-
Kibana 8.X 如何做出靠谱的词云图?
1、问题产生
Kibana 实现一个词云效果并不复杂,甚至可以说非常简单。
大致可以分成如下几个步骤:
步骤1:已有索引待做词云的 text 类型字段设置:fielddata 为true,以便基于分词结果聚合操作。
步骤2:在 8.X 的 kibana 的 Data Views关联索引。
步骤3:在dashboard控制面板选择 Aggregation Based 下的 Tag cloud,选择步骤1设定的字段,选择好时间范围,词云就可以生成。
以构造微博数据(假数据)为例,词云效果如下所示:

问题来了!怎么那么多单字效果,有没有办法去掉,让词云效果相对靠谱可靠?
2、方案探讨
从目标出发思考,既然分词结果大局已定。把单字的分词全部删除掉不就可以了吗?于是有了方案一。
方案一:Kibana 控制面板过滤掉单字索引
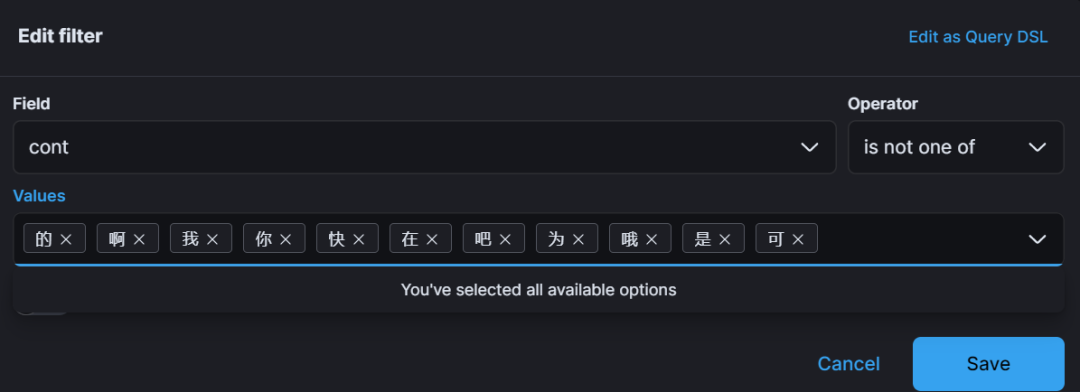
加上后,看看效果:

并不乐观,因为我们的方案仅是将能看到的 Top 50 里的单字给去掉了。
新的 Top 50 单字仍然会出现。
也就是说:方案一仅“治疗表明”,不能由表及里。
这个问题曾困惑我很久,我一度认为,把单字穷举出来,全部删掉即可。
后来,思来死去,发现思考问题方向不对,应该从“源头”解决问题。
于是,有了方案二。
2.2 方案二:分词阶段过滤掉单字词项
中文分词我们依然选择的 medcl 大佬开源的 IK 分词下的 ik_smart 粗粒度分词器。ik 中文分词插件支持两种分词效果:
其一:ik_max_word,细粒度分词。
其二:ik_smart, 粗粒度分词。
原有的分词已经构建完毕,如何基于已有成熟分词再构建新的分词器呢?
这时候,脑海里要对分词 analysis 的三部分组成要“门儿清”。
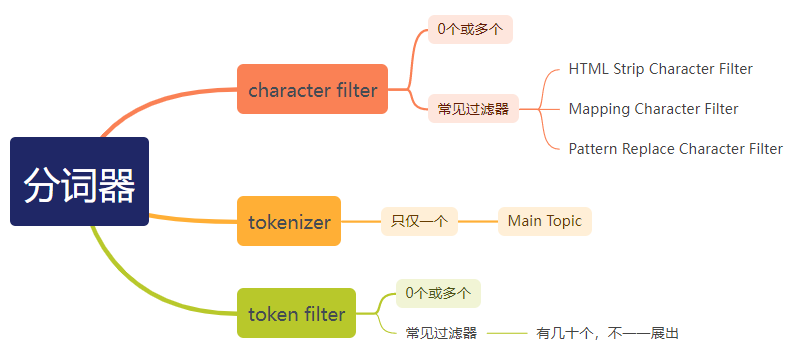
我们的
tokenizer已选定ik_smart,不能修改。可动的只有:character filter和token filter,而能实现仅保留 两个 或者两个以上分词的效果的需要借助:token filter下的length token filter实现。length token filter的本质如其定义:emoves tokens shorter or longer than specified character lengths. ”
中文释义为:“删除比指定字符长度更短或更长的标记”。
接下来,我们实战一把。
3、基于自定义分词实现靠谱词云效果
如前方案二所述,在分词处做“手脚”,能实现自主、可控的分词粒度。
3.1 步骤1:自定义分词
如下 DSL 实现了自定义索引。
在原有
ik_smart分词器的基础上,添加了“bigger_than_2” 过滤器,实现了将小于2个字符的 分词项过滤掉的效果。- PUT weibo_index
- {
- "settings": {
- "analysis": {
- "analyzer": {
- "ik_smart_ext": {
- "tokenizer": "ik_smart",
- "filter": [
- "bigger_than_2"
- ]
- }
- },
- "filter": {
- "bigger_than_2": {
- "type": "length",
- "min": 2
- }
- }
- }
- },
- "mappings": {
- "properties": {
- "title": {
- "type": "text",
- "analyzer": "ik_smart_ext",
- "fielddata": true
- },
- "insert_time": {
- "type": "date"
- }
- }
- }
- }
3.2 步骤2:重新生成索引且reindex数据
- POST _reindex
- {
- "source": {"index": "weibo_index_20220901"},
- "dest": {"index": "weibo_index_20220904"}
- }
3.3 步骤3:重新生成词云

依然不是最完美的词云效果,但是,比未处理前已经好很多。
4、小结
解决问题的时候,多从源头思考,换一个思路,效果会好很多。
大家有任何 ElasticStack 相关技术问题都欢迎留言交流。
ElasticStack 视频不定期更新中:
B站:https://space.bilibili.com/471049389
视频号:铭毅天下
推荐阅读
-
相关阅读:
无需公网IP,实现公网SSH远程登录MacOS【内网穿透】
讯优随身Wi-Fi(410)折腾
使用浏览功能
基于NoCode构建简历编辑器
数据库事务概述
Linux下的IMX6ULL——开发板基本操作(二)
el-date-picker ie模式下 初始化未赋值;未清空
基础到高级涵盖11个技术,Alibaba最新出品711页Java面试神册真香
Oracle和Random Oracle
Linux(六)NFS(network file system)服务器实验
- 原文地址:https://blog.csdn.net/wojiushiwo987/article/details/126716285
