-
笔试强训(二)
一、选择题
(1)
【代码1】public static void main(String[] args) { String str="Admin"; System.out.println(str.toLowerCase()=="admin"); } //执行结果:false- 1
- 2
- 3
- 4
- 5
【代码2】
public static void main(String[] args) { String str="admin"; System.out.println(str.toLowerCase()=="admin"); } //执行结果 true- 1
- 2
- 3
- 4
- 5
如果我们想要弄个清楚为什么上面两个代码的输出结果不同,就需要对toLowerCase()方法的源码有一定的了解
【toLowerCase()源码分析】public String toLowerCase(Locale locale) { if (locale == null) { throw new NullPointerException(); } int firstUpper; final int len = value.length; //先检查传入的字符串本身是否就全都是小写,如果源字符串本身就全是小写,就返回该字符串的引用 /* Now check if there are any characters that need to be changed. */ scan: { for (firstUpper = 0 ; firstUpper < len; ) { char c = value[firstUpper]; if ((c >= Character.MIN_HIGH_SURROGATE) && (c <= Character.MAX_HIGH_SURROGATE)) { int supplChar = codePointAt(firstUpper); if (supplChar != Character.toLowerCase(supplChar)) { break scan; } firstUpper += Character.charCount(supplChar); } else { if (c != Character.toLowerCase(c)) { break scan; } firstUpper++; } } //返回源字符串的引用 return this; } //如果源字符串中有大写字母,此时不会在源字符串上进行修改,而是创建一个新的字符串,返回这个新的字符串的引用 char[] result = new char[len]; int resultOffset = 0; /* result may grow, so i+resultOffset * is the write location in result */ /* Just copy the first few lowerCase characters. */ System.arraycopy(value, 0, result, 0, firstUpper); String lang = locale.getLanguage(); boolean localeDependent = (lang == "tr" || lang == "az" || lang == "lt"); char[] lowerCharArray; int lowerChar; int srcChar; int srcCount; for (int i = firstUpper; i < len; i += srcCount) { srcChar = (int)value[i]; if ((char)srcChar >= Character.MIN_HIGH_SURROGATE && (char)srcChar <= Character.MAX_HIGH_SURROGATE) { srcChar = codePointAt(i); srcCount = Character.charCount(srcChar); } else { srcCount = 1; } if (localeDependent || srcChar == '\u03A3' || // GREEK CAPITAL LETTER SIGMA srcChar == '\u0130') { // LATIN CAPITAL LETTER I WITH DOT ABOVE lowerChar = ConditionalSpecialCasing.toLowerCaseEx(this, i, locale); } else { lowerChar = Character.toLowerCase(srcChar); } if ((lowerChar == Character.ERROR) || (lowerChar >= Character.MIN_SUPPLEMENTARY_CODE_POINT)) { if (lowerChar == Character.ERROR) { lowerCharArray = ConditionalSpecialCasing.toLowerCaseCharArray(this, i, locale); } else if (srcCount == 2) { resultOffset += Character.toChars(lowerChar, result, i + resultOffset) - srcCount; continue; } else { lowerCharArray = Character.toChars(lowerChar); } /* Grow result if needed */ int mapLen = lowerCharArray.length; if (mapLen > srcCount) { char[] result2 = new char[result.length + mapLen - srcCount]; System.arraycopy(result, 0, result2, 0, i + resultOffset); result = result2; } for (int x = 0; x < mapLen; ++x) { result[i + resultOffset + x] = lowerCharArray[x]; } resultOffset += (mapLen - srcCount); } else { result[i + resultOffset] = (char)lowerChar; } } //返回修改后的新字符串的引用 return new String(result, 0, len + resultOffset); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
(2)下面哪一种叙述是正确的(D)
A.abstract可以修饰字段、方法和类
B. 抽象方法的body部分一定要用{}包住
C. 声明抽象方法,{}可有可无
D. 声明抽象方法,不可以写出大括号abstract不能用来修饰字段
声明抽象方法是不可以写出大括号的,写出大括号代表着要实现这个方法(3)下面哪一行代码可以替换//add code here 而不产生编译错误(A)
public abstract class Test2 { public int n=5; //add code here public void method(){ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
A. pubic abstract void method(int a);
B. n+=5;
C. public int method();
D. public abstract void anotherMethod(){}B:成员变量的运算必须在方法里面
C:普通方法需要实现,不能没有{}
D:{}是多余的二、编程题
2.1 倒置字符串
2.1.1 题目
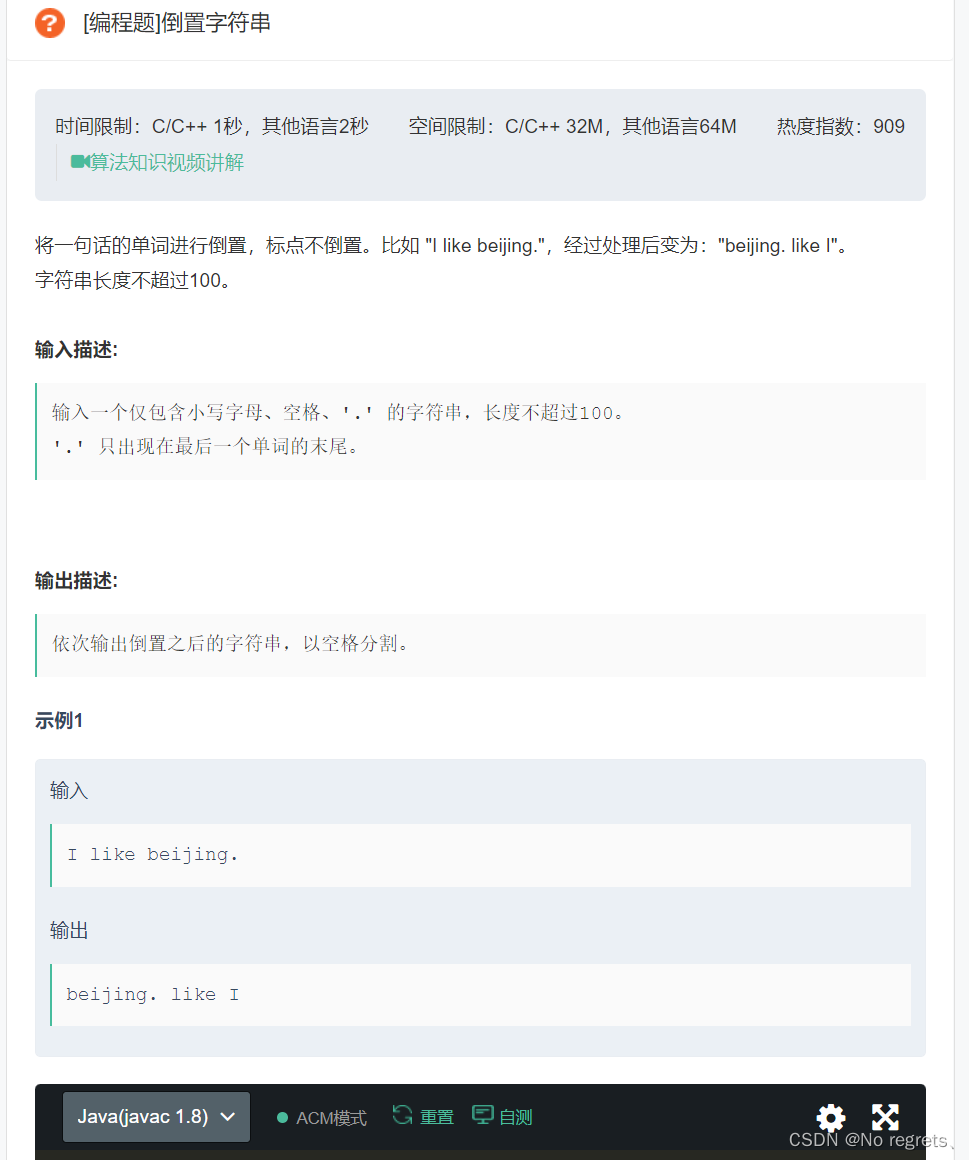
2.1.2 题解
思路:
- 先将整个字符串逆置
- 再将每个单词分别逆置
【代码】
import java.util.*; public class Main{ public static void reverse(char[] str,int l,int r){ while(l<r){ char tmp=str[r]; str[r]=str[l]; str[l]=tmp; l++; r--; } } public static void main(String[] args){ Scanner scanner=new Scanner(System.in); String s=scanner.nextLine(); char[] str=s.toCharArray(); reverse(str,0,str.length-1); int begin=0; for(int i=0;i<str.length;i++){ if(str[i]==' '){ reverse(str,begin,i-1); begin=i+1; } } //此处是将最后一个单词进行逆置,因为当i遍历当字符串末尾时,会跳出循环 //这就倒置最后一个字符串没能在for循环中进行逆置 reverse(str,begin,str.length-1); StringBuilder sb=new StringBuilder(); for(int i=0;i< str.length;i++){ sb.append(str[i]); } System.out.println(sb.toString()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
2.2 排序子序列
2.2.1 题目
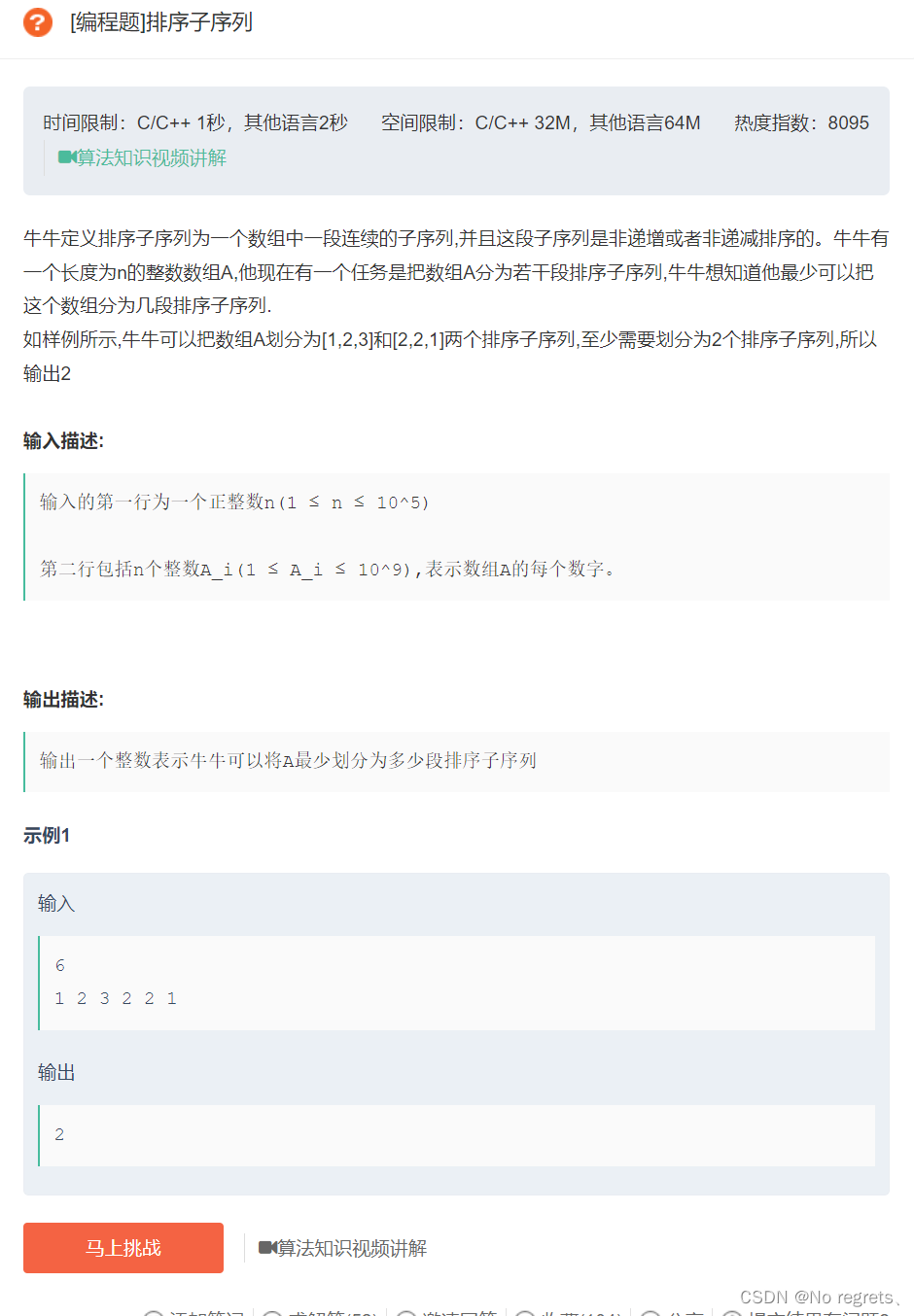
2.2.2 题解
【代码】:
import java.util.*; public class Main{ public static void main(String[] args){ Scanner scanner=new Scanner(System.in); int n=scanner.nextInt(); int[] arr=new int[n+1]; for(int i=0;i<n;i++){ arr[i]=scanner.nextInt(); } int i=0; int count=0; while(i<n){ //当前遍历到的数比下一个数小,则进入非递减序列 if(arr[i]<arr[i+1]){ while(i<n && arr[i]<arr[i+1]){ i++; } //当前的非递减序列遍历完了,需要划分的数+1 count++; //进入下一个序列 i++; }else if(arr[i]>arr[i+1]){ //当前遍历到的数比下一个大,进入非递增序列 while(i<n && arr[i]>arr[i+1]){ i++; } //当前的非递增序列结束,count++; count++; //进入下一个序列 i++; }else { //如果当前数和下一个数相等,i就继续向后遍历 i++; } } System.out.println(count); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
【注意】:
为了防止在arr[i]>arr[i+1]时数组下标越界,数组大小申请为n+1,由于题目中说给定的都是正数,arr[n]为0,不会影响最终结果
-
相关阅读:
Java数组
sshd 解决问题 Deprecated SSH Cryptographic Settings 通过修改配置 去掉废弃的加密算法
Web前端:与Angular和React相比,为什么要选择Vue JS
这些视频转音频软件你知道吗?
VS Code中PlatformIO IDE的安装并开发Arduino
vue 表单重置功能
1552. 两球之间的磁力-快速排序+二分查找
最新国内AI工具(ChatGPT4.0、GPTs、AI绘画、文档分析使用教程)
四十二、路由层
低代码引擎半岁啦,来跟大家唠唠嗑...
- 原文地址:https://blog.csdn.net/m0_60631323/article/details/126760238
