-
Python学习备忘录
#温柔的大蟒蛇
Python是我非常喜欢的语言,正所谓“人生苦短,我用Python”,我学过C和Java,后来又学习了Python,当我接触到它的时候,我就感觉似乎是遇到了一条温柔的大蟒蛇。
##再学Python
正所谓“好记性不如烂笔头”,自己工作上用Python的机会不多,而Python又是我的立身之本(前面两句话似乎是反义句),所以我要写一篇文章来记录我每日学习到的Python知识,作为我的学习笔记。
###2022年9月8日学习笔记
1、通过实现特殊方法,自定义对象类型可以表现得和Python的内置类型一样,从而让我们写出更具表达力的代码,或者说更具Python风格的代码。
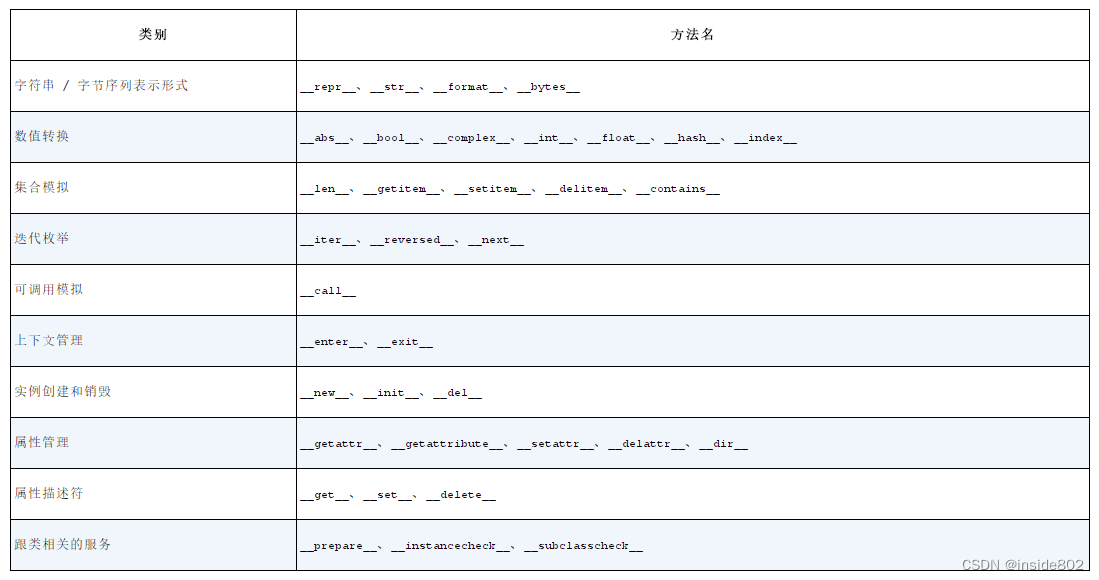

2、数据类型——序列
2.1、序列的类型
序列根据可存放数据的不同,分为容器序列和扁平序列。
容器序列有:list、tuple、collection.deque。这类序列可以存放不同类型的数据。
扁平序列有:str、bytes、bytearray、memoryview、array.array。这类序列只能容纳一种类型。
**容器序列中存放的是它所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用。**换句话说,扁平序列其实是一段连续的内存空间,它里面只能存放字符、字节和数值这种基础类型。序列根据能否修改,分为可变序列和不可变序列。
可变序列有:list、bytearray、array.array、collection.deque、memoryview。
不可变序列有:tuple、str、bytes。2.2、常用序列—列表
2.2.1列表推导
列表推导的作用只有一个:生成列表。
eg:
tshirts = [(color, size) for color in colors for size in sizes]
str_nums = [ str(x) for x in nums]2.3、常用序列—元组
2.3.1元组拆包
元组的特点除了我们常说的不可变,还记录了元素的位置信息。利用元素的位置信息,我们可以使用元组拆包的功能。元组拆包,可以让我们方便的进行赋值、取值、交换值等操作。唯一的硬性要求是,元素的个数必须匹配。
如:
1、赋值:name, age, city, salary = (‘Jack’, 30, ‘Beijing’, 2000)
2、取值:infos = (‘Baobao’, 2, ‘China’, 3000)
print(‘%s, %d, %s, %d’ %infos)
3、交换:a, b = b, a
4、在不确定参数个数的情况下,可以使用*arg的方法进行平行赋值:
a, b, *rest = range(5)
print(a, b, rest) -->(0, 1, [2,3,4])
a, b, *rest = range(2)
print(a, b, rest) -->(0, 1, [])
a, b, *rest, c, d = range(5)
print(a, b, rest) -->(0, 1, [2], 3, 4)
###2022年9月9日学习笔记
2.3.2 具名元组
collections.namedtuple是一个工厂函数,它可以用来创建一个带字段名的元组和一个有名字的类。用namedtuple构建的类的实例所消耗的内存和元组是一样的,因为字段名都被存在的对应的类里面。这个实例和普通的对象比起来要小一些,因为Python不会用__dict__来存放这些实例的属性。
创建一个具名元组需要两个参数,一个是类名,一个是类的各字段的名字。后者可以是一个可迭代的对象(要求该迭代对象元素均为字符串),或者是由空格隔开的字段名组成的字符串。
创建具名元组
Thirts_a = collections.namedtuple(‘Thirts_a’, [‘color’, ‘size’])
Thirts_b = collections.namedtuple(‘Thirts_b’, ‘color size’)
实例化具名元组
my_shirt = Thirts_a([‘yellow’, 175)
your_shirt = Thirts_b(‘yellwo’, 175)
使用具名元组,可以调用具名元组实例的属性值。(Python自带了一些具名元组专用的方法,只是我目前还没有理解)
print(my_shirt.color, my_shirt.size)
print(your_shirt.color, your_shirt.size)
###2022年9月17日学习笔记
2.4、番外——切片
在Python中,列表、元组、字符串这些序列类型都支持切片。
2.4.1 切片赋值
如果把切片放在了等号的左边,可以对切片的值进行修改;如果把切片作为del的对象,则可以进行删除。list1 = list(range(10))
list1
[0,1,2,3,4…9]
list1[2:5] = [20,30]
list1
[0,1,20,30,5,6,7,8,9] 注意这里既修改了值,也删除了第4个值(从0数)
del list1[5:7]
list1
[0,1,20,30,5,8,9]
list1[3::2] = [11,22]
list1
[0,1,20,11,5,22,9] 注意这种每隔n个替换的赋值不能做删除操作,必须保证可替换位置与等号右边的元素个数一致,否则会报错。2.5 列表的列表
初始化一个嵌套着几个列表的列表,最好的选择是会用列表推导,不要直接使用[ [ ]*3 ] *3这种写法。
正确做法:
board = [ [ ‘’ ] * 3 for i in range(3) ]
错误做法:
board = [ [ '’ ] * 3 ] * 3
正确的做法相当于:
board = [ ]
for i in range(3):
row = [ ‘’ ] * 3
board.append(row)
错误的做法相当于:
board = [ ]
row = [ '’ ] *3
for i in range(3):
board.append(row)
2.6、番外——非常有用的bisect
bisect模块有两个主要的函数,bisect和insort,两个函数都利用二分查找法来在有序的序列中查找或者插入元素。
bisect.bisect(seq,item):在有序序列seq中查找item的位置。该位置满足的条件是,将item插入到这个位置之后,还能保持seq的升序,也就是说这个函数返回的位置前面的值,都小于等于item。如果seq中存在于item相等的值X,则视item的位置在X之后。
bisect.bisect_left(seq,item):在有序序列seq中查找item的位置。该位置满足的条件是,将item插入到这个位置之后,还能保持seq的升序,也就是说这个函数返回的位置前面的值,都小于item。如果seq中存在于item相等的值X,则视item的位置在X之前。bisect.insort(seq,item):将item插入到有序序列seq中,且保持seq的升序。如果seq中存在于item相等的值,则将item插入到该值之后。
bisect.insort_left(seq,item):将item插入到有序序列seq中,且保持seq的升序。如果seq中存在于item相等的值,则将item插入到该值之前。上述4个函数,还有两个可选参数,lo、hi,lo默认值为0,hi默认值为序列的长度,这两个参数可以控制搜索的范围。
2.7、选择合适的数据类型
如果存放1000万个浮点数的话,数组array.array的效率要高得多,因为数组在背后存的并不是float对象,而是数字的机器翻译。
如果需要频繁对序列做先进先出的操作,deque的速度会更快。
如果包含(in)操作的频率很高,用set更合适。set不是序列,它是无序的。2.8、序列——双向队列和其他形式的队列
使用列表的.append和.pop方法,也可把列表当做队列来使用,但是这类操作很耗时,因为这些操作会牵扯到移动列表里的所有元素。
collections.deque类(双向队列)是一个线程安全,可以快速从两端添加或者删除元素的数据类型。
from collection import deque
dq = deque(range(10), maxlen=10) //maxlen是一个可选参数,代表这个队列可容纳的元素数量,设置后就不能更改了
print(dq)
deque([0,1,2,3,4,5,6,7,8,9],maxlen=10)
dq.rotate(3) //将队列最右边的3个元素移动到队列左边
dq.rorate(-3) //将队列最左边的3个元素移动到队列右边
dq.appendleft(-1) //在队列左边添加元素-1,因队列已满,所以队列最右边的元素会被移出队列
dq.extend([11,22,33]) //在队列右边依次添加11,22,33,因队列已满,所以队列最左边3个元素会被移出队列
print(dq)
deque([3,4,5,6,7,8,9,11,22,33], maxlen=10)
dq.extendleft([10,20,30,40]) //在队列左边依次添加10,20,30,40,注意添加完以后,40在最外头,10在里头。
print(dq)
deque([40,30,20,10,3,4,5,6,7,8], maxlen=10)
dq.pop() //将队列最右边的元素弹出
dq.popleft() //将队列最左边的元素弹出queue模块提供了同步(线程安全)类Queue、LifoQueue和PriorityQueue,不同的线程可以利用这些数据类型来交换信息。这三个类的构造方法都有一个可选参数maxsize,它接受正整数作为输入值,用来限定队列的大小。但是在满员的时候,这些类不会扔掉旧的元素来腾出位置。如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而腾出位置。这一特性让这些类很适合用来控制活跃线程的数量。
###2022年10月1日
专家建议:
虽然列表里能存放不同类型的元素,但是实际上这样做并没有什么好处。我们之所以用列表来存东西,是期待以后再使用它的时候其中的元素有一些通用的特性(比如,列表里存的是一类可以“呱呱”叫的动物,那么所有元素都应该会发出这种叫声,即便其中一部分元素类型并不是鸭子)。在Python3中,如果列表里的东西不能比较大小,那么我们就不能对列表进行排序。
元组恰恰相反,它经常用来存放不同类型的元素。这也符合它的本质,元素就是用作存放彼此之间没有关系的数据的记录。3 字典
3.1 Python标准库中,所有的映射类型都是利用dict来实现的,因此它们有个共同的限制,即只有可散列的数据类型才能用作这些映射里的键。
什么是可散列的数据类型?
在Python词汇表中,关于可散列对象的定义有以下三个要点:
1)在这个对象的生命周期中,它的散列值是不变的,
2)这个对象要实现__hash__()方法
3)这个对象要实现__qe__()方法
原子不可变数据类型(str、bytes和数值类型)都是可散列类型,frozenset也是可散列的,因为根据其定义,frozenset里只能容纳可散列类型。元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。3.2 字典的构造方法有很多:
a = dict(one=1, two=2, three=3) //注意,这里的one、two、three没有引号
b = {‘one’:1, ‘two’:2, ‘three’:3}
c = dict(zip([‘one’, ‘two’, ‘three’], [1, 2, 3]))
还有其他两个构造方法,太复杂,不值得记忆。###2022年10月2日
3.3字典推导INFO = [
(‘Lily’, 29),
(‘Jack’, 28),
(‘Tom’, 30)
]
info_all = {name:age for name,age in INFO}
print(info_all)
{‘Lily’: 29, ‘Jack’: 28, ‘Tom’: 30}
info_young = {name.upper():age for name,age in info_dict.items() if age<30 } //筛选出年龄小于30的人
print(info_young)
{‘Lily’: 29, ‘Jack’: 28}3.4 常见的映射方法
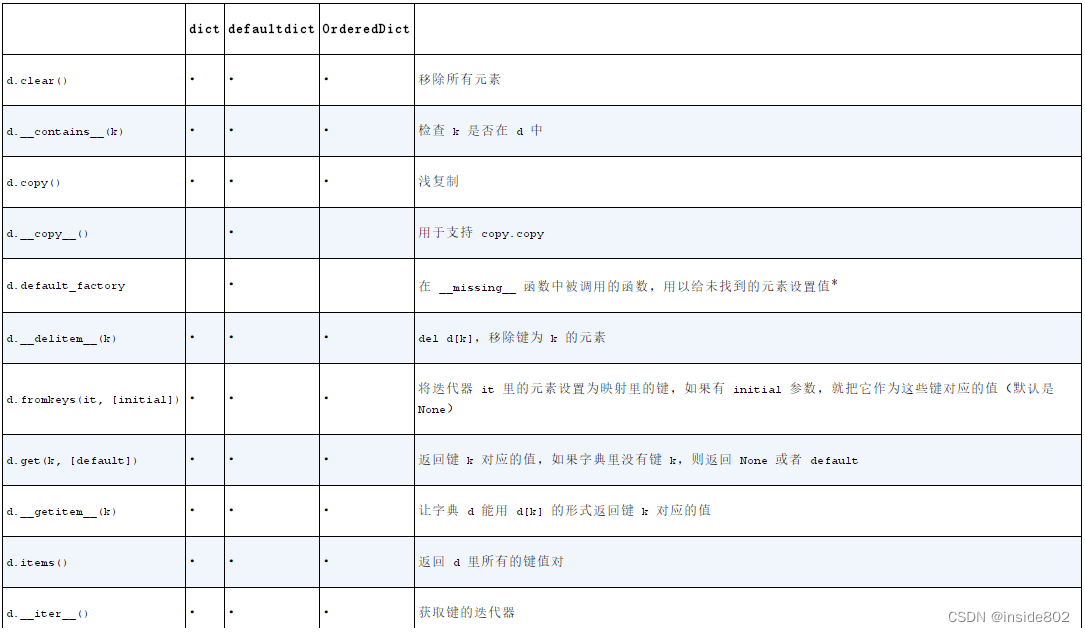
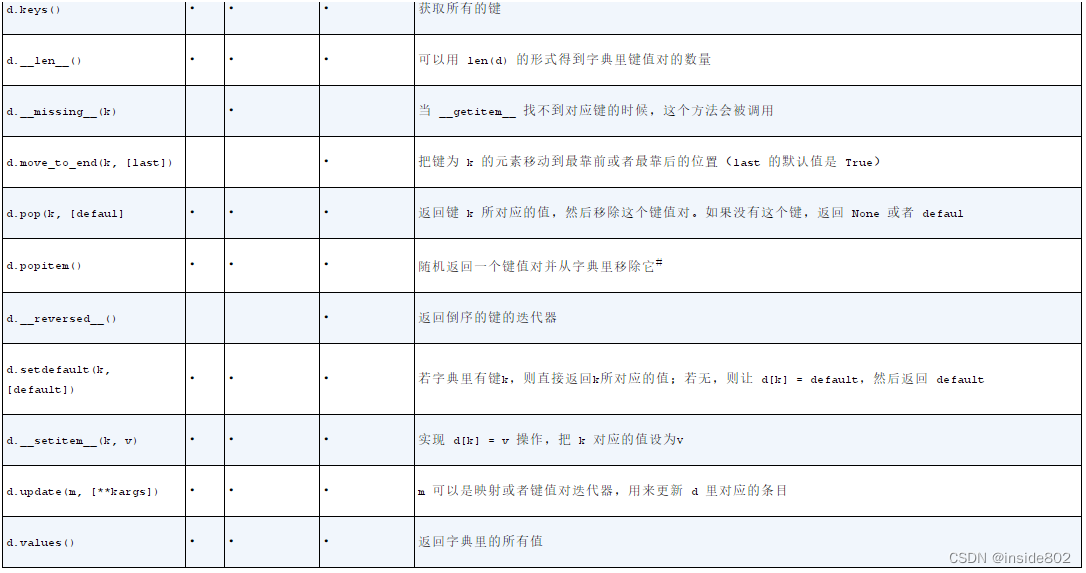
这里重点对d.setdefault(k, [default])做一个深度讲解:
在实际代码中,我们常常做这样一个操作:创建一个字典,并创建(key,value)。如果key在字典中已经存在,则对这个key的value做对应的操作(如添加位置信息,或者value+1等),如果这个key不存在,则先创建key并设置其初始值。
对于上述场景,一般情况下,我们会这样操作:先查询key是否存在,如果不存在,则在字典里添加key,并对其值初始化,然后在对value做对应的操作(如添加位置信息,或者value+1等)。
但是我们可以用d.setdefault(k, [default])函数一步到位就实现。setdeault就是直接设置key的value值,如果key不存在,则初始化k的值为default。
举个例子:
我们获取某个公司里不同年龄下的员工信息,设置字典名称为infos,key为年龄,value为姓名。
一般情况下,如果我们统计到一个28岁的Jack,我们会这样操作,
names = infos.get(28, [ ])
names.append(‘Jack’)
infos[28] = names
甚至会这样写:
if 28 not in infos.keys:
infos[28] = [‘Jack’]
else:
infos[28].append(‘Jack’)
而如果用setdeault()函数,我们可以这样写:
infos.setdefault(28, [ ]).append(‘Jack’)当key在字典中不存在,使用d[key]必然会抛出异常,如果实现了__missing__特殊方法,则当key在字典中不存在时,则会调用__missing__方法,而不是抛出一个异常。注意__missing__只会被__getitem__调用(比如d[key]操作),对get或者__contains__(in运算符会用到这个方法)这些方法没有影响。
3.5字典的变种
collections.OrderedDict:这个类型在添加键的时候会保持排序,因此键的迭代次序总是一致的。OrderedDict的popitem方法默认删除并返回的是字典里的最后一个元素。但是如果像my_odict.popitem(last=False)这样调用它,那么它删除并返回第一个被添加进去的元素。collections.Counter:这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。Counter实现了+和-运算符用来合并记录,还有像most_common([n])这类很有用的方法。
举个例子:import collections
ct = collections.Counter(‘abracadabra’)
print(ct)
Counter({‘a’: 5, ‘b’: 2, ‘r’: 2, ‘c’: 1, ‘d’: 1})
ct.update(‘aaaaazzz’)
print(ct)
Counter({‘a’: 10, ‘z’: 3, ‘b’: 2, ‘r’: 2, ‘c’: 1, ‘d’: 1})
print(ct.most_common(2))
[(‘a’, 10), (‘z’, 3)]注意:不要在迭代循环dict的同时往里添加元素。
4、集合
4.1 集合的本质
集合在python2.6中才成为内置类型,包含set和frozenset。集合的本质是许多唯一对象的聚集。集合中的元素必须是可散列的,set类型本身是不可散列的,但是frozenset可以。4.2 集合的基本操作
给定两个集合a和b,a | b返回的是它们的合集,a & b返回的是它们的交集,而a - b返回的是差集。4.3定义集合
如果集合非空,则写为{1}、{1, 2}即可,如果为空集,则必须写为set()形式,如果用{ },则python会认为这是一个空字典。4.4集合推导
my_set = {i for i in range(10) if i%2==0}4.5集合的操作
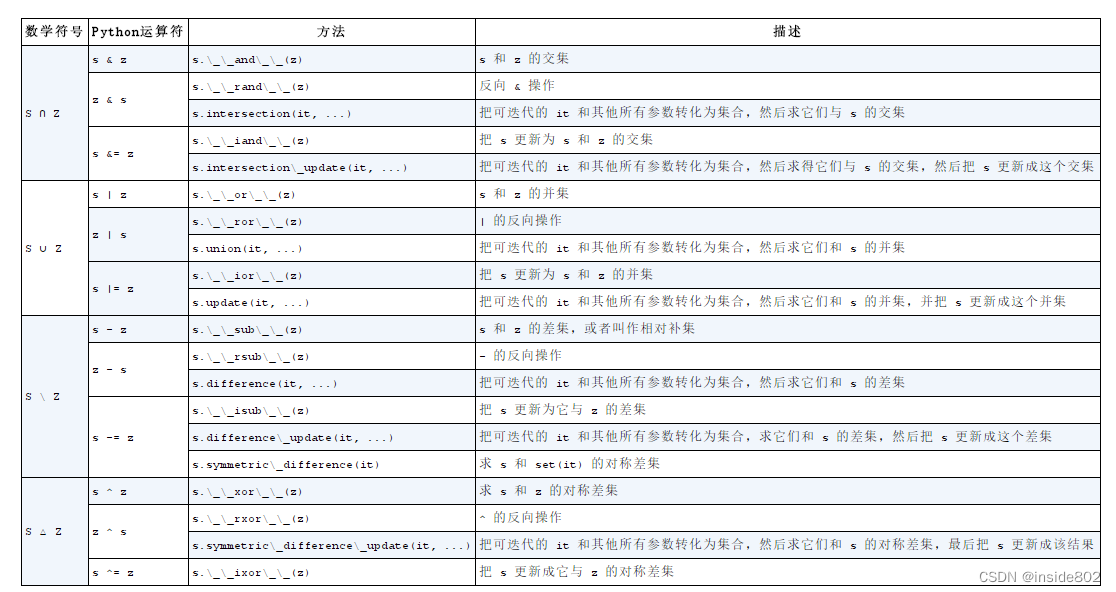
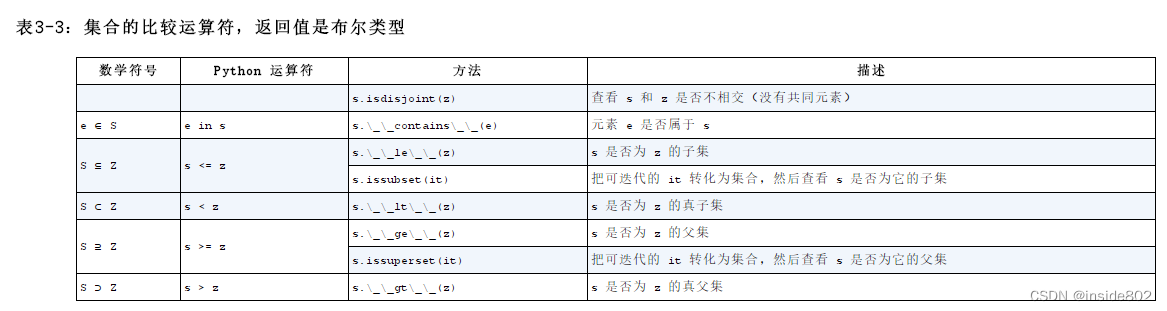

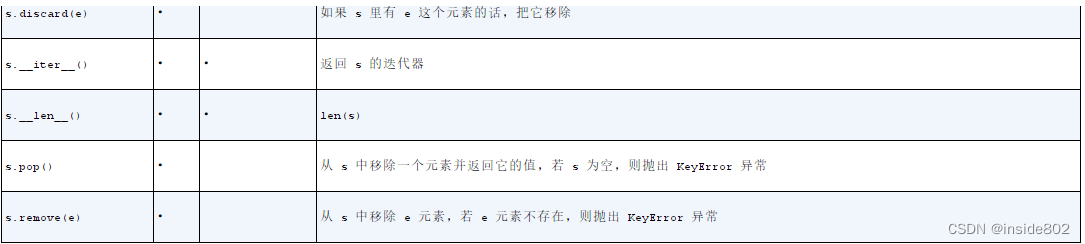
注意:不要在迭代循环set的同时往里添加元素。5、编码
注意:
1)、需要在多台设备中或者多种场合下运行的代码,一定不能依赖默认编码。打开文件时应明确传入encoding=参数,因为不同的设备使用的默认编码不同,有时隔一天也会发生变化。
2)、不区分大小写的字符串比较应使用str.casefold(),而不是str.lower()。因为str.lower()会把某些不同的特殊符号转为一样的值。(特殊符号比较难打出来,我在这里就不打了。一个是微符号,一个是德语)
3)、在处理多语言软件时,需要重点把《流畅的python》第4章好好看看。6、函数
6.1 在Python中,函数是一等对象。一等对象满足以下条件的程序实体:
1)在运行时创建;
2)能赋值给变量或数据结构中的元素;
3)能作为参数传给函数;
4)能作为函数的返回结果。
这意味着,在Python中,函数的地位和整数、字符串、字典是一样的,都是一等公民。6.2 高阶函数
接收函数为参数,或者把函数作为结果返回的函数就是高阶函数。
map、filter、reduce、sorted都是为人熟知的高阶函数。但是由于引入了列表推导和生成器表达式,它们显得没那么重要了。
这里说一下reduce的原理:
它的关键思想是,把一系列归约为单个值。reduce()函数的第一个参数是接收两个参数的函数,第二个参数是一个可迭代的对象。假如有个接受两个参数的fn函数和一个lst列表。调用reduce(fn, lst)时,fn会应用到第一对元素上,即fn(lst[0], lst[1]),生成第一个结果r1。然后,fn会应用到r1和下一个元素上,即fn(r1, lst[2]),生成第二个结果r2。接着,调用fn(r2, lst[3]),生成r3…直到最后一个元素,返回最后得到的结果。
reduce函数还有第3个参数initiaizer,它可以指定reduce归约的起始值,也可以避免第二个参数中可迭代对象为空时的异常。
下面这个例子是用reduce求阶乘
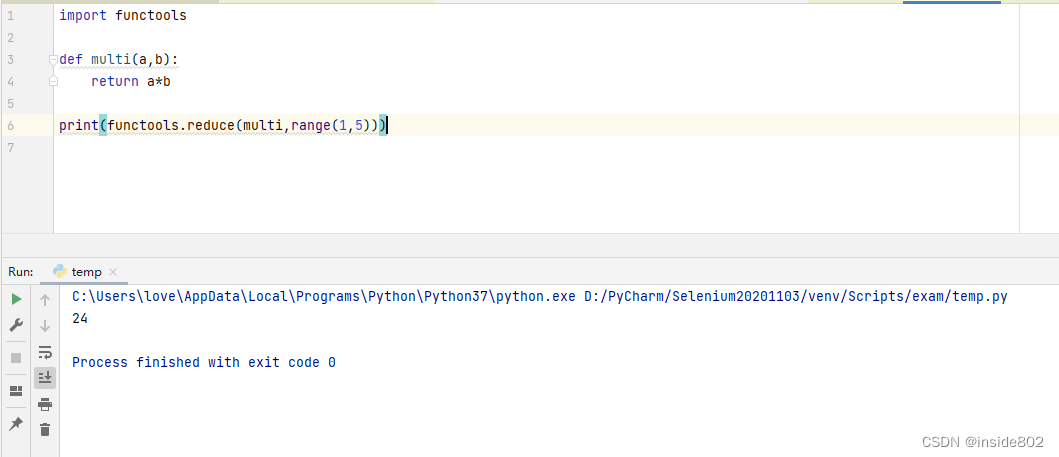
6.3匿名函数
lambda关键字在Python表达式内创建匿名函数。
lambda函数的定义体中不能赋值,也不能使用while和try等python语句。
在参数列表中最适合使用匿名函数。
lamda word:word[::-1] 等同于:
def reverse(word):
return word[::-1]6.4任何Python对象都可以表现得像函数
只需要实现__call__特殊方法,就可以让python对象表现地像函数。
构造一个类MyClass,它的实例为my_case = MyClass(),然后在MyClass中实现__call__特殊方法,则它的实例就可以直接用my_case()了。
举个例子,我们写一个狗的类,我们希望它的实例可以用()符号直接返回狗的名字,而不用调用get_name()方法,那我们可以这样写:
class Dog:
def init(self, name, age):
self.name = name
self.age = age
def get_name(self):
return self.name
def get_age(self):
return self.age
def call(self):
return self.get_name()
my_dog = Dog(‘Jack’, 2)
#这里直接使用()符号,就可以直接获取狗的名字,而不用调用get_name()方法
print(my_dog())
‘Jack’6.5函数内省
使用dir()函数可以看到函数对象的属性。函数大多数属性是Python对象共有的,也有一些是函数独有的属性。(现在我还看不懂这些独有的属性的意义,等以后看懂了再补充)

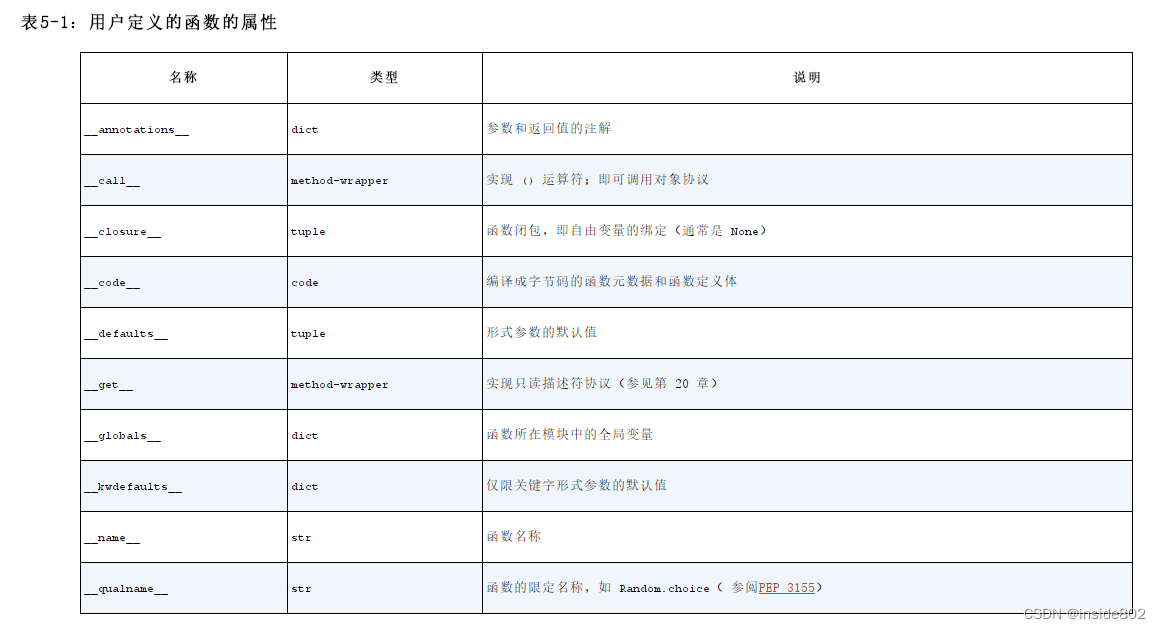
6.6函数的参数
函数的参数分为定位参数、仅限关键字参数、*、**参数
举个例子:
def tag(name, *content, cls=None, **attrs):
print(‘name=’,name)
print(‘content=’,content)
print(‘cls=’,cls)
print(‘attrs=’,attrs)tag(‘p’, ‘hello’, ‘boy’, cls=‘man’, id=33, age=22)
输出结果为:
name= p
content= (‘hello’, ‘boy’)
cls= man
attrs= {‘id’: 33, ‘age’: 22}第一个参数为定位参数,即只要是函数的第一个参数就一定会传给name,
第一个参数后面的任意个参数会被content捕获,存入一个元组
cls参数为仅限关键字参数,它不会被content捕获,想要给cls传值必须写明cls=XX
没有明确指定名称的关键字参数会被attrs捕获,存入一个字典
注意给函数传参时,仅限关键字参数的位置可以随意变化,但是*content参数和attrs参数的相对位置不能变,否则会报错。
如:tag(‘p’, ‘hello’,‘boy’, age=22,cls=‘man’, id=33)是合法的,而tag(‘p’, ‘hello’, age=22,cls=‘man’, id=33,‘boy’)则是非法的。
*content和**attrs的参数可以为空。如:tag(‘p’, age=22,cls=‘man’, id=33)是合法的,此时content为一个空的元组。###2022年10月3日
7、装饰器和闭包
7.1装饰器的基础知识
装饰器是可调用的对象,其参数是另一个函数(被装饰的函数)。装饰器会处理被装饰的函数然后把它返回,或者将其替换成另一个函数或可调用的对象。
特别注意:装饰器的返回值必须是一个可调用的对象,否则会报错,提示返回值不是一个可调用的对象。可调用的对象,就是类似于函数,可以用()符号的对象。
假设有个名为decorate的装饰器和一个被它装饰的函数func:
def decorate(func):
def real():
print(‘not running func’)
return real@decorate
def func():
print(‘running func’)上面的代码注意以下两点:
1)装饰器的入参不能为空,python会将这个参数视为可调用的对象。
2)装饰器的返回结果real,不能加()符号,只能写其对象名称real,python也会将这个返回结果视为可调用的对象。如果执行func(),因为func被decorate装饰,则python会执行为decorate(func)(),这里我并没有笔误,确实是后面还有一个括号。分成两部分,首先会执行decorate(func),此时返回real对象,然后python会立即调用这个返回的real,执行real()。
因此在decorate装饰的func时,执行func(),相当于以下代码:
def decorate(func):
def real():
print(‘not running func’)
return realdef func():
print(‘running func’)hehe = decorate(func) #decorate(func)返回的是一个可调用的对象
hehe()7.2、Python何时执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义后立即运行,这通常时在导入时(即python加载模块时)。7.3 变量作用域规则
看下面一段代码:

这个代码是不会报错的,执行结果为:

但是,如果在f1函数的最后定义一个b变量,就会报错:
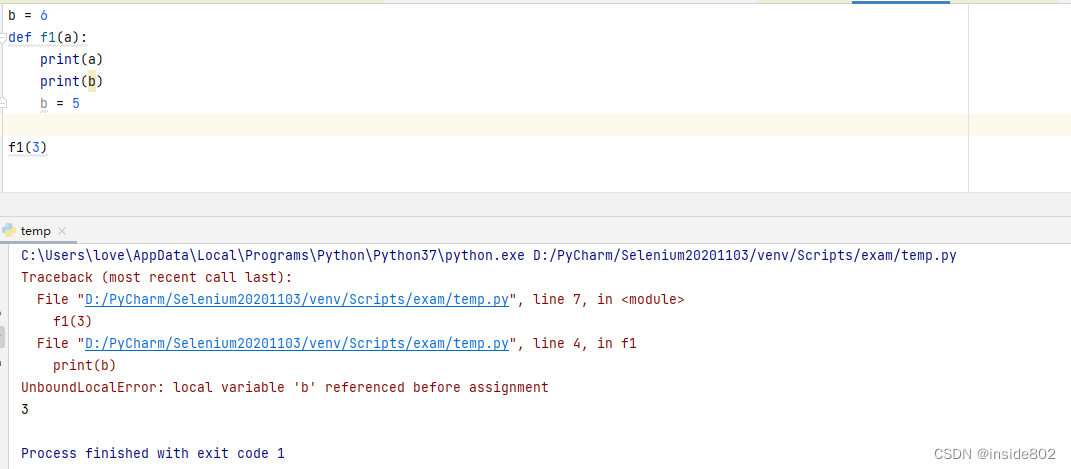 虽然b变量是在print语句之后定义的,但是python在编译函数的定义体时,它判断b是局部变量,因为在函数中给它赋值了。python在尝试获取局部变量b的值时,发现b没有绑定值。
虽然b变量是在print语句之后定义的,但是python在编译函数的定义体时,它判断b是局部变量,因为在函数中给它赋值了。python在尝试获取局部变量b的值时,发现b没有绑定值。
这不是缺陷,而是设计选择:Python不要求声明变量,但是假定在函数定义体中赋值的变量是局部变量。7.4、闭包
理解了上面的变量作用域规则后,我们来学习一下闭包。
7.4.1 什么是闭包
闭包指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。
我们看下面这个函数以及其执行结果:
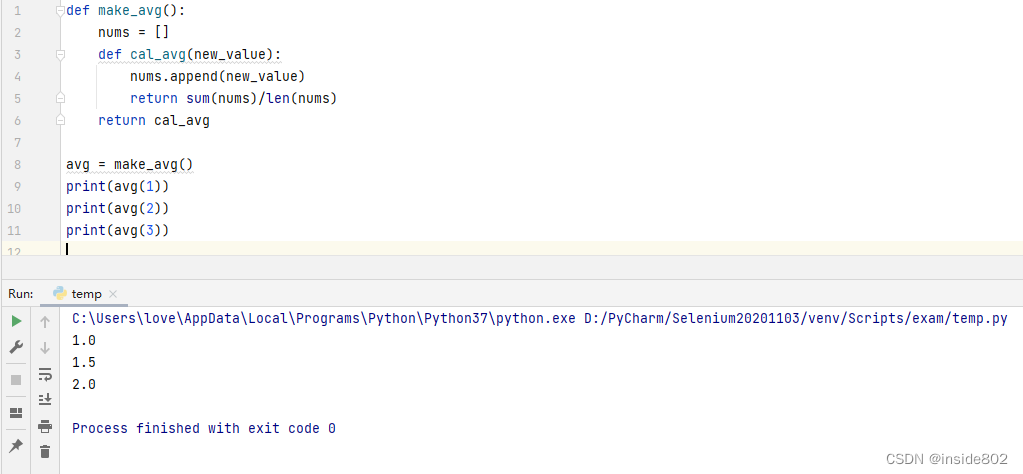
上面的函数是在累计求平均值,特殊的地方在于avg对象可以一直使用同一个nums变量。avg对象是make_avg函数返回的可调用的对象——cal_avg函数。cal_avg函数中的nums变量并不是它内部定义的,而是使用的是它外部的一个变量——make_avg函数的局部变量。在上面第9行代码中,make_avg函数已经执行了return语句了,它的本地作用域也随之生命周期结束,那么第10行、第11行的代码,是如何找到第9行代码中使用的nums变量的呢?在cal_avg函数中,nums变量是自由变量(free variable)。自由变量,指未在本地作用域中绑定的变量。cal_avg函数它在定义时就保留了对自由变量的绑定,自由变量nums和函数cal_avg组合在一起就形成了一个闭包。cal_avg的闭包延伸到自身的作用域之外,包含自由变量nums的绑定。
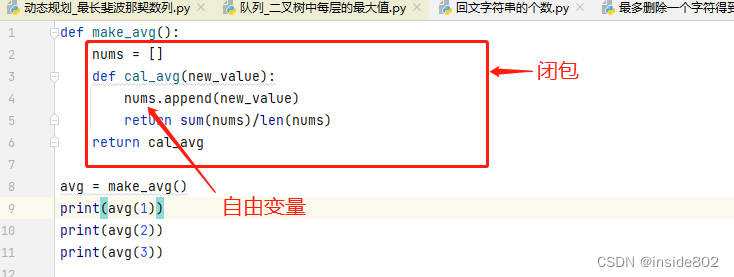
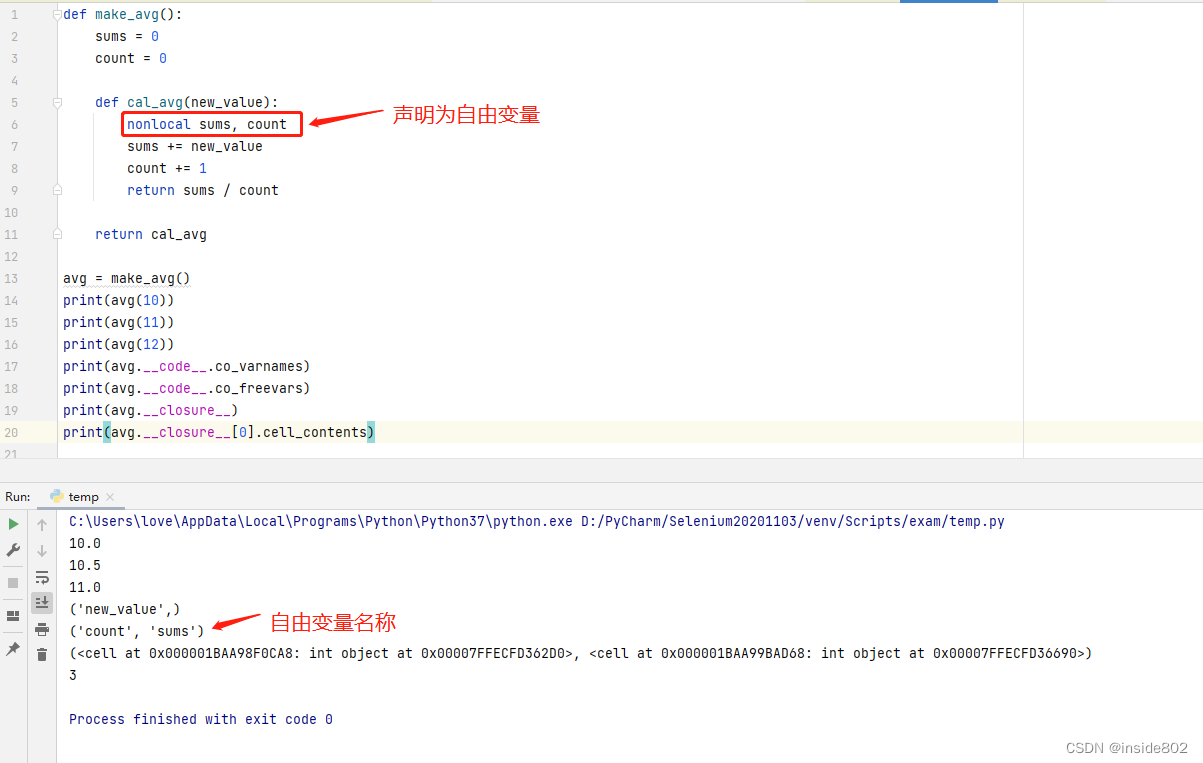
审查返回的avg对象,我们发现python在__code__属性中保存局部变量(co_varnames)和自由变量(co_freevars)的名称。
nums的绑定在返回的avg函数的__closure__属性中(函数的所有属性可复习第6.5节——函数内省)。avg.__closure__是一个元组,它里面的每一个元素对应于avg.code.freevars中的一个名称,这些元素是cell对象,有个cell_contents属性,保存这真正的值。
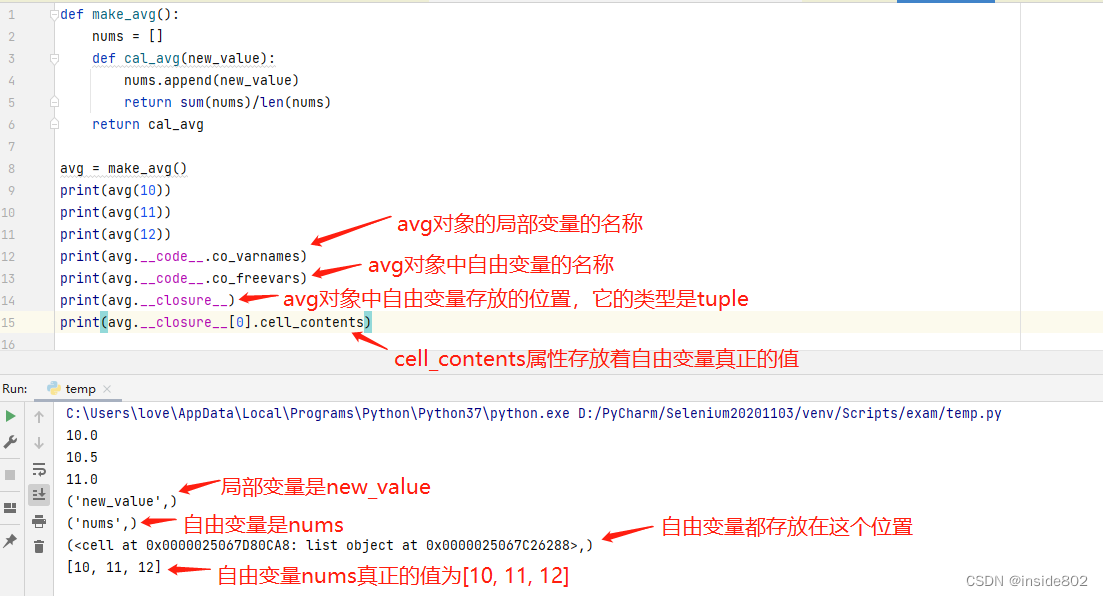
综上,闭包是一种函数,它会保留定义函数时存在的自由变量的绑定,这样调用函数时,虽然定义作用域不可用了,但是仍能使用那些绑定。
注意,只有嵌套在其他函数中的函数才可能需要处理不在全局作用域中的外部变量。7.4.2 nonlocal关键字
7.4.1的例子中,我们使用的自由变量nums是一个列表,它是一个可变对象,因此可以在函数外定义并在函数中引用并修改。但是,如果我们的函数调用的外部变量是一个不可变的对象,比如字符串、数字或者元组呢?如果还像7.4.1中写,就会提示该变量没有被定义。
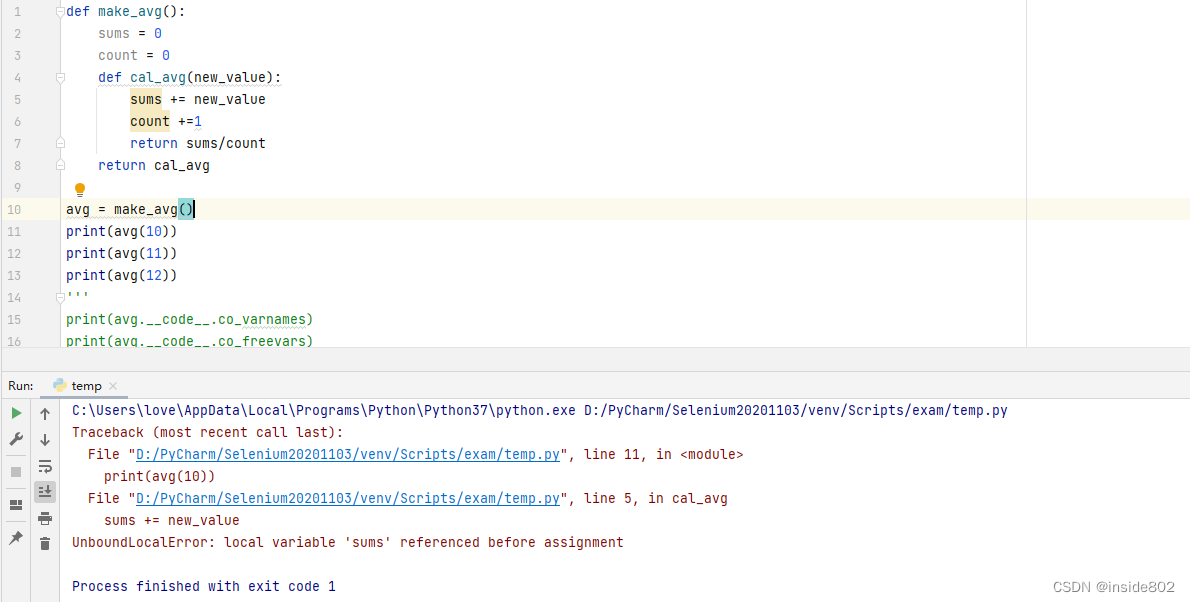
我们再重新读一遍7.4.2中关于闭包的定义,并没有要求自由变量为可变类型的变量,那这为什么会报错呢?
答:
我们再往上看,看7.3节关于变量作用域规则的描述:Python不要求声明变量,但是假定在函数定义体中赋值的变量是局部变量。
在上面的这个例子中,有sums += new_value的代码,这等同于sums = sums+new_value,此时是在对变量sums赋值,如果赋值了,python就会认为sums是一个局部变量,此时就会去这个函数的__code__属性中找局部变量(co_varnames),发现co_varnames中并没有一个元素叫做sums,此时就会认为sums没有被定义,也就会报错。
我们在7.4.1节中没有报错,是因为我们利用了列表是可变对象这个属性,如果我们做一个nums = [XX]的赋值操作,也必然会报错。因此,我们需要告诉python,7.4.2中的sums变量、count变量是自由变量而非局部变量。这就要用到nonlocal关键字。
nonlocal关键字的作用是把变量标记为自由变量,即使在函数中为变量重新赋值了,也会变为自由变量。如果为nonlocal声明的变量赋予新值,闭包中保存的绑定也会更新。因此代码应这样写:
7.4.3 实现一个简单的装饰器
下面我们将实现一个装饰器,被装饰的函数算的是总价,因为要过双十一了,对它们的总价都打5折。
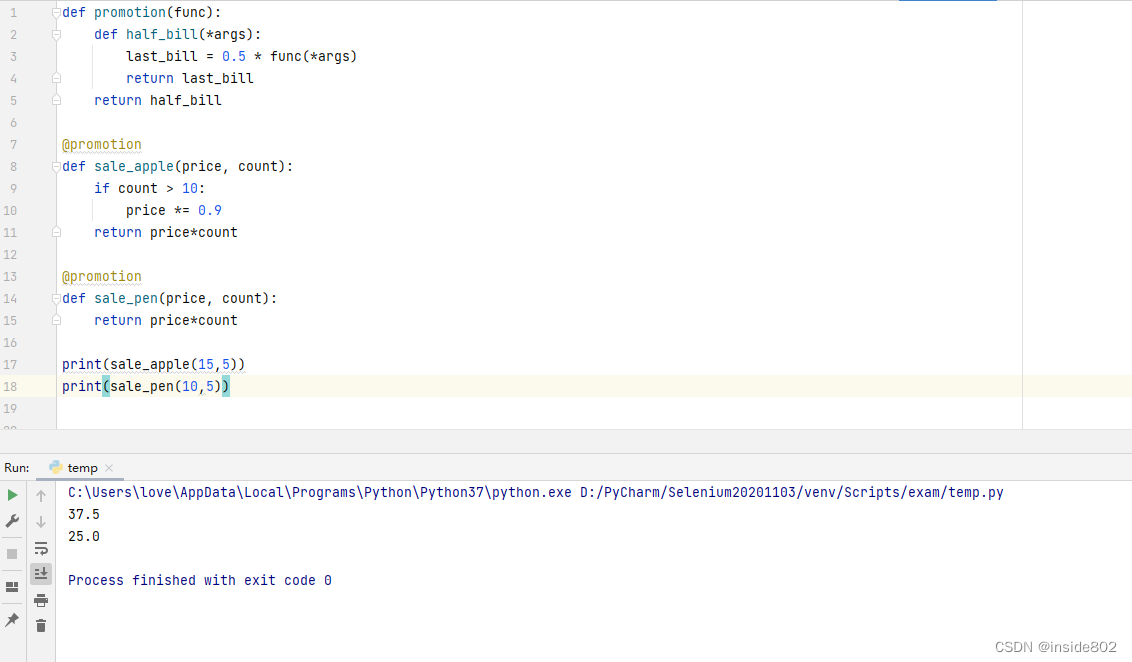
上面
第2行代码中,内部函数half_bill接受任意个参数;
第3行代码中,func是闭包函数half_bill的自由变量(因为我们并没有赋值操作);
第5行代码中,返回内部函数half_bill。
第17行代码中,我们由7.1节关于装饰器的基础知识可知,执行sale_apple(15,5)时,相当于执行promotion(sale_apple)(15,5),对于它的执行过程,我们还是分成两部分,
首先python执行promotion(sale_apple),这个过程中先将func赋值为sale_apple,然后返回值为half_bill,
然后python立即执行half_bill(15,5),在half_bill中,局部变量*args的值为(15,5),自由变量func的值为sale_apple,执行第3行代码,可得到 last_bill的值为0.5 * sale_apple(15,5),即37.5.
同理可知第18行代码执行的过程。7.4.4 标准库中的装饰器
python内置了3个用于装饰方法的函数:property、classmethod和staticmethod。这三个在后面会专门学习。
标准库中最值得关注的两个装饰器是lru_cache和singledispatch,这两个都来自于functools模块
lru_cache是非常实用的装饰器,它实现了备忘功能,在递归时非常好用,它可以避免大量的重复计算。
比如计算菲波那切数列,如果按照常规写法,是这样的:
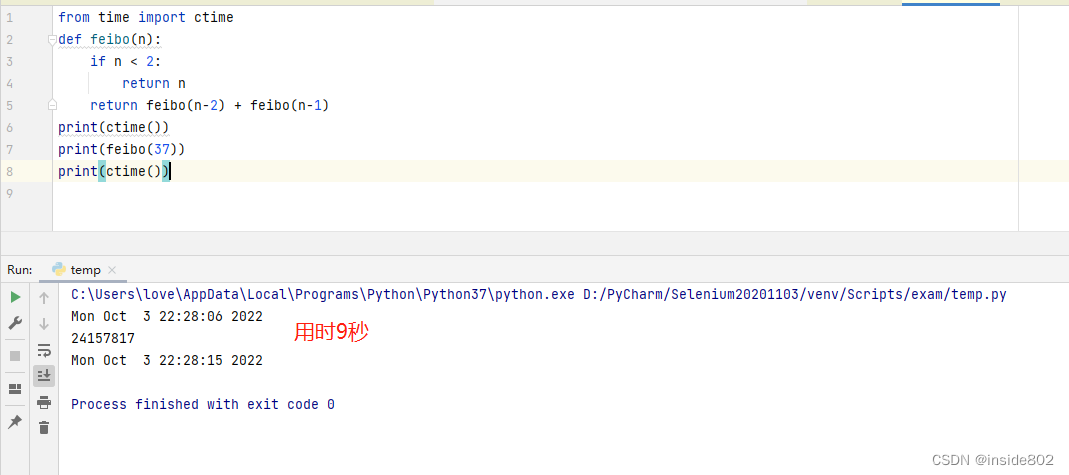
但是如果用lru_cache装饰后:
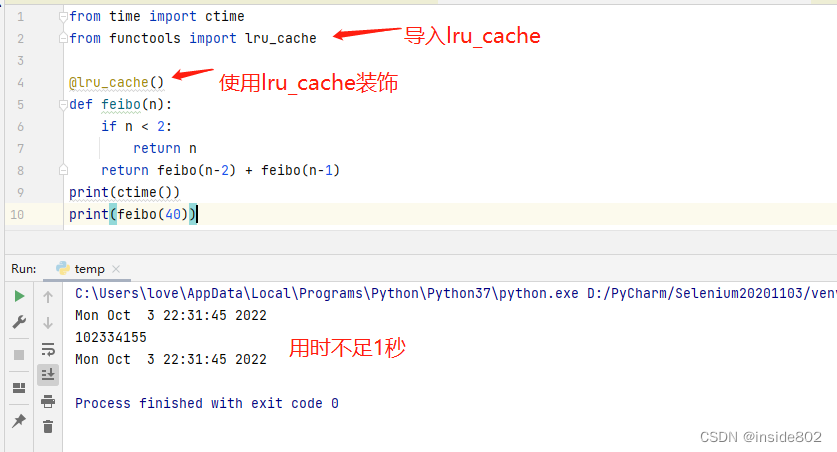
另外,经本人实测,这个装饰器的耗时和自己实现备忘录耗时是接近的,但是不知道内存占用上这个装饰器是否更有优势。
lru_cache有两个可选参数maxsize和typed。maxsize参数指定存储多少个调用的结果。缓存满了之后,旧的结果会被扔掉,腾出空间,为了得到最佳性能,maxsize应该设为2的次幂。typed参数如果设置为True,把不同参数类型得到的结果分开保存。
另外,因为lru_cache使用字典存储结果,而且键根据调用时传入的定位参数和关键字参数创建,所以被lru_cache装饰的函数,它的所有参数必须是可散列的。singledispatch装饰器我看不懂,以后用到重载时再说。
7.4.4 叠放装饰器
如何理解叠放装饰呢?
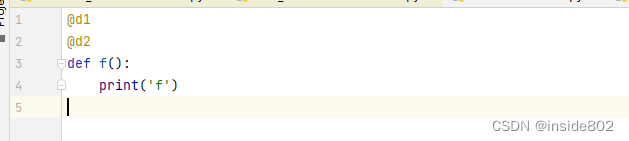
它相当于d1(d2(f)) -
相关阅读:
比较常见的在线项目管理系统有哪些?
简单漂亮的登录页面
计算机毕业设计hadoop+spark知识图谱课程推荐系统 课程预测系统 课程大数据 课程数据分析 课程大屏 mooc慕课推荐系统 大数据毕业设计
【OpenCV 例程200篇】219. 添加数字水印(盲水印)
Frp(内网穿透)服务部署
7-13 TreeSet自定义排序
【Pytorch】网络中间特征图可视化—详细记录-函数可直接调用
利用条形码生成器在Word 2013中轻松制作条形码的方法
【学习笔记】(数学)线性代数-矩阵的概念和特殊矩阵
讨论stl链表
- 原文地址:https://blog.csdn.net/inside802/article/details/126770136