-
【迁移学习】Transfer Learning
kaggle上可以下载各种预期训练好的模型参数:
https://www.kaggle.com/datasets/igorkrashenyi/pytorch-model-zooalexnet-owt-4df8aa71.pth
bn_inception-52deb4733.pth
cafferesnet101-9d633cc0.pth
densenet121-fbdb23505.pth
densenet161-347e6b360.pth
densenet169-f470b90a4.pth
densenet201-5750cbb1e.pth
dpn107_extra-b7f9f4cc9.pth
dpn131-7af84be88.pth
dpn68-4af7d88d2.pth
dpn68b_extra-363ab9c19.pth
dpn92_extra-fda993c95.pth
dpn98-722954780.pth
fbresnet152-2e20f6b4.pth
inceptionresnetv2-520b38e4.pth
inceptionv4-8e4777a0.pth
nasnetalarge-a1897284.pth
nasnetamobile-7e03cead.pth
pnasnet5large-bf079911.pth
polynet-f71d82a5.pth
resnext101_32x4d-29e315fa.pth
resnext101_64x4d-e77a0586.pth
se_resnet101-7e38fcc6.pth
se_resnet152-d17c99b7.pth
se_resnet50-ce0d4300.pth
se_resnext101_32x4d-3b2fe3d8.pth
senet154-c7b49a05.pth
vgg11-bbd30ac9.pth
vgg11_bn-6002323d.pth
vgg13-c768596a.pth
vgg13_bn-abd245e5.pth
vgg16-397923af.pth
vgg19_bn-c79401a0.pthimport numpy as np import torch import torch.nn as nn from torch.utils import data import torchvision import torchvision.models as models import torchvision.transforms as transforms import matplotlib.pyplot as plt from tensorboardX import SummaryWriter device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') writer = SummaryWriter('runs/CIFAR10_resnet18') trans_train = transforms.Compose([transforms.RandomResizedCrop((224, 224)), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) trans_test = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) data_path = './data' trainset = torchvision.datasets.CIFAR10(data_path, train=True, transform=trans_train, download=True) testset = torchvision.datasets.CIFAR10(data_path, train=False, transform=trans_test, download=False) train_batch_size = 256 test_batch_size = 512 trainloader = torch.utils.data.DataLoader(trainset, batch_size=train_batch_size, shuffle=True, num_workers=2) testloader = torch.utils.data.DataLoader(testset, batch_size=test_batch_size, shuffle=True, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') model = models.resnet18(pretrained=True) # model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT) # print(model) for param in model.parameters(): param.requires_grad = False model.fc = nn.Linear(512, 10) model.to(device) # # ---------------------- show the number of weight ---------------------- # total_params = sum(p.numel() for p in model.parameters()) # total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad) # print('total number of parameters:{}'.format(total_params)) # print('total number of trainable parameters:{}'.format(total_trainable_params)) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.fc.parameters(), lr=0.001, weight_decay=0.001, momentum=0.9) # ---------------------- model training ---------------------- epochs = 20 train_epoch_loss, test_epoch_loss, train_epoch_acc, test_epoch_acc = [], [], [], [] # 用来记录每个epoch的训练、测试误差以及准确率 for epoch in range(epochs): # -------------- train -------------- model.train() train_loss, train_correct = 0, 0 for step, (train_img, train_label) in enumerate(trainloader): train_img, train_label = train_img.to(device), train_label.to(device) output = model(train_img) loss = criterion(output, train_label) optimizer.zero_grad() loss.backward() optimizer.step() correct_num = torch.sum(torch.argmax(output, dim=1) == train_label) train_correct += correct_num train_loss += loss writer.add_scalar('train_loss_batch', loss.item(), step) accurat_rate = correct_num / train_batch_size writer.add_scalar('train_accurate_batch', accurat_rate.item(), step) train_epoch_loss.append(train_loss / len(trainloader)) train_epoch_acc.append(train_correct / len(trainset)) writer.add_scalar('train_loss_epoch', train_loss / len(trainloader), epoch) writer.add_scalar('train_accurate_epoch', train_correct / len(trainset), epoch) # -------------- valid -------------- model.eval() test_loss, test_correct = 0, 0 for test_img, test_label in testloader: test_img, test_label = test_img.to(device), test_label.to(device) output = model(test_img) loss = criterion(output, test_label) correct_num = torch.sum(torch.argmax(output, dim=1) == test_label) test_correct += correct_num test_loss += loss test_epoch_loss.append(test_loss / len(testloader)) test_epoch_acc.append(test_correct / len(testset)) writer.add_scalar('test_loss_epoch', train_loss / len(trainloader), epoch) writer.add_scalar('test_accurate_epoch', train_correct / len(trainset), epoch) print('epoch{}, train_loss={}, train_acc={}'.format(epoch, train_loss/len(trainloader), train_correct/len(trainset))) print('epoch{}, valid_loss={}, valid_acc={}'.format(epoch, test_loss/len(testloader),test_correct/len(testset))) print('\n') # ------------- plot the result ------------- train_loss_array = [loss.item() for loss in train_epoch_loss] train_acc_array = [acc.item() for acc in train_epoch_acc] test_loss_array = [loss.item() for loss in test_epoch_loss] test_acc_array = [acc.item() for acc in test_epoch_acc] plt.figure(figsize=(20, 10)) plt.subplot(221) plt.title('loss') plt.plot(np.arange(epochs), train_loss_array) plt.plot(np.arange(epochs), test_loss_array) plt.grid(True, which='both', axis='both', color='y', linestyle='--', linewidth=1) plt.show() plt.figure(figsize=(20, 10)) plt.subplot(222) plt.title('accurate') plt.plot(np.arange(epochs), train_acc_array) plt.plot(np.arange(epochs), test_acc_array) plt.grid(True, which='both', axis='both', color='y', linestyle='--', linewidth=1) plt.legend(["train","validation"],loc='lower right') plt.show() # -------------- save the result ------------- result_dict = {'train_loss_array': train_loss_array, 'train_acc_array': train_acc_array, 'test_loss_array': test_loss_array, 'test_acc_array': test_acc_array} np.save('./result_dict.npy', result_dict)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
输出:
epoch0, train_loss=1.8071383237838745, train_acc=0.3887999951839447
epoch0, valid_loss=1.2278122901916504, valid_acc=0.6430000066757202epoch1, train_loss=1.4005506038665771, train_acc=0.5360999703407288
epoch1, valid_loss=1.030735969543457, valid_acc=0.6850999593734741epoch2, train_loss=1.2940409183502197, train_acc=0.5644800066947937
epoch2, valid_loss=0.9407730102539062, valid_acc=0.7059999704360962epoch3, train_loss=1.2393066883087158, train_acc=0.578819990158081
epoch3, valid_loss=0.8911893963813782, valid_acc=0.715499997138977epoch4, train_loss=1.2145596742630005, train_acc=0.5823799967765808
epoch4, valid_loss=0.8617193102836609, valid_acc=0.7218999862670898epoch5, train_loss=1.1909451484680176, train_acc=0.5880199670791626
epoch5, valid_loss=0.8370893597602844, valid_acc=0.7269999980926514epoch6, train_loss=1.182749629020691, train_acc=0.5904200077056885
epoch6, valid_loss=0.8229374289512634, valid_acc=0.7293999791145325epoch7, train_loss=1.1616133451461792, train_acc=0.5995399951934814
epoch7, valid_loss=0.8094478845596313, valid_acc=0.7342000007629395epoch8, train_loss=1.1525970697402954, train_acc=0.6015200018882751
epoch8, valid_loss=0.8026527762413025, valid_acc=0.7366999983787537epoch9, train_loss=1.144952416419983, train_acc=0.6024999618530273
epoch9, valid_loss=0.7950977683067322, valid_acc=0.7354999780654907epoch10, train_loss=1.140042781829834, train_acc=0.6040599942207336
epoch10, valid_loss=0.7850207686424255, valid_acc=0.7365999817848206epoch11, train_loss=1.1367998123168945, train_acc=0.6043599843978882
epoch11, valid_loss=0.7832964658737183, valid_acc=0.7390999794006348epoch12, train_loss=1.1333338022232056, train_acc=0.6078799962997437
epoch12, valid_loss=0.7704198956489563, valid_acc=0.7419999837875366epoch13, train_loss=1.1298826932907104, train_acc=0.6068999767303467
epoch13, valid_loss=0.767668604850769, valid_acc=0.7426999807357788epoch14, train_loss=1.1242992877960205, train_acc=0.6079999804496765
epoch14, valid_loss=0.773628830909729, valid_acc=0.7387999892234802epoch15, train_loss=1.118688941001892, train_acc=0.6112200021743774
epoch15, valid_loss=0.757527232170105, valid_acc=0.7443000078201294epoch16, train_loss=1.1208925247192383, train_acc=0.6098399758338928
epoch16, valid_loss=0.7577210068702698, valid_acc=0.7436999678611755epoch17, train_loss=1.1159234046936035, train_acc=0.6102199554443359
epoch17, valid_loss=0.7527276873588562, valid_acc=0.746399998664856epoch18, train_loss=1.1142677068710327, train_acc=0.6092199683189392
epoch18, valid_loss=0.7553915977478027, valid_acc=0.7448999881744385epoch19, train_loss=1.1068326234817505, train_acc=0.6119199991226196
epoch19, valid_loss=0.7486104369163513, valid_acc=0.7450000047683716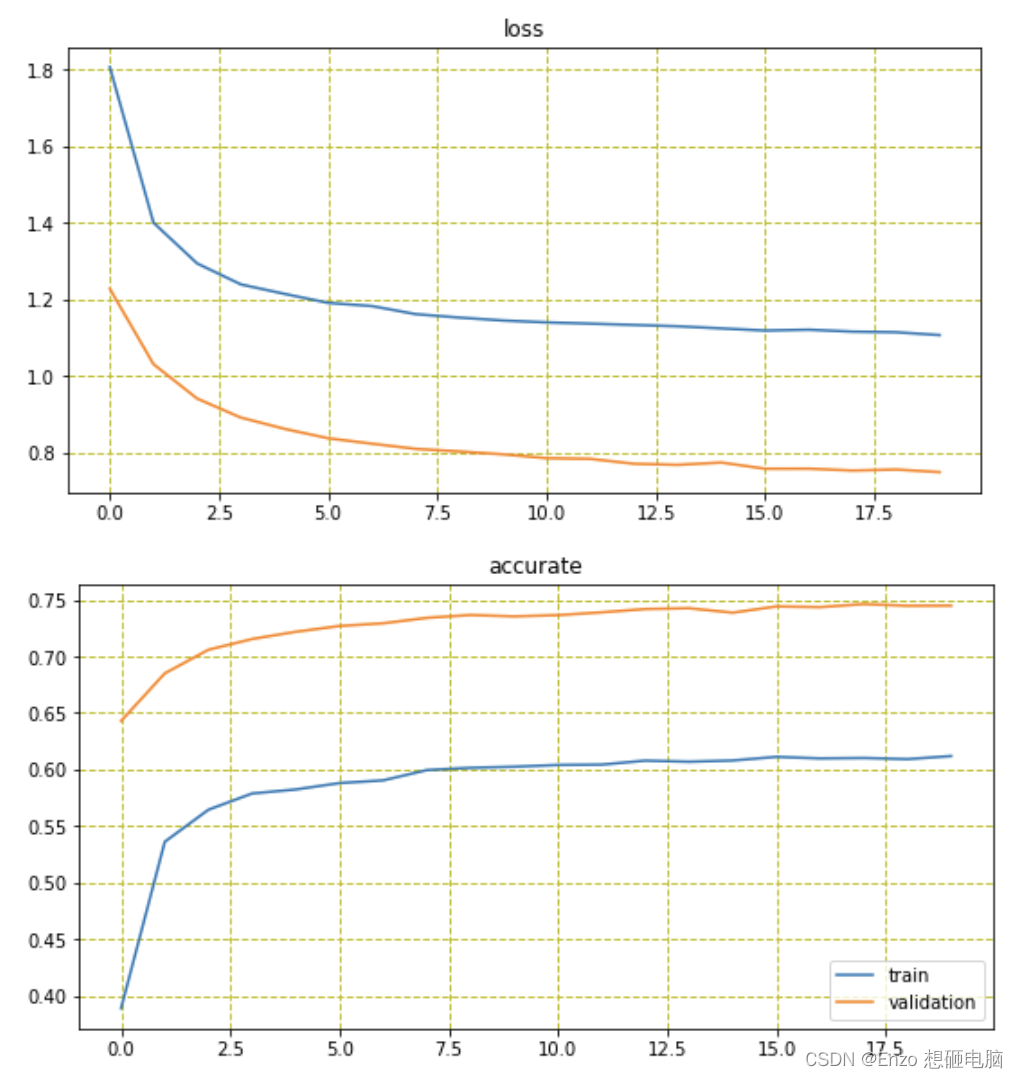
-
相关阅读:
图解LeetCode——7. 整数反转(难度:中等)
【C语言】经典编程题
SpringBoot学习笔记(3)——B站动力节点
sql注入--通过修改数据完成注入--一文详细讲解
基于java+ssm+easyui灵悟酒店系统
技术分歧,如何决策?
阿里云存储解决方案,助力轻舟智航“将无人驾驶带进现实”
MySql 数据库【事务】
跨境电商系统源码分享,助力企业快速搭建电商平台
await在python协程函数的使用
- 原文地址:https://blog.csdn.net/weixin_37804469/article/details/126750957
