-
聚簇索引和二级索引
先背书
-
聚簇索引通过表的主键构建一个B+tree树 -
构建成的
B+tree树的叶子节点存放每一行的所有字段数据,也把叶子节点称为数据页 -
每张表只能拥有一个聚簇索引
-
如果没有定义主键,innodb会选择非空的
唯一索引(第一个唯一索引)代替 -
如果自定义主键和唯一索引都没有的话,innodb会生成一个
隐式主键id,来做聚簇索引
二级索引
-
也叫
辅助索引或者非聚簇索引 -
和
聚簇索引不一样的是,二级索引的叶子节点不存储行数据了,除了键值之外,还包含了相应行数据的聚簇索引对应列的值 -
在查询
二级索引时,先查询到叶子节点上相应行数据的聚簇索引对应列的值,再去查询聚簇索引查询到数据 -
一张表可以有多个
二级索引
直接上栗子
-
用户类别表,主要有四个字段
id(主键id),user_id(用户id),cate_id(用户类别),update_time(数据写入时间) -
索引的话,就
id(主键id)创建一个主键索引,user_id(用户id) 和cate_id(用户类别)创建一个联合索引,建表语句如下:
- CREATE TABLE `t_user_cate` (
- `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
- `user_id` bigint(20) NOT NULL COMMENT '用户ID',
- `cate_id` varchar(20) NOT NULL COMMENT '用户类别ID',
- `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '数据插入/更新时间(会自动更新,不需要刻意程序更新)',
- PRIMARY KEY (`id`),
- KEY `idx_user_cate_id` (`user_id`,`cate_id`)
- ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='写文章使用,用户类别表'
-
插入过程略
t_user_cate表的聚簇索引展示
-
因为有创建了id为主键索引,所以 t_user_cate表的聚簇索引在
字段id上的 -
聚簇索引B+tree的示例如下:

-
如图来看
-
叶子节点使用
单链表链接,按id列递增链接,方便基于范围的顺序检索 -
聚簇索引的叶子节点
存储完整一行表数据,每个聚簇索引下都是每一行的完整数据 -
通过主键id查询时候,因为叶子节点已经存储了完整的每一行的数据,查询的效率非常高
t_user_cate表的二级索引展示
-
画图时忽略联合索引
idx_user_cate_id,因为图不上不好画,我就直接画成单索引 -
二级索引B+tree的示例如下:

-
二级索引的叶子节点,存储
聚簇索引所在列的值,最后通过查询到聚簇索引列的值再去回表查询
回表查询
-
说下回表查询
-
因为
二级索引叶子节点不像聚簇索引那样,不存储完整的行数据,存储的是聚簇索引所在列的值,所以还需要通过查询到的值查询聚簇索引,是会损耗一点性能的 -
比如说这个sql
- SELECT
- *
- FROM
- t_user_cate
- where
- user_id = 1123
-
回表查询如下:
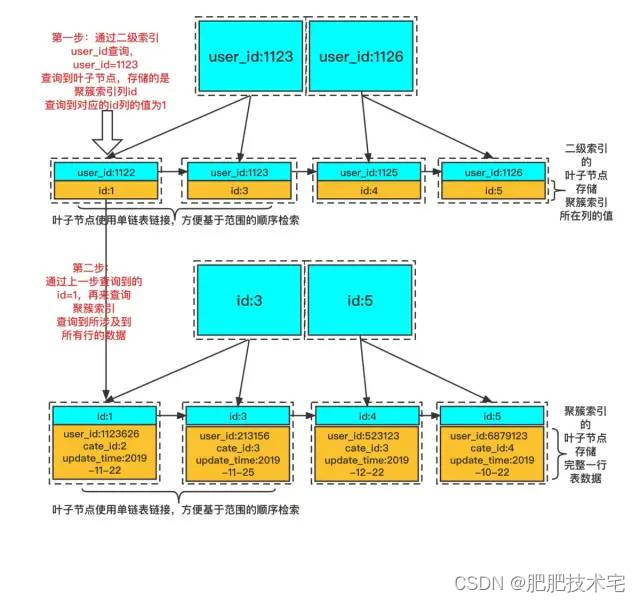
-
查询过程如下:
-
第一步:通过
二级索引user_id查询,user_id=1123,查询到叶子节点,存储的是聚簇索引列id查询到对应的id列的值为1 -
第二步:通过上一步查询到的id=1,再来查询
聚簇索引查询到所涉及到所有行的数据
回表的两种情况
-
查询
二级索引时候,回表不是必要步骤 -
当你查询的所有字段都是索引字段时,这时候不需要进行回表查询,例如:
- SELECT
- user_id,
- cate_id
- FROM
- t_user_cate
- where
- userid = 1123
-
查看该sql的执行计划:

-
注意最后一列
Extra,值是Using index,代表查询的字段是索引覆盖的,所以本次查询没有进行回表查询 -
当你查询的字段有的不在
索引范围内,这时候就会进行回表查询,例如:
- SELECT
- user_id,
- cate_id,
- update_time
- FROM
- t_user_cate
- where
- userid = 1123
-
这次查询字段多增了一个
update_time字段,本字段不在索引中,再来看执行计划:
-
对于上一个sql的执行计划,执行计划中的字段基本和上一个sql一致,只有
Extra字段不一样,本次执行计划中Extra字段为空,说明没有索引覆盖,查询需要走回表查询
聚簇索引优缺点总结
-
通过上面例子,我们来总结一下聚簇索引的优缺点
优点
-
数据查询效率高,因为聚簇索引构建的B+tree的叶子节点存放完整的行数据,所以通过聚簇索引查询比二级索引查询速度快
-
基于主键的排序查找、范围查找效率高
缺点
-
数据写入时候,比较依赖于主键的顺序插入,所以都需要我们自定义一个自增主键
-
更新主键的代价很高,会导致被更新的行移动
-
-
相关阅读:
算法刷题笔记 差分矩阵(C++实现)
Linux学习笔记-Ubuntu系统下配置用户ssh只能访问git仓库
如何正确的写出第一个java程序:hello java
消息队列的持久化、分发策略、高可用和高可靠
分库分表系列:分库分表的前世今生
MySQL 基础笔记(2)
uniapp EventChannel 页面跳转参数事件传递navigateBack,navigateTo 成功后通知事件区别
手把手教你用Python绘制神经网络图
如何提高你的项目绩效?
uniapp上echarts地图钻取
- 原文地址:https://blog.csdn.net/m0_71777195/article/details/126781374