-
Doris1.1.1多种异构数据源数据导入方案
Doris分析型数据库
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即时查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
Doris的几种数据源导入方案

1、Doris数据仓库的第一种导入方案(Stream Load):
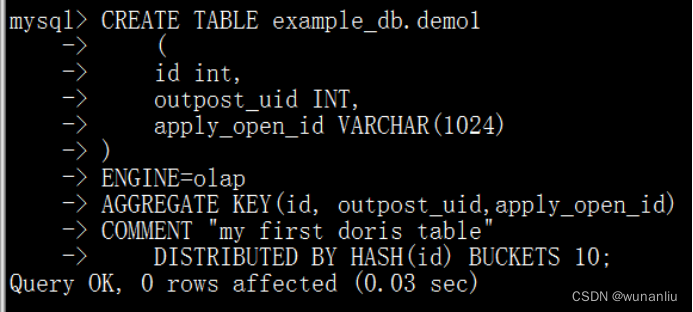
- 创建Doris 基础的分桶表,OLAP类型
- CREATE TABLE example_db.test
- (
- id int,
- outpost_uid INT,
- create_time DATETIME,
- apply_open_id VARCHAR(1024),
- scan_result INT,
- reason VARCHAR(1024),
- phone VARCHAR(100),
- tz_place_id VARCHAR(100),
- address_id INT,
- u_id INT,
- case_type INT
- )
- ENGINE=olap
- AGGREGATE KEY(id, outpost_uid,create_time,apply_open_id,scan_result,reason,phone,tz_place_id,address_id,u_id,case_type)
- COMMENT "my first doris table"
- DISTRIBUTED BY HASH(id) BUCKETS 10;
- 将需要的TXT的文件,上传到服务器某一个文件夹下面。
- /home/wx_outpost_scan.txt
书写Doris 数据倒入脚本命令
curl -u root:doris密码 -H "label:liuwunan2" -H "column_separator:," -T /home/wx_outpost_scan.txt http://BE_IP:8040/api/example_db/aaaaa/_stream_load
Demo操作:

数据样例对比

- 查看日志:
- show load order by createtime desc limit 1\G
备注说明:
数据倒入,此处需要注意一个问题:
column_separator 用于指定倒入文件中的列的分隔符,默认为\t,如果是不可见字符,则需要加\x作为前缀,使用十六进制来表示分隔符。
如Hive文件分隔符\x01,则需要指定为-H “column_separator:\x01”。2、HDFS文本文件导入Doris中(Broker Load):
HDFS文件倒入Doris
需要启动apache_hdfs_broker组件:
直接启动,不需要修改配置文件 组件服务:BrokerBootstrap,【切记后台守护进程运行】第1步:创建Doris表(指定对应字段)
- create table student1
- (
- phone varchar(50) ,
- user_name String ,
- id_card varchar(50),
- times date
- )
- DUPLICATE KEY(phone)
- DISTRIBUTED BY HASH(id_card) BUCKETS 10;
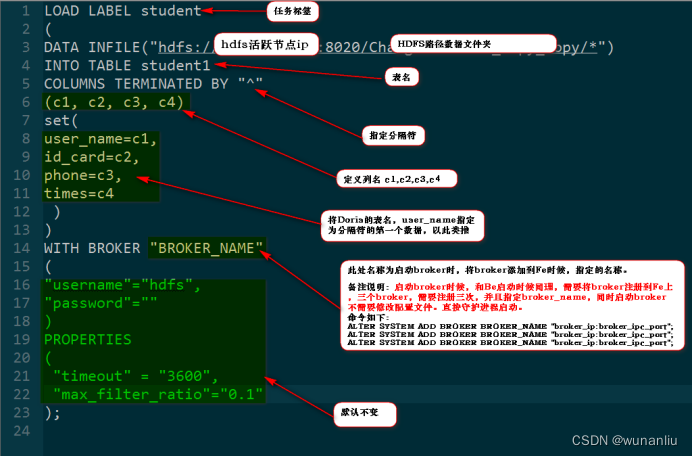
第2步:创建HDFS数据导入的流
- LOAD LABEL student
- (
- DATA INFILE("hdfs://HDFS_IP(活跃节点):8020/test_copy_copy/*")
- INTO TABLE student1
- COLUMNS TERMINATED BY "^"
- (c1, c2, c3, c4)
- set(
- user_name=c1,
- id_card=c2,
- phone=c3,
- times=c4)
- )
- WITH BROKER "BROKER_NAME"
- (
- "username"="hdfs",
- "password"=""
- )
- PROPERTIES
- (
- "timeout" = "3600",
- "max_filter_ratio"="0.1"
- );
解释说明:
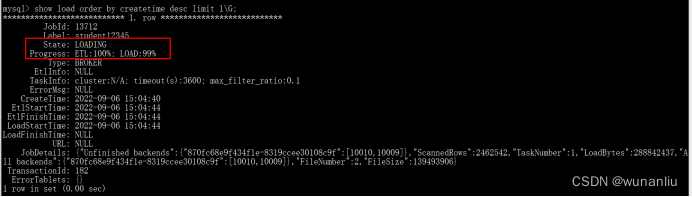
第3步:查看过程和结果
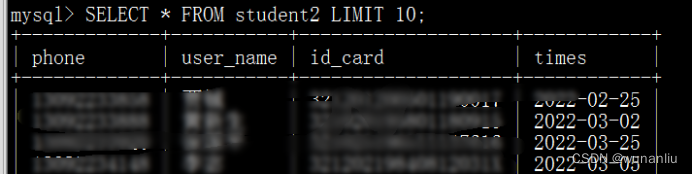
第4步:查看结果
3、Kafka实时接入数据进入Doris(Routine Load)
第1步:创建Doris 导入表
- create table student222
- (
- id varchar(50),
- user_name varchar(50) ,
- times varchar(50)
- )
- DUPLICATE KEY(id)
- DISTRIBUTED BY HASH(id) BUCKETS 10;
第2步:创建Doris 接入Kafka 数据持续任务
- CREATE ROUTINE LOAD student001 ON student222
- COLUMNS TERMINATED BY ",",
- COLUMNS(id, user_name, times )
- PROPERTIES
- (
- "desired_concurrent_number"="3",
- "max_batch_interval" = "10",
- "max_batch_rows" = "300000",
- "max_batch_size" = "209715200",
- "strict_mode" = "false"
- )
- FROM KAFKA
- (
- "kafka_broker_list" = "zk_IP:9092,zk_IP:9092,zk_IP:9092",
- "kafka_topic" = "test_1",
- "property.group.id" = "test_1_001",
- "property.client.id" = "test_1_001",
- "property.kafka_default_offsets" = "OFFSET_END"
- );
截图指示说明:

offset 可以指定从大于等于 0 的具体 offset,或者:
OFFSET_BEGINNING: 从有数据的位置开始订阅。
OFFSET_END: 从末尾开始订阅。
时间格式,如:"2021-05-22 11:00:00"
如果没有指定,则默认从 OFFSET_END 开始订阅 topic 下的所有 partition。第3步:检查流任务状态(SHOW ROUTINE LOAD \G)
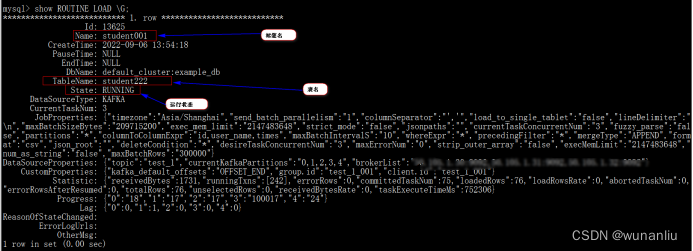
第4步:Kafka推送测试数据

第5步:查询Doris数据库数据
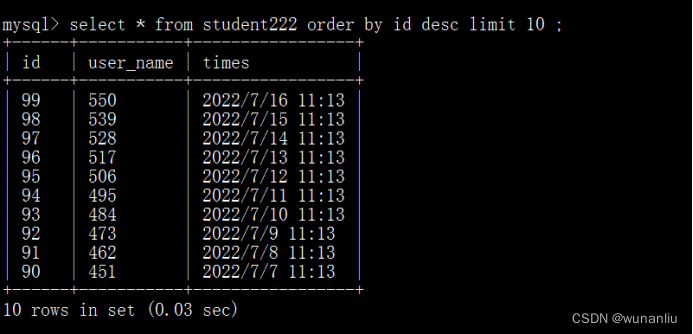
第六步:【重要说明】
show ROUTINE LOAD \G;
查看日志
取消
stop ROUTINE LOAD for 任务名称
stop ROUTINE LOAD for student001;
启动
resume routine load for student222;
- "max_batch_interval" = "20", 每个子任务最大执行时间,单位是秒。范围为 5 到 60。默认为10。
- "max_batch_rows" = "300000", 每个子任务最多读取的行数。必须大于等于200000。默认是200000。
- "max_batch_size" = "209715200"每个子任务最多读取的字节数。单位是字节,范围是 100MB 到 1GB。默认是 100MB。
- 这三个参数,用于控制一个子任务的执行时间和处理量。当任意一个达到阈值,则任务结束。
4、Mysql外部表数据引用导入(支持CDC模式)
第一步:安装unixODBC相关依赖
yum install -y unixODBC unixODBC-devel libtool-ltdl libtool-ltdl-devel
查看是否安装成功- [root@localhost ~]# odbcinst -j
- unixODBC 2.3.1
- DRIVERS............: /etc/odbcinst.ini
- SYSTEM DATA SOURCES: /etc/odbc.ini
- FILE DATA SOURCES..: /etc/ODBCDataSources
- USER DATA SOURCES..: /root/.odbc.ini
- SQLULEN Size.......: 8
- SQLLEN Size........: 8
- SQLSETPOSIROW Size.: 8
第二步:安装ODBC

当前我的数据库版本为5.7 所以下载下面链接地址文件即可。
wget https://downloads.mysql.com/archives/get/p/10/file/mysql-connector-odbc-5.3.11-1.el7.x86_64.rpm
下载完毕 在下载文件夹下面 进行安装
yum install -y mysql-connector-odbc-5.3.11-1.el7.x86_64.rpm
本博主已经下载:
链接:https://pan.baidu.com/s/12gPrDaDI7XyaJt4-mRd4Lg
提取码:k0rl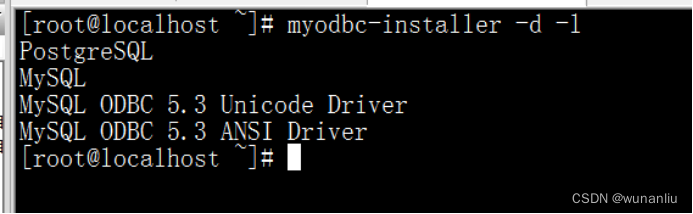
所有BE节点都要相同操作 安装。
第3步:配置 unixODBC,验证通过 ODBC 访问 Mysql(相当于对服务器进行ODBC安装,同时测试客户端)
编辑 ODBC 配置文件 【3台服务器】
- vim /etc/odbc.ini
- [mysql]
- Description = Data source MySQL
- Driver = MySQL ODBC 5.3 Unicode Driver
- Server = hadoop1 【mysql服务器IP的hostname】
- Host = hadoop1 【mysql服务器IP的hostname】
- Database = test 【mysql数据库】
- Port = 3306 【数据库端口】
- User = root 【mysql用户名】
- Password = xxxxxx 【mysql密码】
测试链接 【3台服务器】
isql -v mysql
第三步、准备MYSQL 测试表和数据
- CREATE TABLE `test_cdc` (
- `id` int NOT NULL AUTO_INCREMENT,
- `name` varchar(255) DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB AUTO_INCREMENT=91234 DEFAULT CHARSET=utf8mb4;
- 插入数据
- INSERT INTO `test_cdc` VALUES (123, 'this is a update');
- INSERT INTO `test_cdc` VALUES (1212, '测试 flink CDC');
- INSERT INTO `test_cdc` VALUES (1234, '这是测试');
- INSERT INTO `test_cdc` VALUES (11233, 'zhangfeng_1');
- INSERT INTO `test_cdc` VALUES (21233, 'zhangfeng_2');
- INSERT INTO `test_cdc` VALUES (31233, 'zhangfeng_3');
- INSERT INTO `test_cdc` VALUES (41233, 'zhangfeng_4');
- INSERT INTO `test_cdc` VALUES (51233, 'zhangfeng_5');
- INSERT INTO `test_cdc` VALUES (61233, 'zhangfeng_6');
- INSERT INTO `test_cdc` VALUES (71233, 'zhangfeng_7');
- INSERT INTO `test_cdc` VALUES (81233, 'zhangfeng_8');
- INSERT INTO `test_cdc` VALUES (91233, 'zhangfeng_9');
第四步:修改 Doris 的配置文件(每个 BE 节点都要,不用重启 BE)
在 BE 节点的 conf/odbcinst.ini,添加我们的刚才注册的的 ODBC 驱动([MySQL ODBC
5.3.11] 红色这部分)# Driver from the postgresql-odbc package
# Setup from the unixODBC package
[PostgreSQL]
Description = ODBC for PostgreSQL
Driver = /usr/lib/psqlodbc.so
Setup = /usr/lib/libodbcpsqlS.so
FileUsage = 1
# Driver from the mysql-connector-odbc package
# Setup from the unixODBC package
[MySQL ODBC 5.3.11] 【此处名称不允许修改写错 后面需要用到】
Description = ODBC for MySQL
Driver= /usr/lib64/libmyodbc5w.so
FileUsage = 1
# Driver from the oracle-connector-odbc package
# Setup from the unixODBC package
[Oracle 19 ODBC driver]
Description=Oracle ODBC driver for Oracle 19
Driver=/usr/lib/libsqora.so.19.1
第五步:Doris 建 Resource表
通过 ODBC_Resource 来创建 ODBC 外表,这是推荐的方式,这样 resource 可以复用。
CREATE EXTERNAL RESOURCE `mysql_5_3_11`
PROPERTIES (
"host" = "hadoop1", 【mysql服务器IP的hostname】
"port" = "3306", 【Mysql端口】
"user" = "root", 【Mysql用户名】
"password" = "XXXXX", 【Mysql密码】
"database" = "test", 【Mysql数据库】
"table" = "test_cdc", 【Mysql需要的外表】
"driver" = "MySQL ODBC 5.3.11", 【名称要和上面[]里的名称一致,BE的配置文件头】
"odbc_type" = "mysql", 【固定】
"type" = "odbc_catalog") 【固定】
第六步:基于 Resource 创建 Doris 外表
CREATE EXTERNAL TABLE `test_odbc` (
`id` int NOT NULL , 【和Mysql字段相同】
`name` varchar(255) null 【和Mysql字段相同】
) ENGINE=ODBC 【固定引擎】
COMMENT "ODBC"
PROPERTIES (
"odbc_catalog_resource"="mysql_5_3_11",【名称就是 resource 的名称】
"database" = "test", 【同步的数据库】
"table" = "test_cdc" 【同步的表】
);
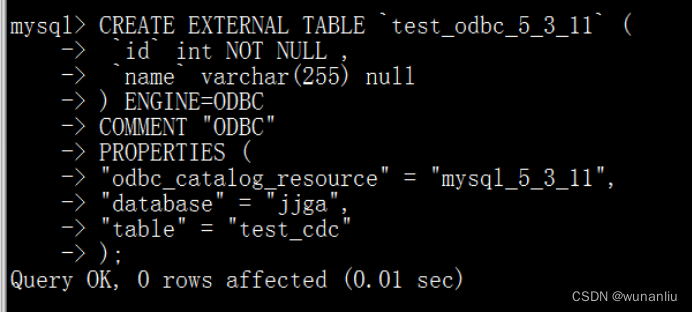
第七步:查询数据 ,检查Mysql数据库完全相同

第八步:测试修改Mysql数据
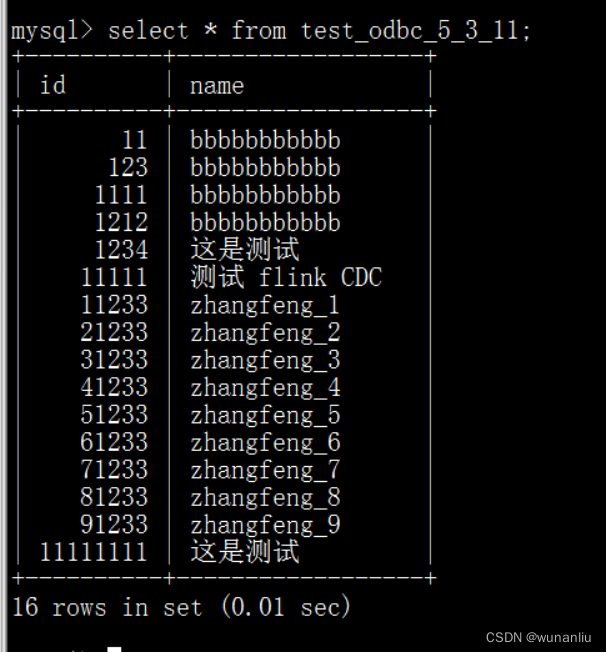
修改Mysql 数据库 Doris 外表数据相同
备份说明:Doris 数据库同样支持Mysql的数据库文件备份命令,mysqldump
eg:/usr/local/mysql/bin/mysqldump -u用户名 -p密码 --databases 数据库 > /home/mysqlDataBak/$(date "+%Y%m%d%H")_jjga_mydb.sql
-
相关阅读:
基于html+css的图展示118
JAVA集合02_List集合的概述、并发修改异常、迭代器遍历、子类对比
c++入门必学库函数 memset
【数据结构初阶】五、线性表中的栈(顺序表实现栈)
C++多线程学习07 unique_lock与scoped_lock
使用pyvista显示有透明度信息的点云数据
Javascript知识【案例:重写省市联动&案例:列表左右选择】
JavaScript中的模板直面量
SpringBoot集成monogoDB
Python安装指南:安装Python、配置Python环境(附安装包)
- 原文地址:https://blog.csdn.net/weixin_38822045/article/details/126751130
