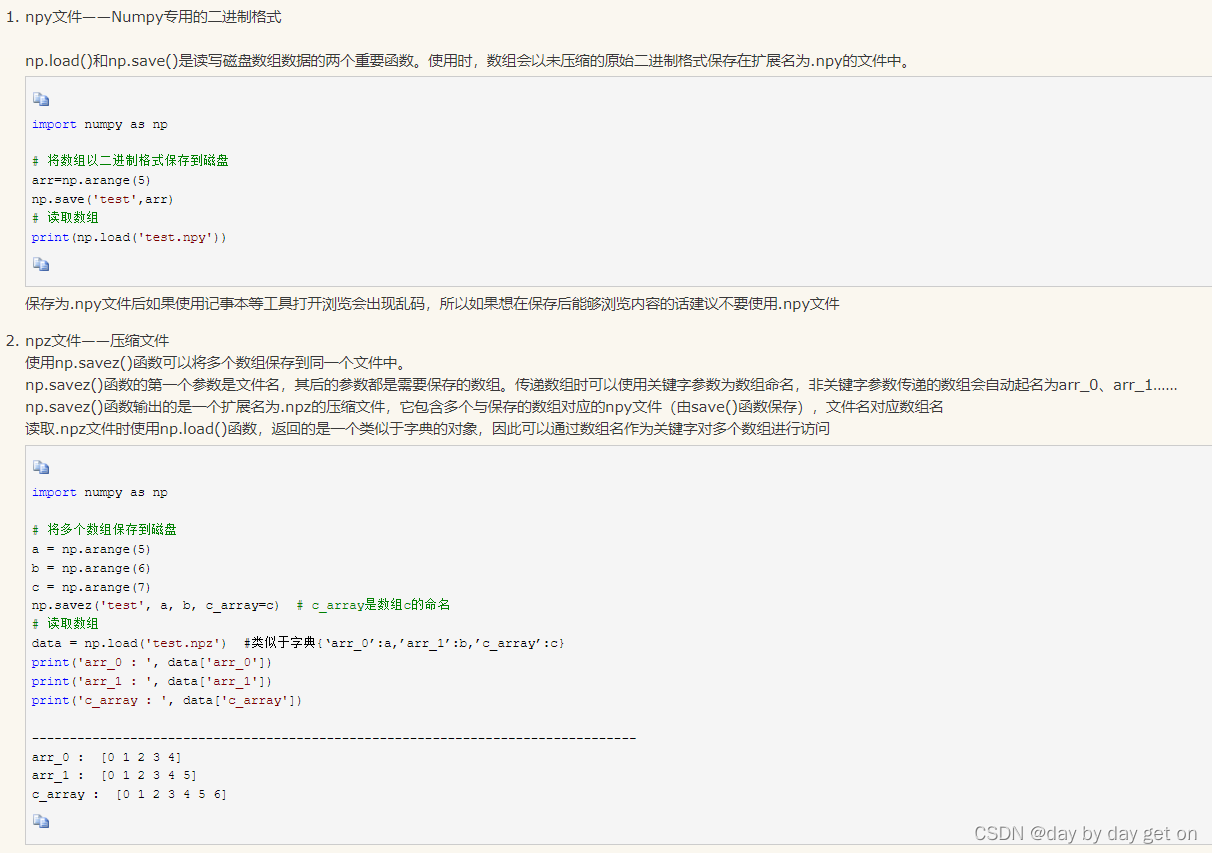
-
npy和npz里的图片分解(格式讲解)!超级清晰版本
一、npy文件的处理
1.测一下文件的规格大小
在分解转换前 要知到你的npy文件包含几个文件!!(多少规格大小数组)
即:图片张数,水平尺寸和垂直尺寸
代码如下:import numpy as np arr = np.load("F:/DATA/test/2.npy") # npy文件的路径 print(arr.shape) # 输出 .npy 文件的大小 # print(arr) # 直接输出 .npy 文件- 1
- 2
- 3
- 4
然后判断 哪一个是张数。也有可能是四维的,就是两重循环,一般是第一个是总张数,第二个是每一个小类别的张数(一般是3、5张),后面两个数字是图片的规格,即水平尺寸和垂直尺寸
2.npy_png转换
代码如下:
import matplotlib.pyplot as plt import numpy as np import scipy.misc import os file_dir = "F:/DATA/test/" # npy文件路径 dest_dir = "F:/DATA/test1/" # 文件存储的路径 folder = os.listdir(file_dir) print("11: ") print(folder) def npy_png(file_dir, dest_dir): # 如果不存在对应文件,则创建对应文件 if not os.path.exists(file_dir): os.makedirs(file_dir) if not os.path.exists(dest_dir): os.makedirs(dest_dir) for files in folder: file = file_dir + files # npy文件 print('22:'+file) fname= os.path.splitext(files)[0]#去掉文件后缀 print('33:'+fname) con_arr = np.load(file) # 读取npy文件 for i in range(0, 5): # 循环数组 三维数组分别是:图片张数 水平尺寸 垂直尺寸 arr = con_arr[:, :,i] # 获得第i张的单一数组 disp_to_img = np.reshape(arr, [256,256]) # 根据需要的尺寸进行修改 #disp_to_img = scipy.misc.imresize(arr, [256,5]) 这种我弄出不来可能包没装好吧 plt.imsave(os.path.join(dest_dir, str(fname)+'{}.png').format(i), disp_to_img, cmap='gray') # 定义命名规则,保存图片为灰白模式 print('photo finished') if __name__ == "__main__": npy_png(file_dir, dest_dir)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
https://qianlingjun.blog.csdn.net/article/details/115726615
https://blog.csdn.net/qq_43225437/article/details/86589892
https://blog.csdn.net/weixin_44774262/article/details/118060429?spm=1001.2014.3001.5502
最后我想分解四维的 分解成功了一个 但是另一个就是应为图片量太大 一维数值已经超过了1e9
跑不了 我就没分解masks的npy了。
我觉得很有意思啊,把图片利用矩阵压缩降维保存。二、npz文件的处理
1.原理:
参考这篇博客
之前我一直 没办法解析里面的东西
结果 把他当作字典遍历一遍就可以找到啦
:https://www.cnblogs.com/Lilu-1226/p/9768368.html
遍历字典:
https://www.zhihu.com/question/3913238362.代码:npz_png
import matplotlib.pyplot as plt import numpy as np import os from matplotlib.pyplot import cm cmap = cm.gray path = "F:/DATA/test/optic-2.npz" data = np.load(path) #返回类似与字典的对象 for dic in data: #打印字典里的列表名 print(dic) img_data = data['imgs'] seg_data = data['labs'] con_arr = seg_data dest_dir = "F:/DATA/test/labs" # 文件存储的路径 def npy_png(dest_dir): #如果不存在对应文件,则创建对应文件 if not os.path.exists(dest_dir): os.makedirs(dest_dir) for j in range(0,125): print(j) for i in range(0, 1): # 循环数组 三维数组分别是:图片张数 水平尺寸 垂直尺寸 arr = con_arr[j,i,: , :] # 获得第i张的单一数组 disp_to_img = np.reshape(arr, [512,512]) # 根据需要的尺寸进行修改 #disp_to_img = scipy.misc.imresize(arr, [256,5]) plt.imsave(os.path.join(dest_dir, str(j)+'{}.png').format(i), disp_to_img, cmap=cm.gray) # 定义命名规则,保存图片为灰白模式 print('photo finished') if __name__ == "__main__": npy_png(dest_dir)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
说明:
应为我的npz中有两个npy列表 一个是imgs 一个是labs
所以分别找这两个地size 发现他有多少个npy文件 每一轮有多少张图片 以及图片地尺寸
改这句话就行:con_arr = seg_data- 1
3.求列表npy的size的代码:
mport numpy as np #arr = np.load("F://DATA//test//optic-0.npz") # npy文件的路径 path = "F:/DATA/test/optic-2.npz" data = np.load(path) #返回类似与字典的对象 #类似于: 字典{'dict_0': {'1':'!','2':'b','3':'c'},'dict_1': {'1':'!','2':'b','3':'c'}, 'dict_2': {'1':'!','2':'b','3':'c'},} #字典就是键(key),字典内容就是值(value),然后用for循环遍历字典的键 for dic in data: #打印字典里的列表名 print(dic) img_data = data['imgs'] seg_data = data['labs'] print(img_data.shape) # 输出 .npy 文件的大小 print(seg_data.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
重点是这两句:
print(img_data.shape) # 输出 .npy 文件的大小
print(seg_data.shape)npy的 size函数测试结果:

-
相关阅读:
【UVM入门 ===> Episode_9 】~ 寄存器模型、寄存器模型的集成、寄存器模型的常规方法、寄存器模型的应用场景
如何找到联盟营销人员:招募合适会员的10个方法
【优选算法系列】第二节.双指针(202. 快乐数和11. 盛最多水的容器)
BI-SQL丨MEGRE
携一站式全品类、全场景智慧出行解决方案,移远通信精彩亮相2023摩博会
开学季征文 | 一位开发实习生的真情流露
vue实现上传文件到七牛云
SaaSBase:什么是Flomo?
驱动开发:内核监控Register注册表回调
网络编程——socket定义和地址格式
- 原文地址:https://blog.csdn.net/qq_52626583/article/details/126683720
