-
hadoop04--Kafka集群环境搭建
【Kafka文件为:kafka_2.11-2.0.0 ---链接: https://pan.baidu.com/s/1n3ozfofnIKJhkOnSLZ1EYA?pwd=ngvu】
也可以到官网进行下载:https://kafka.apache.org/
目录
1,修改config/server.properties文件
一,下载安装Kafka
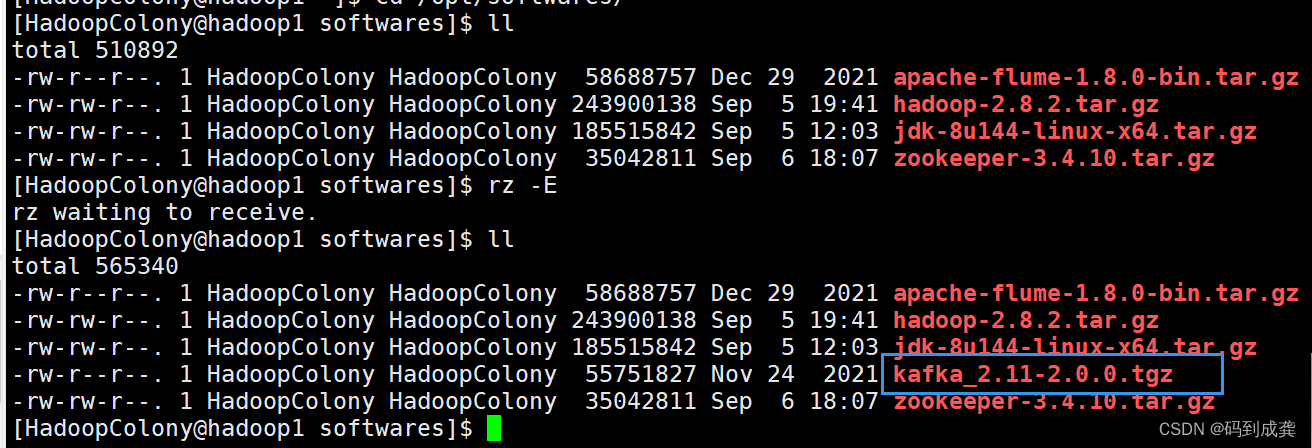
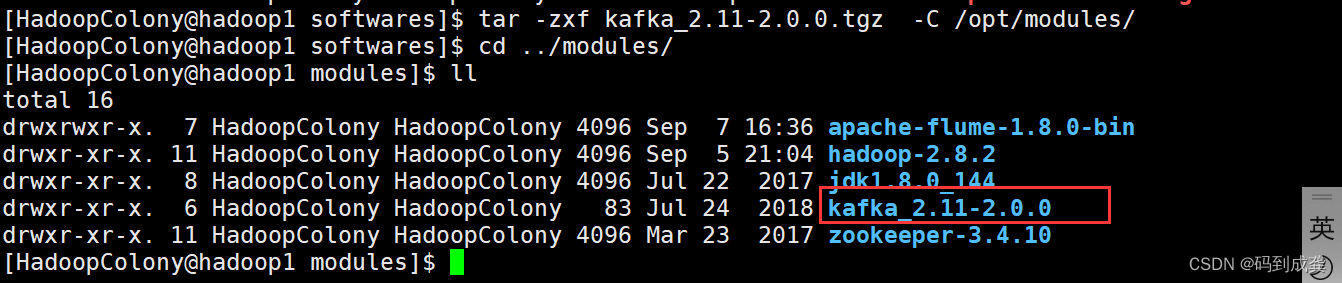
接下来我们去解压该压缩包到我们的/opt/modules目录下
- [HadoopColony@hadoop1 softwares]$ tar -zxf kafka_2.11-2.0.0.tgz -C /opt/modules/
- [HadoopColony@hadoop1 softwares]$ cd ../modules/
- [HadoopColony@hadoop1 modules]$ ll
- total 16
- drwxrwxr-x. 7 HadoopColony HadoopColony 4096 Sep 7 16:36 apache-flume-1.8.0-bin
- drwxr-xr-x. 11 HadoopColony HadoopColony 4096 Sep 5 21:04 hadoop-2.8.2
- drwxr-xr-x. 8 HadoopColony HadoopColony 4096 Jul 22 2017 jdk1.8.0_144
- drwxr-xr-x. 6 HadoopColony HadoopColony 83 Jul 24 2018 kafka_2.11-2.0.0
- drwxr-xr-x. 11 HadoopColony HadoopColony 4096 Mar 23 2017 zookeeper-3.4.10
- [HadoopColony@hadoop1 modules]$
因为Kafka集群的各个节点(blocker)都是对等的,配置基本相同,因此只需要配置一个broker,然后将这个broker上的配置复制到其他broker并进行微调即可。
二,修改配置文件
1,修改config/server.properties文件
- broker.id=1
- log.dirs=/opt/modules/kafka_2.11-2.0.0/kafka-logs
- num.partitions=2
- zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181
- #socket监听的地址,用于broker监听生产者和消费者请求
- listeners=PLAINTEXT://hadoop1:9092
- #消息备份副本数,默认为1,即不进行备份。
- default.replication.factor=2





三,发送安装文件到其他节点
- [HadoopColony@hadoop1 modules]$ scp -r kafka_2.11-2.0.0/ HadoopColony@hadoop2:/opt/modules/
- [HadoopColony@hadoop1 modules]$ scp -r kafka_2.11-2.0.0/ HadoopColony@hadoop3:/opt/modules/


1,修改broker标识及socket监听地址
hadoop2:
- cd /opt/modules/zookeeper-3.4.10/conf
- broker.id=2
- listeners=PLAINTEXT://hadoop2:9092
hadoop3:
- cd /opt/modules/zookeeper-3.4.10/conf
- broker.id=3
- listeners=PLAINTEXT://hadoop3:9092
四,启动Kafka集群
因为Kafka是依赖zookeeper集群的,所以在开启Kafka集群之前要先开启zookeeper集群
【需要注意的是:Kafka集群的开启和zookeeper一样,都是要分别在三个节点上执行开启命令】
如下:
- [HadoopColony@hadoop1 bin]$ ./zkServer.sh start #到zookeeper的bin目录下开启zookeeper
- ZooKeeper JMX enabled by default
- Using config: /opt/modules/zookeeper-3.4.10/bin/../conf/zoo.cfg
- Starting zookeeper ... already running as process 4822. #已经开启成功
- [HadoopColony@hadoop1 bin]$ cd ../../kafka_2.11-2.0.0/ #到Kafka的安装目录
- [HadoopColony@hadoop1 kafka_2.11-2.0.0]$ cd bin #到bin目录下执行开启命令
- [HadoopColony@hadoop1 bin]$ ./zkServer.sh start
- -bash: ./zkServer.sh: No such file or directory
- [HadoopColony@hadoop1 bin]$ ./kafka-server-start.sh -daemon ../config/server.properties
- [HadoopColony@hadoop1 bin]$ jps #查看进程
- 5218 Kafka
- 5299 Jps
- 4822 QuorumPeerMain


最后, 查看日志文件kafka_2.11-2.0.0/logs/server.log,运行稳定无异常,则说明
Kafka集群搭建成功。如上就是Kafka集群的搭建,有问题的请在评论区留言。
-
相关阅读:
ModbusTCP、TCP/IP都走网线,一样吗?
Router-view
过滤器Filter
Containerd 如何配置 Proxy?
Atlassian Confluence 远程代码执行漏洞(CVE-2022-26134漏洞分析与防护
图解MySQL逻辑备份的实现流程
从零开始的图像语义分割:FCN快速复现教程(Pytorch+CityScapes数据集)
C++11:新特性(11-20)
arcgis js 4.x实现类似openalayers加载tilewms图层效果
线性规划在多种问题形式下的应用
- 原文地址:https://blog.csdn.net/weixin_53046747/article/details/126757677