-
NR 物理层编码 S2 - 线性码
参考:
这里主要增加了 pyhton部分
目录
1: 码距
2: 线性分组码性质
3: 纠错检错能力
4: 生成矩阵和监督矩阵
5: 伴随式和校正子
一 码距
码距
许用码字之间的距离称为码字
汉明距离
两个n元码字两者之间的汉明距离为D
码字1:

码字2:


二 线性分组码性质
1.1 重要定义
1.2 重要性质
自反性
比如

对称性

三角不等式
比如码字


- # -*- coding: utf-8 -*-
- """
- Created on Tue Sep 6 11:11:40 2022
- @author: chengxf2
- """
- import torch
- '''
- 求汉明距离
- args
- w1: 许用码字1
- w2: 需用码字2
- '''
- def module(w1,w2):
- w1 = torch.ByteTensor(w1)
- w2 = torch.ByteTensor(w2)
- num = w1.shape[0]
- dist = 0
- for index in range(num):
- a = w1[index]
- b = w2[index]
- c =a^b
- if c>0:
- dist = dist+1
- print("\n 汉明距离 :",dist)
- w1 = [1,1,0]
- w2= [1,0,1]
- module(w1,w2)
三 纠错和检错能力
3.1 若线性分组码能检测出任一码字中的小于等于r位错误,则应满足

原理:
假设发送码字为C, 发送了r位错误,满足上面条件,则接收到的码字
肯定就在禁用码字集合中,不属于许用码字集合。
如下列,最小码距为2的spc码
许用码字集合为
000 110 011 110
当发送110时候,接收方收到的数据有一位发送错误
变成了001,100 ,111 此刻都在禁用码字集合中,能够发现错误。

3.2 若线性分组码能纠正任一码字中小于等于t位误码,则

纠错的原理是码距最近原则:

同样如上图,当收到100的时候,出错了,但是这个时刻
100 距离 110 ,000 码距都是1,此刻无法判断出到原码字到底是
哪个.
所以它的约束条件需要满足

这个译码设计原则需要特别注意,它有的场景和概率论里面的二项分布是冲突的.
3.3 检错+纠错

四 生成矩阵和监督矩阵

4.1 生成矩阵
输入的二进制bit流 用向量
![u=[u_1,u_2,..u_k]](https://1000bd.com/contentImg/2023/11/04/115054796.png) 表示
表示通过生成矩阵G得到码字

![c=[c_1,c_2,..c_n]](https://1000bd.com/contentImg/2023/11/04/115056352.png)
系统生成矩阵原理

G=[I,Q] 大小 [k,n]
I : 取原来信息,Q 主要作用监督


.....

4.2 校验矩阵
原理


![H=[Q^T,I_{r}]](https://1000bd.com/contentImg/2023/11/04/115056668.png)
例

Q1 输入 u[1101] ,求输出的码字
![=[1101001]](https://1000bd.com/contentImg/2023/11/04/115055043.png)
Q2:接收到的码字为[1101 010] 问是否出错
 [011]
[011] 出错
五 伴随式和校正子
5.1 架构
 编码矩阵G(k,n),监督元长度r=n-k
编码矩阵G(k,n),监督元长度r=n-k错误图样:
![E=[e_1,e_2,...e_n]](https://1000bd.com/contentImg/2023/11/04/115056314.png) 信道传输带来的随机噪声
信道传输带来的随机噪声接收码字

伴随式(校正子)



为[r,1] 的向量,则对应
 种组合,每一种组合叫做一个校正子
种组合,每一种组合叫做一个校正子5.2 检错原理
![s \neq [o]_r](https://1000bd.com/contentImg/2023/11/04/115058316.png) 肯定发送错误
肯定发送错误![s=[0]_r](https://1000bd.com/contentImg/2023/11/04/115057203.png) 不一定传输正确
不一定传输正确因为如果E 也是许用码字,

5.3 纠错原理
根据S的结果,查表得到E,根据E,利用下面公式推导出原来发送的码字

5.4 标准阵
收到的信息 认为是 R=C+E
当发生错误的时候,可以根据R的标准阵直接查表得到C,
其中陪集首代表只有1位发生错误的错误图样

七 例子:
已知(6,3)系统编码矩阵G

1: 求校验矩阵H

2: 分析误码差错控制能力
因为H中 任意两列不相同,3列线性相关,
![[110]+[101]=[011]](https://1000bd.com/contentImg/2023/11/04/115057701.png)
所以
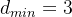 ,则
,则检错能力为2, 纠错能力为1
见程序
3: 1位误码所有的错误图样
见程序
E[1]: [1, 0, 0, 0, 0, 0] 错误图样 S[1]: [1, 1, 0]
E[2]: [0, 1, 0, 0, 0, 0] 错误图样 S[2]: [1, 0, 1]
E[3]: [0, 0, 1, 0, 0, 0] 错误图样 S[3]: [0, 1, 1]
E[4]: [0, 0, 0, 1, 0, 0] 错误图样 S[4]: [1, 0, 0]
E[5]: [0, 0, 0, 0, 1, 0] 错误图样 S[5]: [0, 1, 0]
E[6]: [0, 0, 0, 0, 0, 1] 错误图样 S[6]: [0, 0, 1]
4 写出所有的错误图样
- # -*- coding: utf-8 -*-
- """
- Created on Thu Sep 8 11:04:28 2022
- @author: chengxf2
- """
- import numpy as np
- '''
- 模二加法
- '''
- def module(u,g):
- n = np.dot(u,g.T)
- #print("\n n: ",u,g)
- return n%2
- '''
- 编码过程
- '''
- def encode(u,G):
- G = np.array(G)
- u = np.array(u)
- k,n = G.shape[0],G.shape[1]
- #print("\n k: %d n: %d"%(k,n))
- code =[]
- for index in range(n):
- g = G[:,index]
- if index<k:
- a = u[index]
- else:
- a = module(u,g)
- code.append(a)
- return code
- '''
- 译码过程
- '''
- def decode(E,H):
- E= np.array(E)
- H = np.array(H)
- m,n = np.shape(H)
- S =[]
- for index in range(m):
- p = H[index,:]
- r = module(E,p)
- S.append(r)
- return S
- if __name__ =="__main__":
- uList =[[0,0,0],
- [0,0,1],
- [0,1,0],
- [1,0,0],
- [0,1,1],
- [1,1,0],
- [1,1,1]]
- G = [[1,0,0,1,1,0],
- [0,1,0,1,0,1],
- [0,0,1,0,1,1]]
- H = [[1,1,0,1,0,0],
- [1,0,1,0,1,0],
- [0,1,1,0,0,1]]
- for u in uList:
- code =encode(u,G)
- print("\n 信息: ",u,"\t 输出码字: ",code)
- EList =[[1,0,0,0,0,0],
- [0,1,0,0,0,0],
- [0,0,1,0,0,0],
- [0,0,0,1,0,0],
- [0,0,0,0,1,0],
- [0,0,0,0,0,1]]
- for E in EList:
- S =decode(E,H)
- print("\n E, ",E,"\t S",S)
4 假设收到的码字为[001110],求正确码字为

=[1,0,1]
查表得到E
E[2]: [0, 1, 0, 0, 0, 0] 错误图样 S[2]: [1, 0, 1]
![=[0,1,0,0,0,0]+[0,0,1,1,1,0]](https://1000bd.com/contentImg/2023/11/04/115054740.png)
=[0,1,1,1,1,0]
-
相关阅读:
项目问题——Error during artifact deployment. See server log for details.
TDengine:无模式写入行协议的四种方式
【redis】ssm项目整合redis,redis注解式缓存及应用场景,redis的击穿、穿透、雪崩的解决方案
Calibre license问题
通用的改进遗传算法求解带约束的优化问题(MATLAB代码)
一个使用uniapp+vue3+ts+pinia+uview-plus开发小程序的基础模板
【微服务】SpringBoot整合Resilience4j使用详解
Vue - 得到组件渲染的DOM
zephyr-os 线程
ARM---day02
- 原文地址:https://blog.csdn.net/chengxf2/article/details/126720871
