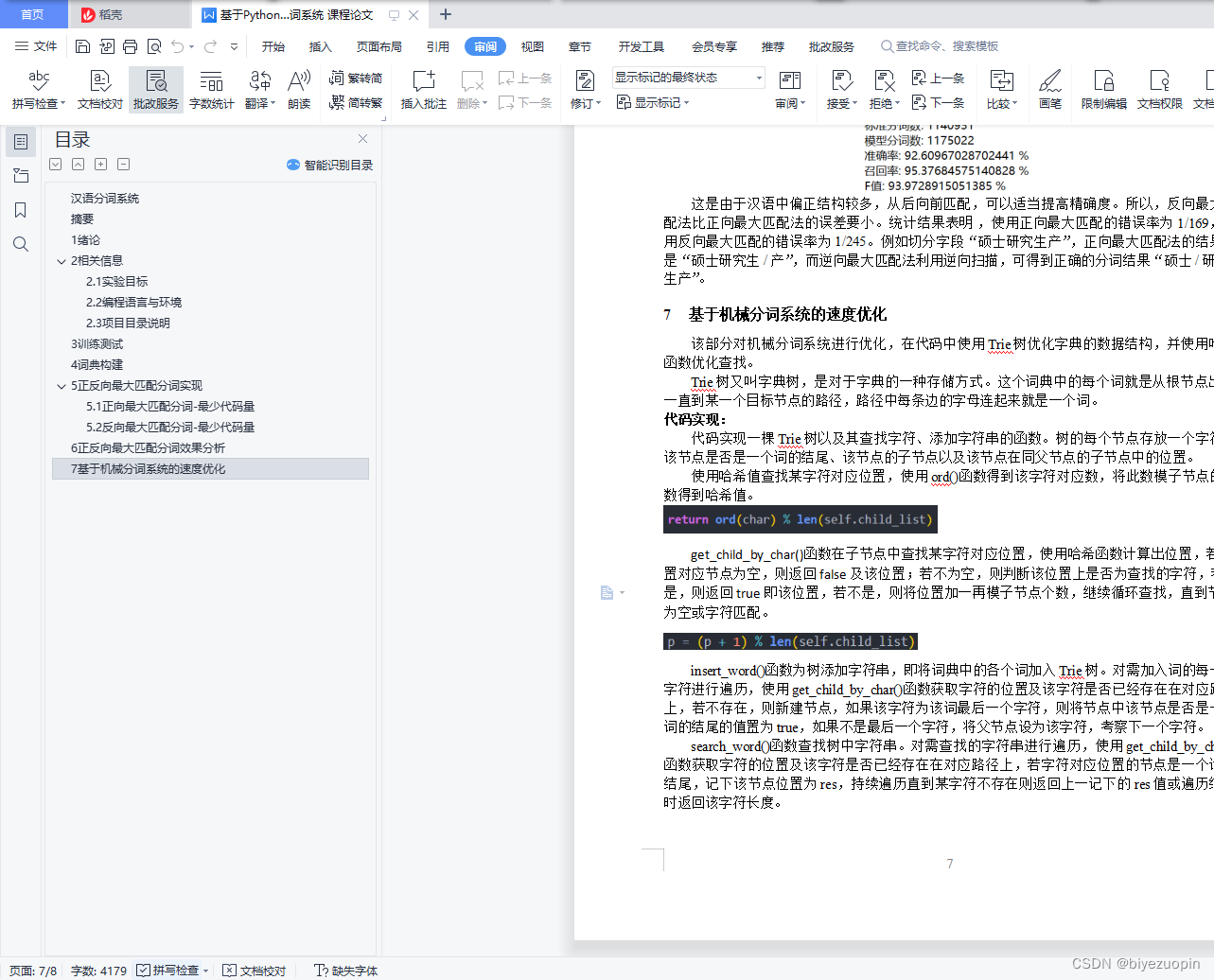
7 基于机械分词系统的速度优化 6
2.2编程语言与环境
Python 3.7.9 ,Windows11,VScode
2.3项目目录说明
目录中存在Code和io_files两个文件夹,Code文件夹中存放第一部分到第四部分实验代码,io_files文件夹中存放第一部分到第四部分实验产生文件和依赖文件。
io_files文件夹:
199801_sent.txt 为标准文本,是1998 年 1 月《人民日报》未分词语料,用于产生训练集和测试集
199801_seg&pos.txt 为标准文本,是1998 年 1 月《人民日报》的分词语料库,用于产生测试集对应的分词标准答案
dic.txt为自己形成的分词词典,存放根据训练集产生的词典
train.txt 为训练集,取分词语料库中 的数据作为训练集用于生成词典
std.txt 为标准答案, 取分词语料库中另外 的数据作为标准答案,与分词结果进行比对计算准确率、召回率和F 值
test.txt 为测试集,在未分词语料中取与标准答案相对应的 的数据作为测试集产生分词结果
seg_FMM.txt 为全文的分词结果,使用正向最大匹配分词,使用train.txt文件作为训练集,将199801_sent.txt文件进行分词
seg_BMM.txt为全文的分词结果,使用反向最大匹配分词,使用train.txt文件作为训练集,将199801_sent.txt文件进行分词
score.txt为第三部分生成的评测分词效果的文本,其中包括准确率(precision)、召回率(recall)和F 值
seg_FMM_1_10.txt 为测试集分词结果,使用正向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词
seg_BMM_1_10.txt 为测试集分词结果,使用反向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词
better_seg_FMM.txt 为测试集分词结果,使用优化后的正向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词,计算分词时间与seg_FMM_1_10.txt分词时间进行比较
better_seg_BMM.txt 为测试集分词结果,使用优化后的反向最大匹配分词,使用train.txt文件作为训练集,将test.txt文件进行分词,计算分词时间与seg_BMM_1_10.txt分词时间进行比较
TimeCost.txt 为分词所用时间,存放优化前和优化后的分词时间
Code文件夹:
part_1.py 为实验第一步词典的构建代码,其中包括生成分词词典函数以及生成训练集、测试集和标准答案的函数
part_2.py 为实验第二步正反向最大匹配分词实现代码,其中包括读取词典内容函数、正向最大匹配分词函数和反向最大匹配分词函数
part_3.py 为实验第三步正反向最大匹配分词效果分析代码,其中包括计算评测得分函数,计算总词数和正确词数函数,计算准确率、召回率和f值函数以及获取词对应下标的函数
part_4.py 为实验第四步基于机械匹配的分词系统的速度优化代码,其中包括Trie树的实现以及其中添加字符串函数,查找字符串函数,在子节点中查找字符对应位置函数和返回哈希值函数,还有获得正向最大匹配的词典树函数,获得反向最大匹配的词典树函数,优化后正向最大匹配分词函数,优化后反向最大匹配分词函数,全文分割函数以及计算时间函数
训练测试
训练集、测试集和标准答案来源于199801_sent.txt 和199801_seg&pos.txt文本文件,训练集为199801_seg&pos.txt文件的 ,标准答案为剩下的 ,对199801_seg&pos.txt文件各行取模,若行数模10余0,则加入测试集,本文转载自http://www.biyezuopin.vip/onews.asp?id=16703剩余的加入标准答案。
在199801_sent.txt中取与标准答案对应行加入测试集。
词典构建
构建词典时,不将量词加入词典,可以减少词数,带来空间和时间上的优化,且词典中不存在重复词。
读取训练集内容,进行逐行提取,以词前的空格和词后的 ’ / ’ 字符提取词,若词前存在 ’ [ ’ 字符则去除该字符。
将提取出来的词加入列表,在训练集所有内容提取完毕后对列表进行排序。
将列表输出至词典文件生成词典,一行存储一个词便于后续读取。DIC_FILE = '../io_files/dic.txt' TRAIN_FILE = '../io_files/train.txt' STD_FILE = '../io_files/std.txt' TEST_FILE = '../io_files/test.txt' K = 10 # 将标准分词文件的9/10作为训练集 ''' 3.1 词典的构建 输入文件:199801_seg&pos.txt(1998 年 1 月《人民日报》的分词语料库) 、199801_sent.txt(1998 年 1 月《人民日报》语料,未分词) 输出:dic.txt(自己形成的分词词典)、train.txt(训练集)、std.txt(标准答案)、test.txt(测试集) ''' def gene_dic(train_path =TRAIN_FILE, dic_path = DIC_FILE): ''' 生成分词词典 input: train.txt(训练集) output: dic.txt(分词词典) ''' word_set = set() # 词列表, 有序且不重复 max_len = 0 # 最大词长 with open(train_path, 'r') as train_file: # 读取训练文本 lines = train_file.readlines() with open(dic_path, 'w') as dic_file: for line in lines: for word in line.split(): if '/m' in word: # 除去量词 continue word = word[1 if word[0] == '[' else 0 : word.index('/')] #去除 '[' 符号, 取 '/'前的词 if (len(word) > max_len): # 更新最大词长 max_len = len(word) word_set.add(word) # 加入词典 word_list = list(word_set) word_list.sort() # 排序 dic_file.write('\n'.join(word_list)) # 用 '\n' 连接成新字符串 return word_list, max_len def gene_train_std(seg_path ='../io_files/199801_seg&pos.txt', train_path = TRAIN_FILE, std_path = STD_FILE, k = K): ''' 按9:1生成训练集和测试集 input: 199801_seg&pos.txt(分词语料库) output: train.txt(训练集), std.txt(标准答案), test.txt(测试集) ''' with open(seg_path, 'r') as seg_file: seg_lines = seg_file.readlines() std_lines = [] # 标准分词答案 with open(train_path, 'w') as train_file: for i, line in enumerate(seg_lines): if i % k != 0: train_file.write(line) # 模 k 不为 0 的行数加入训练集 else: std_lines.append(line) # 模 k 为 0 的行数加入标准答案 with open(std_path, 'w') as std_file: std_file.write(''.join(std_lines)) # 写入标准分词答案 gene_test() # 生成测试集 def gene_test(sent_path = '../io_files/199801_sent.txt', test_path = TEST_FILE, k = K): ''' 生成测试集 input: 199801_sent.txt(未分词语料) output: test.txt(测试集) ''' with open(sent_path, 'r') as sent_file: sent_lines = sent_file.readlines() with open(test_path, 'w') as test_file: for i, line in enumerate(sent_lines): if i % k == 0: test_file.write(line) # 模 k 为 0 的行数加入测试集 if __name__ == '__main__': gene_train_std() gene_dic()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
资源下载地址:https://download.csdn.net/download/sheziqiong/86776599
资源下载地址:https://download.csdn.net/download/sheziqiong/86776599 -
相关阅读:
互联网广告人--联合御寒--品牌,代理,平台,达人 多方携手御寒
代碼隨想錄算法訓練營|第五十二天|123 买卖股票的最佳时机III、188 买卖股票的最佳时机IV。刷题心得(c++)
获取苏宁易购商品信息操作详情
同花顺_代码解析_交易系统_J09_18
第十八章 Swing程序设计
内网安装redis+部署redis-cluster集群
【数据分享】全国县市2000-2020年医疗卫生机构床位数数据(excel和shp格式)
VsCode同时编译多个C文件
deepstream中Gst-nvmsgconv和Gst-nvmsgbroker两个插件的作用和关系
线下门店为什么要做新零售?
- 原文地址:https://blog.csdn.net/sheziqiong/article/details/126794356
