-
TensorRT快速上手指南
前言:
最近一段时间接触了TensorRT,因此顺带整理了一份TensorRT中一些常用关键组件的笔记,以方便未来能够快速查阅和上手。需要注意的是本文只是一些常用特性与关键组件的梳理,而不是一个小白入门的教程,所以后续文章内容并不会提供快速上手的样例代码,实际上TensorRT官方的example中已经挺完善了,从0到1入门的新手建议直接看官方example中的代码。
版本说明:本文主要以 TensorRT 8.0 为例说明- 1
当前 PyTorch 模型要部署到 TenosrRT 上需要通过 ONNX 做桥接,因此一个 PyTorch 模型需要先转换成 ONNX,然后再由 ONNX 转换成 TensorRT engine 对象,才能实现在 TensorRT 的目标硬件上部署。
TensorRT 上主要存在以下几个对象:
- builder:创建 config、network、engine 等其它对象的核心类。
- network:tensorrt 的模型类,其它框架的模型在解析之后将被用于填充(populate) network。
- config:builder 的配置
- OnnxParser:onnx 文件解析类,将 ONNX 文件解析并用于填充 tensorrt network 结构。
- engine:在特定 config 与硬件上编译出来的计算引擎,且只能应用于特定的 config 与硬件上,支持持久化到本地以便进行发布或者节约下次使用的编译时间。engine 集成了模型结构、模型参数与最优计算 kernel 配置。同时 engine 与硬件和 TenorRT 版本强绑定,所以要求 engine 的编译与执行的硬件与 TensorRT 版本要保持一致。
- context:进行 inference 的实际对象,由 engine 创建,与 engine 是一对多的关系。
构建流程图

Network 怎么来?
TensorRT 提供了多种渠道来构建 Network 对象:
1.使用 TensorRT 内置接口搭建模型结构,然后将其它框架的参数映射过去。
2.使用对应的 Parser 将目标模型解析然后将结果自动填充到 TensorRT network 中,当前 TensorRT 支持 ONNX、Caffe 和 UFF 三种类型 Parser,因此 PyTorch 模型可以通过 ONNX 实现与 TensorRT 的对接部署。Parser 使用
使用 parser 对象可以从目标模型文件中解析出模型结构与模型参数,然后自动填充到 network 中,parser 的使用方式如下。
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH) with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser: with open(model_path, 'rb') as model: if not parser.parse(model.read()): for error in range(parser.num_errors): print(parser.get_error(error))- 1
- 2
- 3
- 4
- 5
- 6
TensorRT 目前支持的 Parser 有:
1.UffParser
2.CaffeParser
3.OnnxParserEngine 怎么来?
当 network 与 config 都准备就绪后,需要通过 builder 来构建 engine,builder 构建 engine 的其中一步就是从众多的 CUDA kernel 中搜索出一组当前条件下的最优配置,以此来保证 inference 的高效执行。
engine = builder.build_engine(network, config)- 1
build_engine 发生了什么?
1.解析 network graph,注册计算层
2.删除冗余的常量节点与无用层
3.进行 model fusion,构成新的计算层
4.计算层最优执行 kernel 搜索
5.打包最终的 kernel 方案构成 engineEngine 序列化/持久化
为了避免每次运行 inference 之前都需要对 engine 进行编译,用户可以将 engine 序列化后持久化到本地。
# 序列化 serialized_engine = engine.serialize() # 反序列化 with trt.Runtime(TRT_LOGGER) as runtime: engine = runtime.deserialize_cuda_engine(serialized_engine) # 持久化序列化后的 engine with open(“sample.engine”, “wb”) as f: f.write(engine.serialize()) # 加载持久化的 engine,并反序列化 with open(“sample.engine”, “rb”) as f, trt.Runtime(TRT_LOGGER) as runtime: engine = runtime.deserialize_cuda_engine(f.read())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如何进行 inference?
一、memory buffer 申请
因为 TensorRT 是基于 CUDA 构建的,在编程模型上也集成了 CUDA 的抽象,将设备抽象为 host 与 device,并且用户需要显示地把数据从 host 拷贝到 device 中,反之亦然,device 输出的数据需要显示地拷贝到 host 中。
因此在开始 inference 之前,需要先在 host 与 device 的 memory 中申请 buffer,同时 host 中的 memory 将被设定成 page-lock 类型,该类型可以保证该 buffer 所对应的内存页不会被操作系统换出到磁盘。
假设当前模型是单输入与单输出的,那么对应的 engine 将只有两个 binding,可以通过 for binding in engine 的方式来遍历获取 binding,然后对每个 binding 对应输入输出分别去申请 memory buffer。
# Simple helper data class that's a little nicer to use than a 2-tuple. class HostDeviceMem(object): def __init__(self, host_mem, device_mem): self.host = host_mem self.device = device_mem def __str__(self): return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device) def __repr__(self): return self.__str__() # Allocates all buffers required for an engine, i.e. host/device inputs/outputs. def allocate_buffers(engine): inputs = [] outputs = [] bindings = [] stream = cuda.Stream() for binding in engine: size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size dtype = trt.nptype(engine.get_binding_dtype(binding)) # Allocate host and device buffers # 申请锁页内存 host_mem = cuda.pagelocked_empty(size, dtype) device_mem = cuda.mem_alloc(host_mem.nbytes) # Append the device buffer to device bindings. bindings.append(int(device_mem)) # Append to the appropriate list. if engine.binding_is_input(binding): inputs.append(HostDeviceMem(host_mem, device_mem)) else: outputs.append(HostDeviceMem(host_mem, device_mem)) return inputs, outputs, bindings, stream- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
后续在 inference 过程中,将输入数据放入 inputs buffer,从 outputs buffer 中取出计算结果。
二、创建 context 进行 inference
context 是由 engine 创建出来的,一个 engine 可以创建多个 context,且 context 需要与 cuda stream 进行绑定。通过 engine 创建 context。
context = engine.create_execution_context()- 1
使用 context 进行 inference,这个过程涉及数据搬运与 inference 执行,输入与返回数据均要求是 numpy array。
# This function is generalized for multiple inputs/outputs. # inputs and outputs are expected to be lists of HostDeviceMem objects. def do_inference(context, bindings, inputs, outputs, stream, batch_size=1): # Transfer input data to the GPU. [cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs] # Run inference. context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle) # Transfer predictions back from the GPU. [cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs] # Synchronize the stream stream.synchronize() # Return only the host outputs. return [out.host for out in outputs]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
关于量化
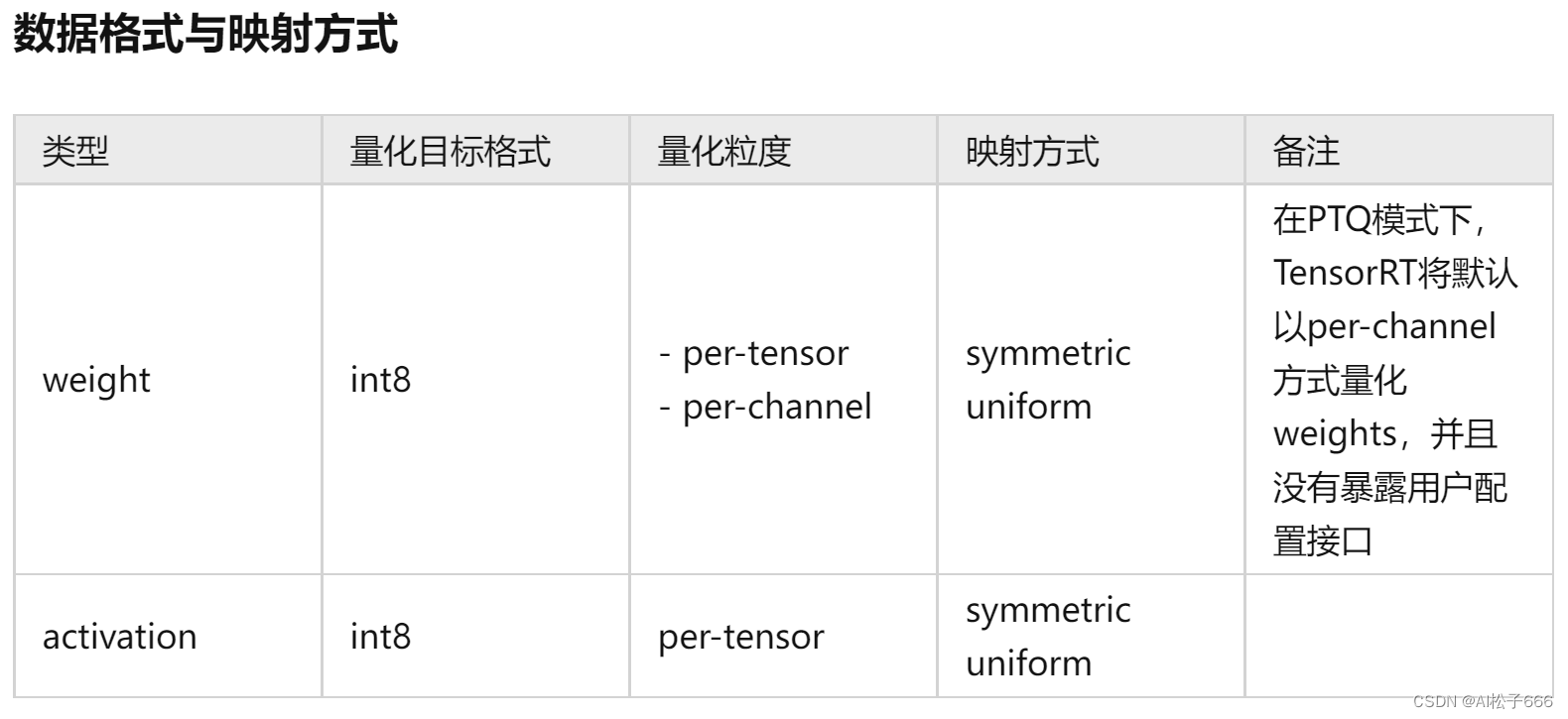
数据格式与映射方式
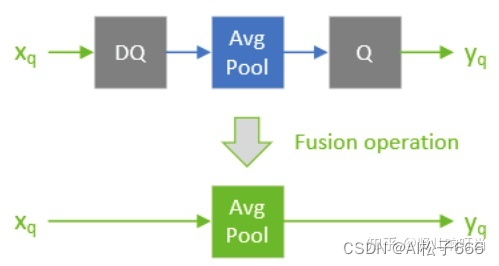
Q与DQ层的设置
Q 指的是 quantize layer,DQ 指的是 dequantize layer- 1
TensorRT 的设计中,但凡是需要使用量化计算的层,该层的前后就需要成对出现 quantize 与 dequantize 层。
在 TensorRT 中,一个 Quantizable-layer 指的是整型输入经过 DQ 层,然后经过目标层计算后,输出再经 Q 层进行量化,这个目标层被称为 Quantizable-layer,比如 avg_pool。以下图为例在实际部署中,DQ 与目标层与 Q 层将被融合,而融合后的层被称为 quantized AvgPool。
量化模式
根据官方文档,TensorRT 目前只支持 symmetric uniform 形式的量化参数映射,也就是说 zero_point 恒为 0。
一、PTQ/Calibration
TensorRT 的 PTQ 模式下,通常得到的量化校准后的模型都是一个混合精度的量化模型。因为根据官方文档描述 PTQ 模式下,TensorRT 的设计是以计算性能作为第一优先指标,它首先基于原始的浮点精度模型进行图优化操作,然后选择其中的一些层进行 INT8 量化尝试,如果这些层在 INT8 下的计算性能比 FP16 或者 FP32 来得更高,那么这些层将采用 INT8 计算,但是如果性能并没有更高,就会采用 FP32 或者 FP16 方式计算。因此经过 TensorRT PTQ 校准之后得到的 engine 是一个在目标硬件上性能最优的混合精度的量化模型,并且其中哪些层会采用 INT8 量化计算也非用户可以控制。
PTQ 支持四种校验模式:
- LEGACY_CALIBRATION:最基础的 calibration,当其它三种都失效的时候,会 fallback 到 legacy。
- ENTROPY_CALIBRATION
- ENTROPY_CALIBRATION_2:官方推荐默认使用,效果好
- MINMAX_CALIBRATION:适用于 NLP 任务
以上四种校验模式在 TenosorRT 文档中均有介绍。
关于校验数据: 通常校验数据会从训练集中取一个子集出来,子集的数量也并非一定越大越好。就 Imagenet-1k 的分类经验而言,校验数据取 1000 张样本就可以取得不错的效果,反而如果使用了更多的样本数据,效果反而可能下降。
TensorRT PTQ 模式支持两种方式取得量化参数:1.用户指定用于 PTQ 的 calibration data,然后执行 build engine,PTQ 将使用 calibration data 自动去获取量化参数,但是最终出来的模型,哪些层会以 INT8 的格式跑,哪些层会以 FP16/FP32 的格式跑是不可预知、不可控的。
2.用户手动给需要量化的目标层指定 layer.precision、layer.get_input(0).dynamic_range 与 layer.get_output(0).dynamic_range,然后执行 build engine,然后 TensorRT 将直接使用用户提供的参数编译得到含有量化层的 engine。
❗️针对第二点需要注意的是,layer.precision、layer.get_input(0).dynamic_range 与 layer.get_output(0).dynamic_range 这三个参数都需要有,否则即便设置了 builder.strict_type_constraints=True,TensorRT 为了编译顺利,也会将参数缺失的 layer fallback 到 FP16/FP32 去。这点对于需要严格控制量化层的用户来说需要谨慎。model fusion
TensorRT 中常见的 fusion 有一下几种:
- conv+relu
- conv+relu+max_pool
- conv+add+relu
- conv+add
如下图是 renset50 的第一个 bottleneck 层,经过 TensorRT 编译之后各个红框中的层将被融合。

注意:以上之所以没有提到 bn,是因为默认 conv+bn 已经做了合并。- 1
二、Explicit-Quantization
百分百由用户掌控量化与反量化的位置,但是需要 ONNX 的 Q/DQ 操作配合,也就是用户通过在 ONNX IR 中显示地插入 Q/DQ 层来控制量化与反量化的位置。相关的案例可以参考:pytorch-quantization。
 PTQ VS. explicit-quantization 另一点值得注意的是,在将含有 Q/DQ 层的 ONNX 模型导出以后,用于构建 TensorRT engine 的时候,需要将添加以下配置项,这些是在 pytorch-quantization 与 TenosorRT 文档中没有提到的:
PTQ VS. explicit-quantization 另一点值得注意的是,在将含有 Q/DQ 层的 ONNX 模型导出以后,用于构建 TensorRT engine 的时候,需要将添加以下配置项,这些是在 pytorch-quantization 与 TenosorRT 文档中没有提到的:import tensorrt as trt EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH) # 指定使用 EXPLICIT_PRECISION EXPLICIT_PRECISION = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_PRECISION) builder = trt.Builder(TRT_LOGGER) network = builder.create_network(EXPLICIT_BATCH | EXPLICIT_PRECISION) config = builder.create_builder_config() # 开启 builder int8 flag config.set_flag(trt.BuilderFlag.INT8)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果没有在 create_network 的时候指定 EXPLICIT_PRECISION,那么 build engine 的时候将碰到以下错误:
ERROR: Failed to parse the ONNX file. In node -1 (importConv): UNSUPPORTED_NODE: Assertion failed: ctx->network()->hasExplicitPrecision() && "TensorRT only supports multi-input conv for explicit precision QAT networks!"- 1
- 2
而如果 config 没有设定 trt.BuilderFlag.INT8 将遇到以下错误:
[TensorRT] ERROR: Int8 precision has been set for a layer or layer output, but int8 is not configured in the builder [TensorRT] ERROR: Network validation failed.- 1
- 2
其它
profile 技巧
分析每一层具体执行算子
TensorRT PTQ 接口的实现是朝着性能最优进行优化,所以经过 PTQ 自动优化之后得到的模型是一个混合精度模型,这样在模型 inference 过程中不利于用户理解哪一层究竟采用了哪种数据精度(INT8/FP16/FP32)。具体来说 TensorRT PTQ 优化的时候遵循着以下规则:
- 如果用户规定了当前计算层的数据格式为 INT8,TensorRT 需要先确定该计算层是否有对应 INT8 的实现方案,如果没有则只能将计算 fallback 到 FP32 实现,比如 softmax 层。
- 如果某一个计算存在多种实现,那么将以性能最优为选择标准。比如说当前有基于 CUDA core 的 INT8 kernel 和基于 Tensor core 的 INT8 kernel(要求输入 channel 对齐到 32),那么对于大多数 CNN 模型的第一层的输入通道通常是 3,因此如果使用 Tensor core 的实现就需要将输入通道先 pad 到 32,但是这样就存在很多计算是无效的(29/32)。而仅需要将输入通道对其到 4 的 CUDA core 实现在此时也许就成为了更优的选择。
- 是否为引入 reformat 操作。比如对于一个需要获取 FP32 数据格式的输出层,当我们在 INT8 模式下,虽然在计算的时候 INT8 也许会比 FP32 的来的更高效,但是输出的 INT8 数据还需要经过 reformat 转换为 FP32 输出,这里的转换也会引入开销。
- 用户如果声明了 strict type constraint,那么 TensorRT 将忽略性能是否最优,只要指定的计算在对应声明的数据格式下有相应的实现 kernel,TensorRT 就会进行指派。
以上种种规则导致了用户很难去理解某个特定 engine 的实际执行 kernel 是怎样的。
不过所幸只要将 TensorRT 的 Logger 设置为 VERBOSE 类型,那么在编译 engine 完成之后,TensorRT 的日志系统会自动输出每一层的所使用的算子类型、数据精度等信息。
以下信息是使用 resnet18 ONNX 模型编译 TensorRT engine 的输出结果,可以看到此次 engine 的编译花费了 10 秒钟。
[TensorRT] VERBOSE: Engine generation completed in 10.7146 seconds. [TensorRT] VERBOSE: Builder timing cache: created 62 entries, 58 hit(s) [TensorRT] VERBOSE: Engine Layer Information: [TensorRT] VERBOSE: Layer(scudnn): Conv_0 + Relu_1, Tactic: -4420849921117327522, input[Float(3,224,224)] -> 125[Float(64,112,112)] [TensorRT] VERBOSE: Layer(PoolingTiled): MaxPool_2, Tactic: 6947073, 125[Float(64,112,112)] -> 126[Float(64,56,56)] [TensorRT] VERBOSE: Layer(scudnn_winograd): Conv_3 + Relu_4, Tactic: 2775507031594384867, 126[Float(64,56,56)] -> 129[Float(64,56,56)] [TensorRT] VERBOSE: Layer(scudnn_winograd): Conv_5 + Add_6 + Relu_7, Tactic: 2775507031594384867, 129[Float(64,56,56)], 126[Float(64,56,56)] -> 133[Float(64,56,56)] [TensorRT] VERBOSE: Layer(scudnn_winograd): Conv_8 + Relu_9, Tactic: 2775507031594384867, 133[Float(64,56,56)] -> 136[Float(64,56,56)] [TensorRT] VERBOSE: Layer(scudnn_winograd): Conv_10 + Add_11 + Relu_12, Tactic: 2775507031594384867, 136[Float(64,56,56)], 133[Float(64,56,56)] -> 140[Float(64,56,56)] [TensorRT] VERBOSE: Layer(Convolution): Conv_13 + Relu_14, Tactic: 1, 140[Float(64,56,56)] -> 143[Float(128,28,28)] [TensorRT] VERBOSE: Layer(FusedConvActDirect): Conv_15, Tactic: 8847359, 143[Float(128,28,28)] -> 210[Float(128,28,28)] [TensorRT] VERBOSE: Layer(scudnn): Conv_16 + Add_17 + Relu_18, Tactic: -4420849921117327522, 140[Float(64,56,56)], 210[Float(128,28,28)] -> 149[Float(128,28,28)] [TensorRT] VERBOSE: Layer(FusedConvActDirect): Conv_19 + Relu_20, Tactic: 8847359, 149[Float(128,28,28)] -> 152[Float(128,28,28)] [TensorRT] VERBOSE: Layer(scudnn_winograd): Conv_21 + Add_22 + Relu_23, Tactic: 2775507031594384867, 152[Float(128,28,28)], 149[Float(128,28,28)] -> 156[Float(128,28,28)] [TensorRT] VERBOSE: Layer(Convolution): Conv_24 + Relu_25, Tactic: 1, 156[Float(128,28,28)] -> 159[Float(256,14,14)] [TensorRT] VERBOSE: Layer(FusedConvActDirect): Conv_26, Tactic: 7274495, 159[Float(256,14,14)] -> 225[Float(256,14,14)] [TensorRT] VERBOSE: Layer(Convolution): Conv_27 + Add_28 + Relu_29, Tactic: 56, 156[Float(128,28,28)], 225[Float(256,14,14)] -> 165[Float(256,14,14)] [TensorRT] VERBOSE: Layer(FusedConvActDirect): Conv_30 + Relu_31, Tactic: 2621439, 165[Float(256,14,14)] -> 168[Float(256,14,14)] [TensorRT] VERBOSE: Layer(scudnn_winograd): Conv_32 + Add_33 + Relu_34, Tactic: 2775507031594384867, 168[Float(256,14,14)], 165[Float(256,14,14)] -> 172[Float(256,14,14)] [TensorRT] VERBOSE: Layer(Reformat): Conv_35 + Relu_36 input reformatter 0, Tactic: 1002, 172[Float(256,14,14)] -> Conv_35 + Relu_36 reformatted input 0[Float(256,14,14)] [TensorRT] VERBOSE: Layer(scudnn): Conv_35 + Relu_36, Tactic: 5863767799113001648, Conv_35 + Relu_36 reformatted input 0[Float(256,14,14)] -> 175[Float(512,7,7)] [TensorRT] VERBOSE: Layer(Reformat): Conv_37 input reformatter 0, Tactic: 0, 175[Float(512,7,7)] -> Conv_37 reformatted input 0[Float(512,7,7)] [TensorRT] VERBOSE: Layer(FusedConvActDirect): Conv_37, Tactic: 10682367, Conv_37 reformatted input 0[Float(512,7,7)] -> 240[Float(512,7,7)] [TensorRT] VERBOSE: Layer(Convolution): Conv_38 + Add_39 + Relu_40, Tactic: 56, 172[Float(256,14,14)], 240[Float(512,7,7)] -> 181[Float(512,7,7)] [TensorRT] VERBOSE: Layer(FusedConvActDirect): Conv_41 + Relu_42, Tactic: 10682367, 181[Float(512,7,7)] -> 184[Float(512,7,7)] [TensorRT] VERBOSE: Layer(scudnn_winograd): Conv_43 + Add_44 + Relu_45, Tactic: 2775507031594384867, 184[Float(512,7,7)], 181[Float(512,7,7)] -> 188[Float(512,7,7)] [TensorRT] VERBOSE: Layer(PoolingTiled): GlobalAveragePool_46, Tactic: 8192257, 188[Float(512,7,7)] -> 189[Float(512,1,1)] [TensorRT] VERBOSE: Layer(conv1x1): Gemm_48, Tactic: -1243792514564525921, 189[Float(512,1,1)] -> (Unnamed Layer* 49) [Fully Connected]_output[Float(1000,1,1)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
其中每一层 Layer(xxxxx) 表示了 TensorRT engine 中的 layer 构成,括号中列出了具体负责执行的算子名字,比如 scudnn、scudnn_winograd 等。而冒号后面接的形如 Conv_0 + Relu_1 的字符串反应了当前 Layer 对应的原始 ONNX 模型中的节点,所以可以看到 TensorRT 进行了算子融合。
这里还有一款用于TensorRT可视化的工具:https://github.com/pytorch/pytorch/pull/66431/files。
关于 reformat 层
reformat 层是用于数据格式转换的,比如上一层输出为 FP32,而下一层输入要求 INT8,那么 TensorRT 就会在这两层之间加入 reformat,用于完成数据转换。
安装
事实上如果只是需要使用 TensorRT GA 部分的功能,还可以通过 pip 指令直接安装。但是如果还想使用 TensorRT 配套的一些其它工具,还是需要从官网下载 TensorRT 压缩包安装。
pip install nvidia-pyindex pip install nvidia-tensorrt- 1
- 2
-
相关阅读:
可以免费发外链的论坛有哪些?
基于C51控制蜂鸣器
Hadoop总结
新员工webpack打包后上传服务器页面空白
一文讲明白Java中线程与进程、并发与并行、同步与异步
android.mk介绍
QProgressDialog自动弹出的问题
export LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH的作用
保健食品市场前景如何?
V8中的快慢数组(附源码、图文更易理解😃)
- 原文地址:https://blog.csdn.net/qq_39523365/article/details/126779132
