-
数据结构与算法--散列表
前言
散列表也叫哈希表,是根据键值对(key,value)进行访问的一种数据结构。他是把一对(key,value)通过key的哈希值来映射到数组中的,也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
一、什么是散列表
散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
二、HashMap
散列表中最常见的应该就是HashMap了,HashMap的实现原理非常简单,他其实就是数组加链表的一种数据结构。如果映射在数组中出现了冲突,他会以链表的形式存在。我们来看一下他的数据结构是什么样的。
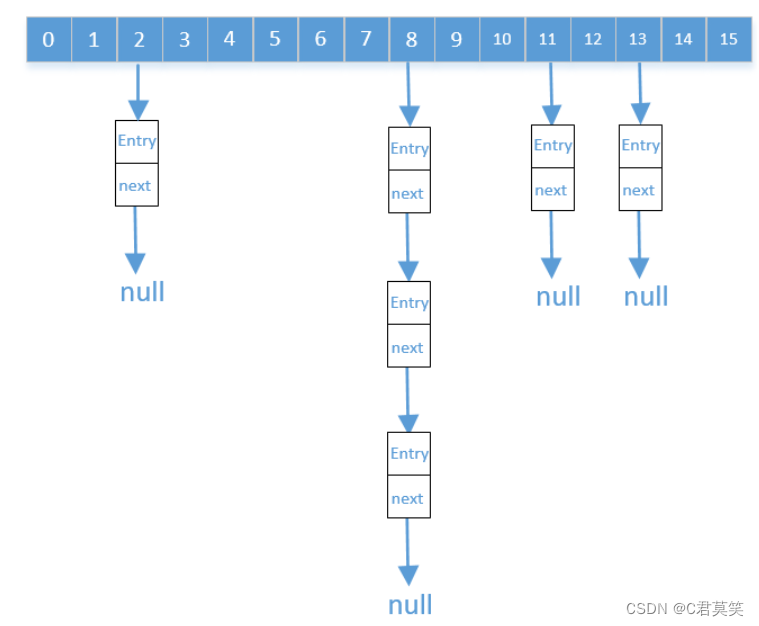
数组的长度即是2的n次幂,而他的size又不大于数组长度的75%。
HashMap的实现原理是先要找到要存放数组的下标,如果是空的就存进去,如果不是空的就判断key值是否一样,如果一样就替换,如果不一样就以链表的形式存在。三、散列表原理
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是0(1)的特性。我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组标标,从对应的数组下标的位置取数据。
四、散列函数的设计
散列函数计算得到的散列值是一个非负整数;.
如果key1 = key2,那hash(key1) == hash(key2);
如果key1 != key2,那hash(key1) != hash(key2),
散列函数的设计不能太复杂,散列函数生成值要尽可能随机并且均匀分布如果不符合3 那么就出现了散列冲突,散列冲突是无法避免的
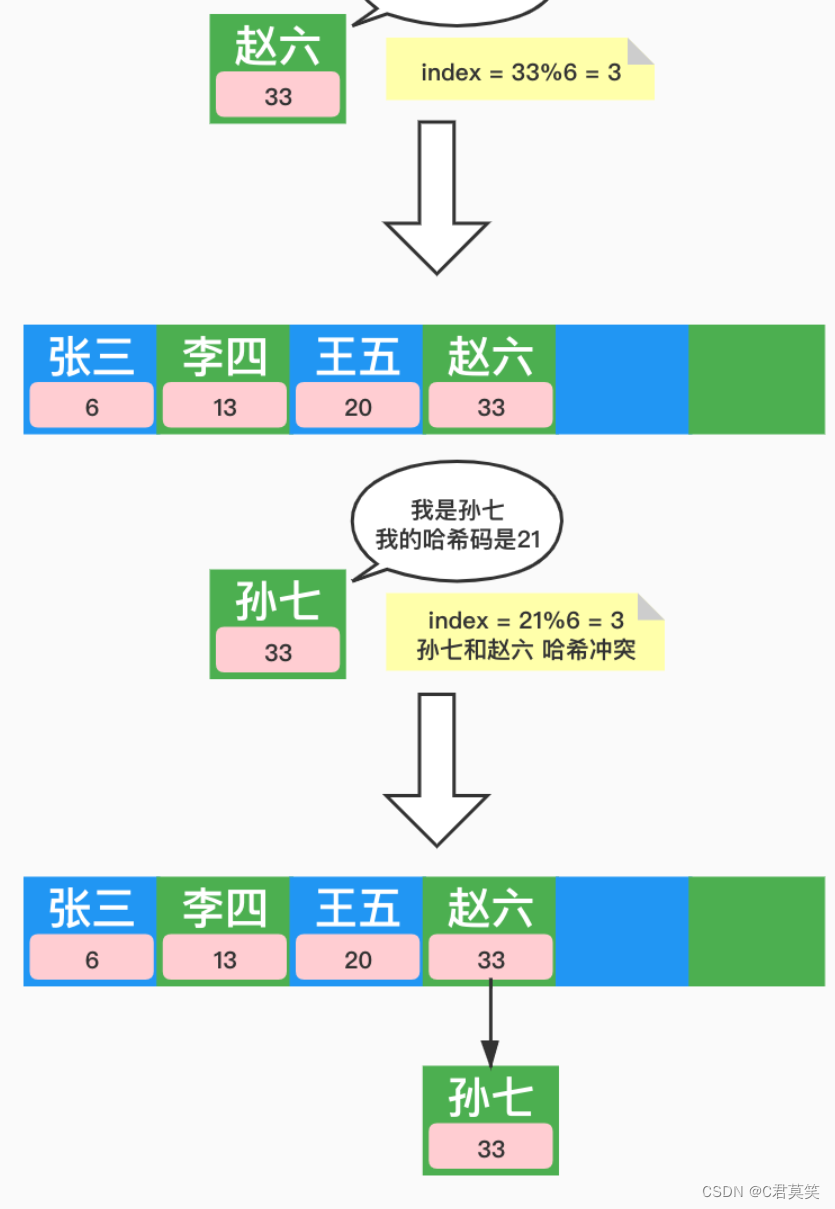
五、解决散列冲突的方法
1、开放寻址法
开放寻址法:如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。
举个例子
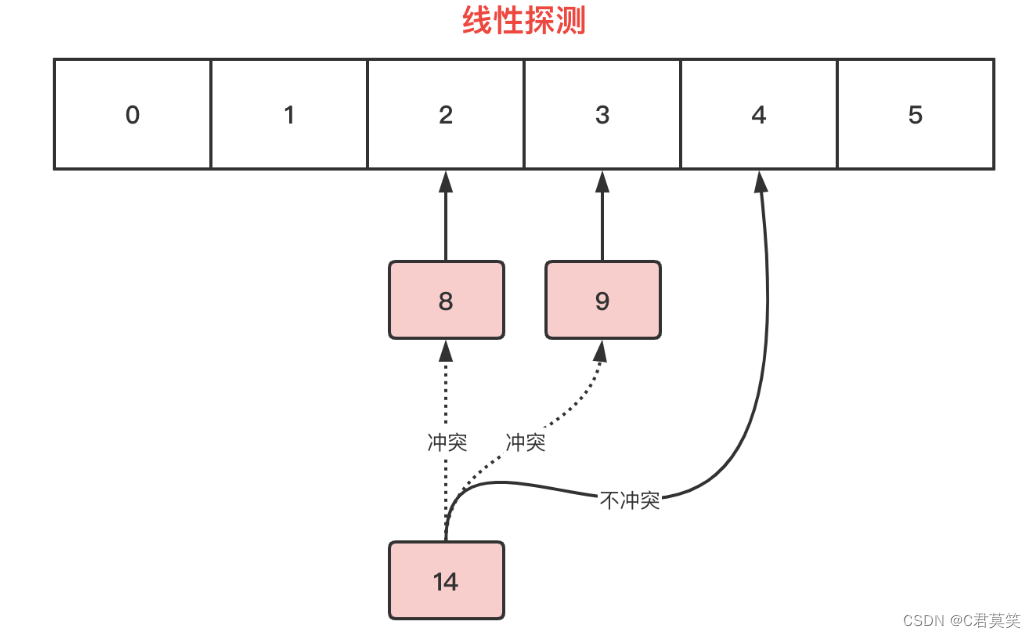
哈希表中已经插入8、9元素,此时再插入14,下标2已经被8给占用了,出现哈希冲突。
线性探测会环形寻找next节点,先找到下标3,被9占用了,依然冲突,再找到下标4,没有被占用,即没有发生冲突,则将14放入下标4的节点中。
装在因子: 散列表中一定比例的空闲槽位。公式: 散列表的装载因子 = 填入表中的元素个数 / 散列表的长度
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
开放定址法的优点:
只要哈希表还有位置,通过不断的探测,总能找到合适的位置。
开放定址法的缺点
探测的次数不可控,一旦探测次数骤增,会严重影响哈希表的读写性能。2、链表法
链表法是一种更加常用的散列冲突解决办法,相比开放寻址法,它要简单很多。我们来看这个图,在散列表中,每个"桶(bucket) "或者"槽(slot) "会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
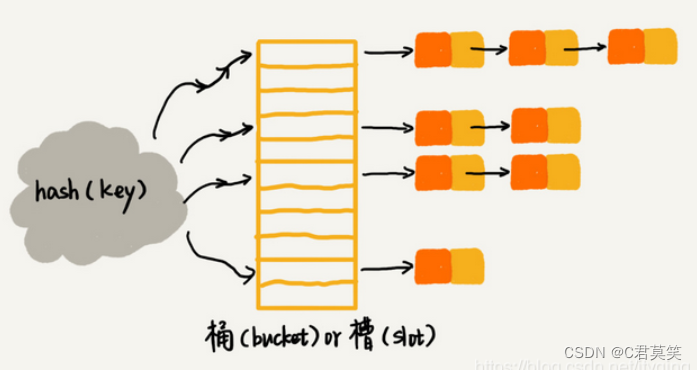
将哈希码对应一个链表,插入元素时,如果哈希码冲突了,就将元素插入到链表,可选头插或尾插。查询时,遍历哈希码对应的链表。HashMap采用的就是这种方式。优点
- 内存利用率比开放寻址法要高,链表结点可以在需要的时候再创建
- 对大装载因子容忍度更高,只要散列函数的值随机均匀,即使装载因子变成 10,也就是链表的长度变长了而已
缺点
- 存储小对象需要额外的指针,比较耗内存,但对于大对象则可以忽略
- 链表分散存储,无法利用 CPU 缓存
总结
数组的特点是「访问简单,插入删除困难」,链表的特点是「访问困难,插入删除简单」。散列表在某种程度上融合了二者的优点,可以说散列表是升级后的数组。散列表通过给元素生成一个哈希码来加速访问效率,因为哈希冲突的存在,在发生冲突时散列表可以将元素节点转换成链表,将冲突的元素放到一根链上。
转换成链表是为了解决哈希冲突不得已而为之的办法,为了保证散列表的性能,开发者需要尽量避免哈希冲突,严格控制链表的长度,一旦退化成链表,数据访问的效率将从O(1)下降到O(n)。 -
相关阅读:
电容笔和触屏笔一样吗?Ipad高性价比电容笔排行
PyQt5 信号(Signal)与槽(Slot)
lua调用C++函数
Go语言将string解析为time.Time时两种常见报错
Python开发者的宝典:CSV和JSON数据处理技巧大公开!
ELK Kibana的基本使用 (七)
AIGC爬虫实战(一)
SpringMVC进阶:常用注解、参数传递和请求响应以及页面跳转
杭州市IT行业人才需求地图信息系统的设计与实现
java面试题-学成在线项目
- 原文地址:https://blog.csdn.net/qq_34623621/article/details/126772194