-
Transformer【第五章】
Seq2seq
Transformer 是一个 Sequence-to-sequence 的 Model(缩写 Seq2seq)
input 是 一个 sequence,output 是一个 sequence,但是不知道多长,由机器自己决定 output 的长度。
应用:语音辨识,机器翻译,语音翻译

一般的 Seq2seq model 可以分为两块:Encoder + Decoderinput 一个 sequence,由 Encoder 负责处理这个 sequence,再把处理好的结果丢给 Decoder,由 Decoder 决定它要输出什么样的 sequence。

Encoder
作用:给一排向量输出另外一排向量(相同长度),Transformer 的 Encoder 使用的就是 Self-attention。

Encoder 中分为很多 block,每个 block 都是输入一排向量,输出一排向量,每个 block 实际并不是 Neuron Network 的一层,每个 block 作的事情,是好几个 layer 在作的事情:Self-attention、再丢到 FC 中,output 另外一排 vector(就是 block 的输出)
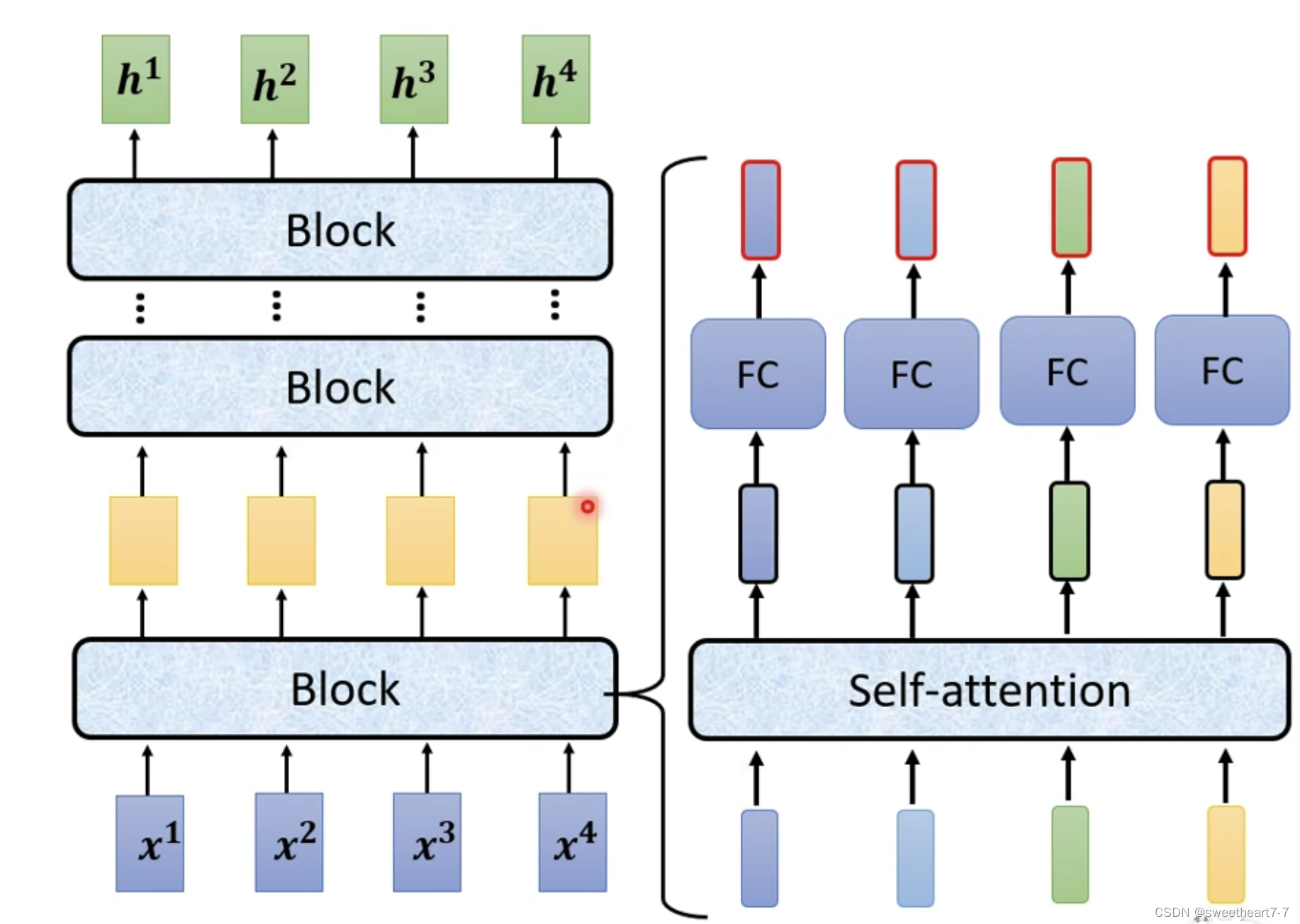
在原来的 Transformer 里面更复杂:
在 self-attention 的输出后加上原来的 input 的 vector,得到新的 ouput(残差网络),然后作 normalization(layer normalization),然后作为 FC 的输入,FC 也有 Residual 的架构,即将 FC 的输出加上 FC 的输入再作 layer normalization,然后作为 Block 的输出。

Decoder
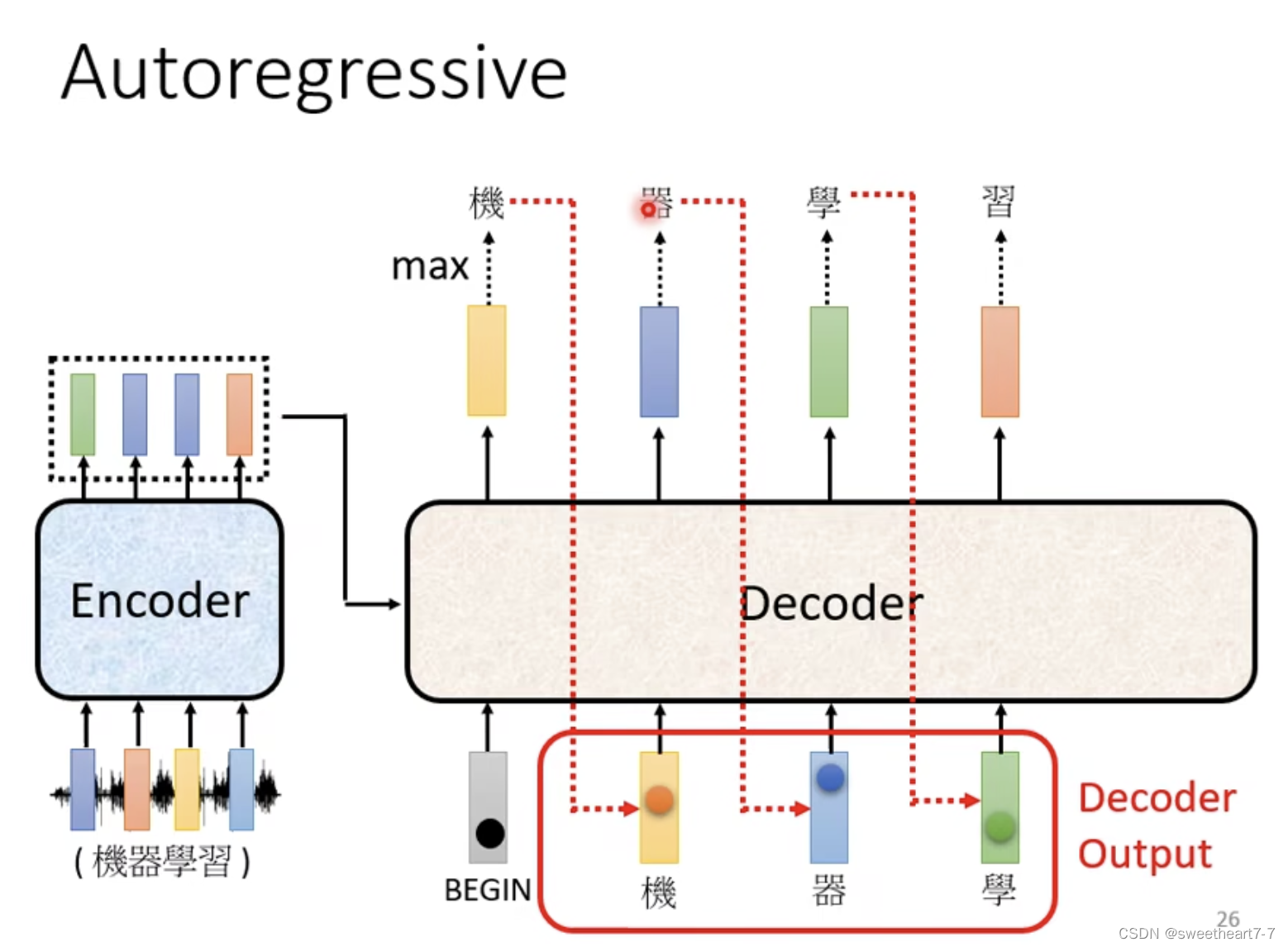
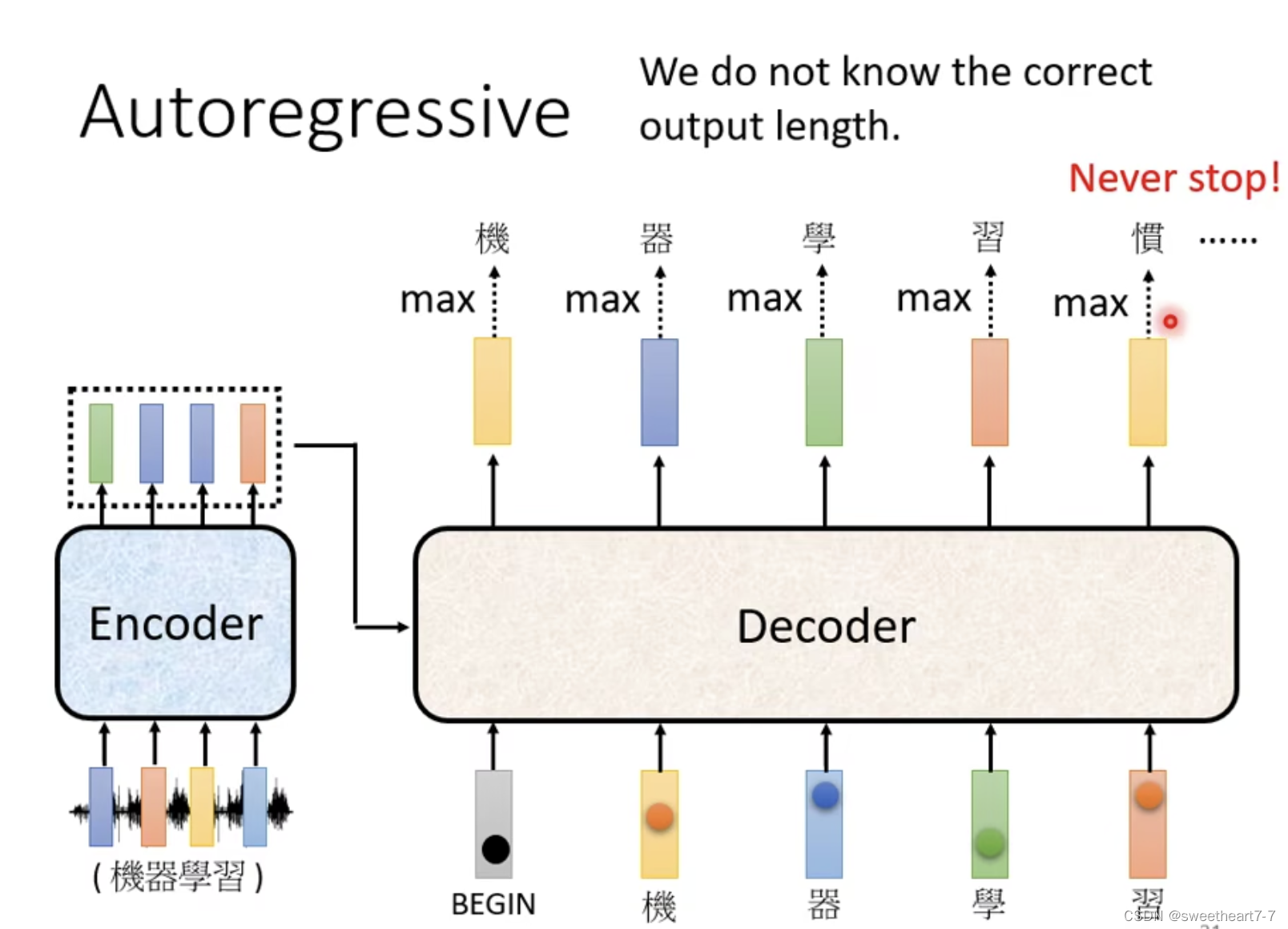
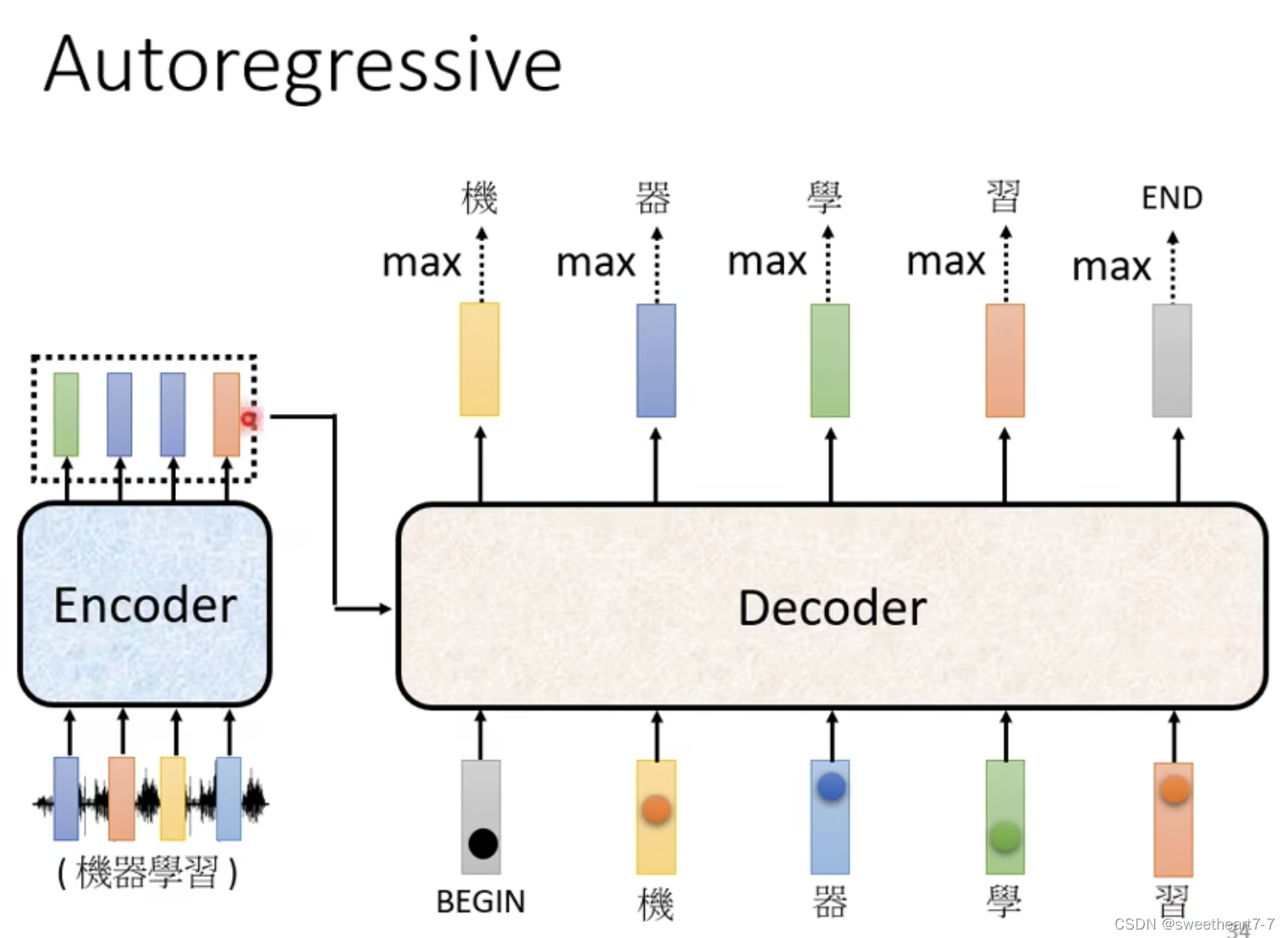
Autoregressive
Decoder 产生输出
Decoder 先将 Encoder 的输出先读进去。
Decoder 如何产生一段文字:
- 先给它一个特殊符号代表开始(BOS)一个 Special 的 token
- Decoder 吃到这个特殊的符号,每个 Token 都可以用 One-Hot 的 Vector 表示(其中一维是 1,其它是 0)
- Decoder 输出一个 vector,大小和 Vocabulary 的 size 一样(通过 softmax 来确定输出是哪个字),然后再将 Encoder的输出、 begin、 跟这个字的 One-Hot 的 Vector 作为 Decoder 的下一个输入,然后再得到输出,依次类推…,
Decoder 的结构:
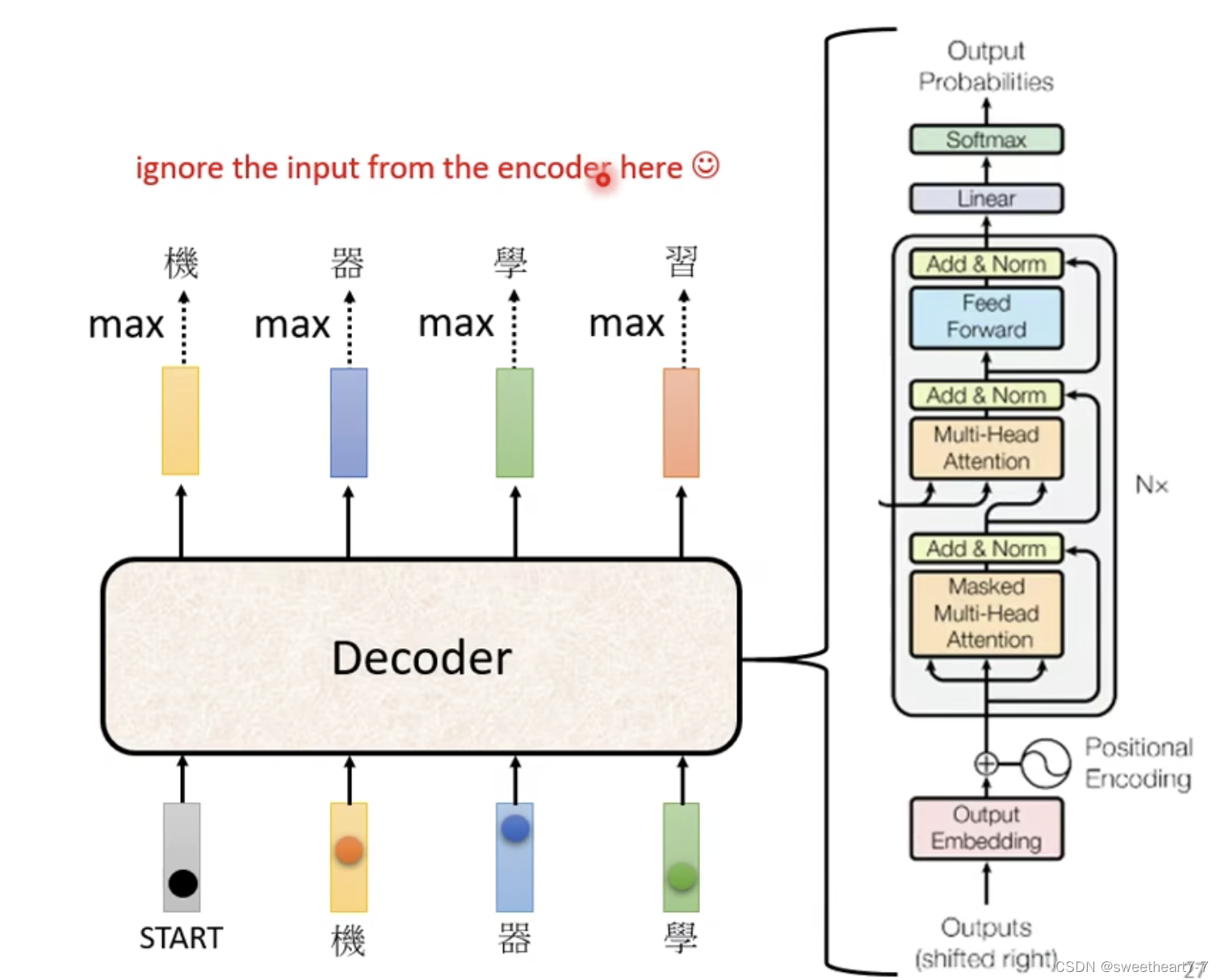
Encoder 和 Decoder 的区别:
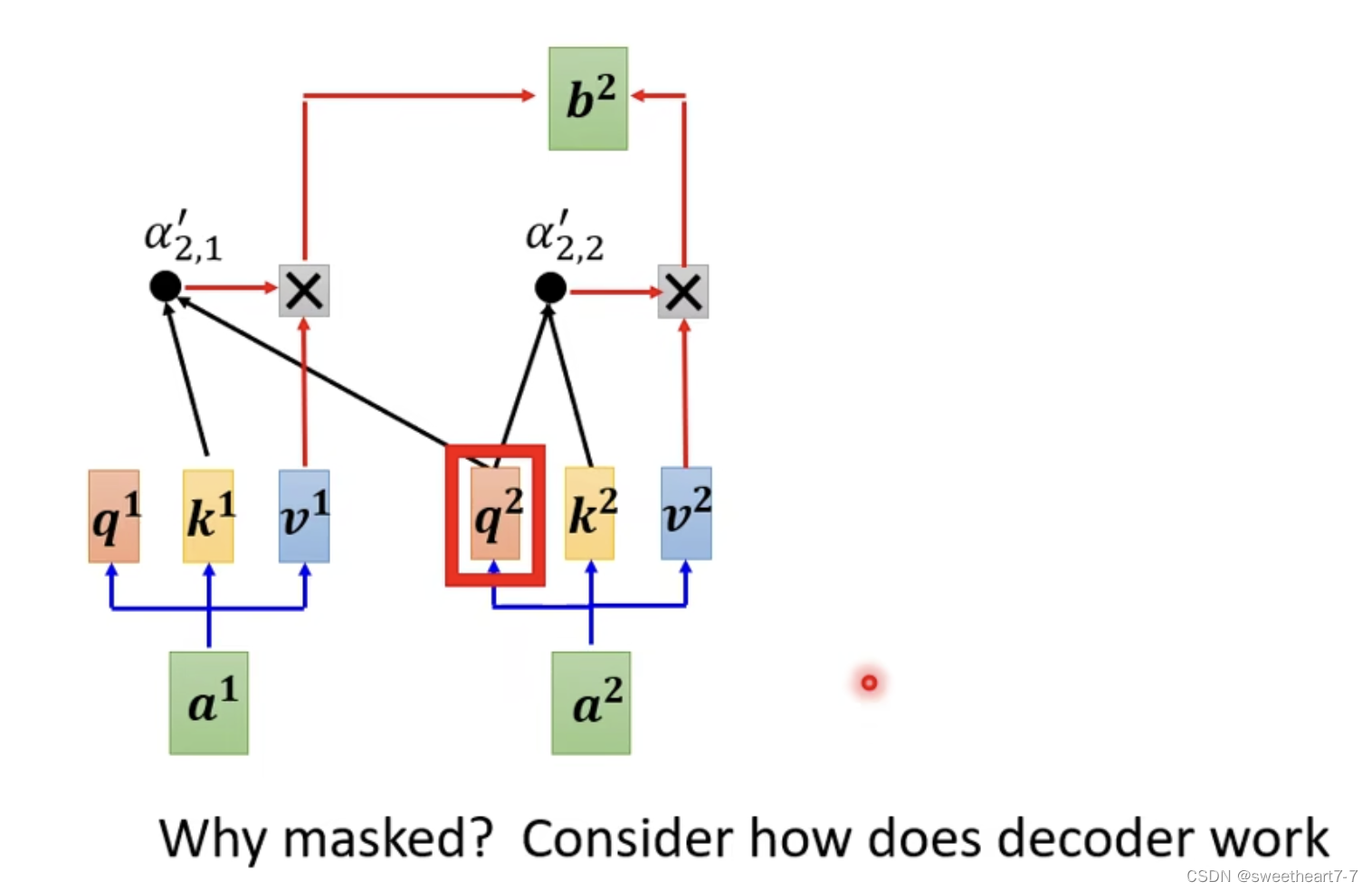
除了遮着的地方 和 Masked Self-attention,其它基本相似
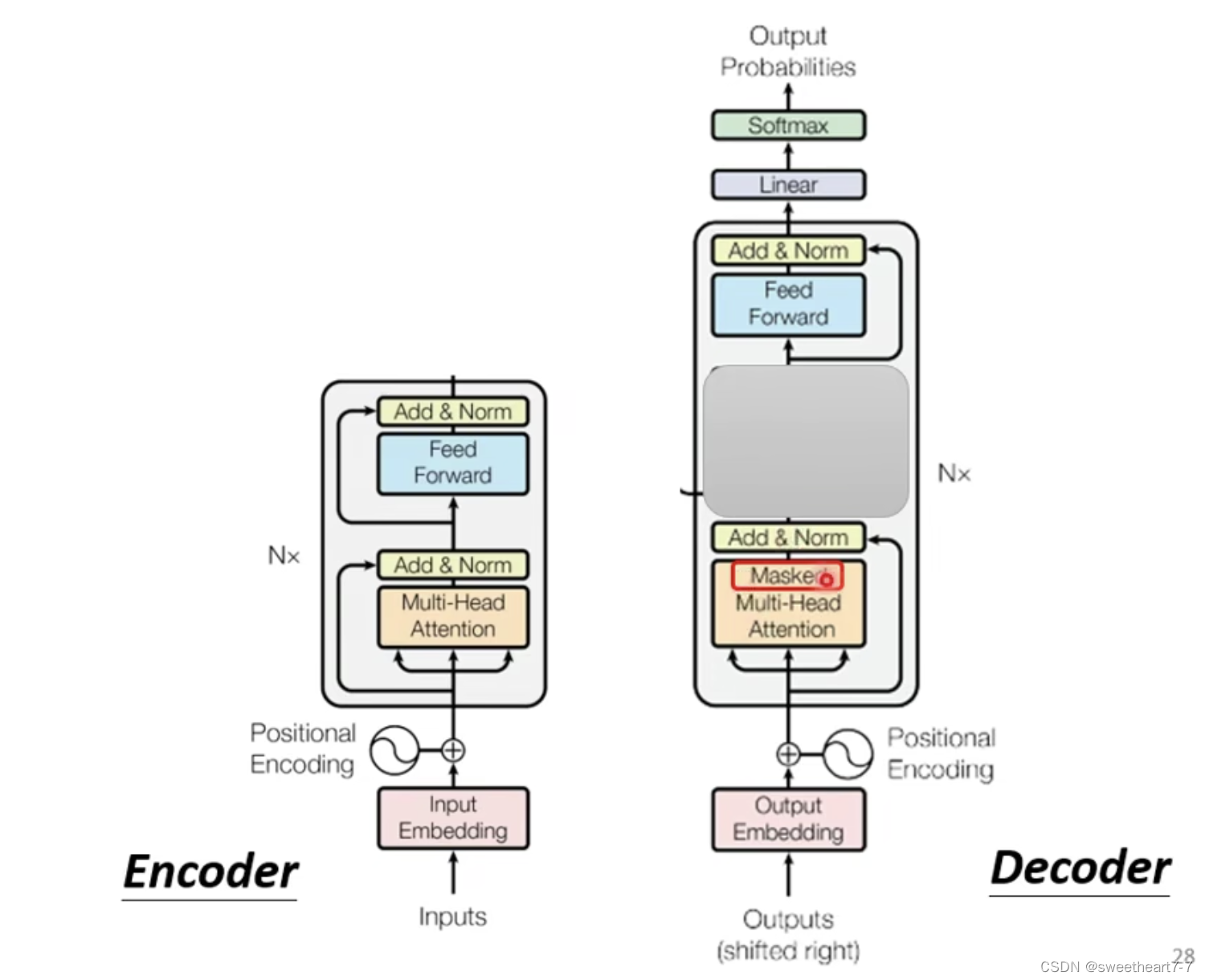
Masked Self-attention (不考虑右边的)因为 Decoder 的输入是从左边输出产生的,没办法看到右边。

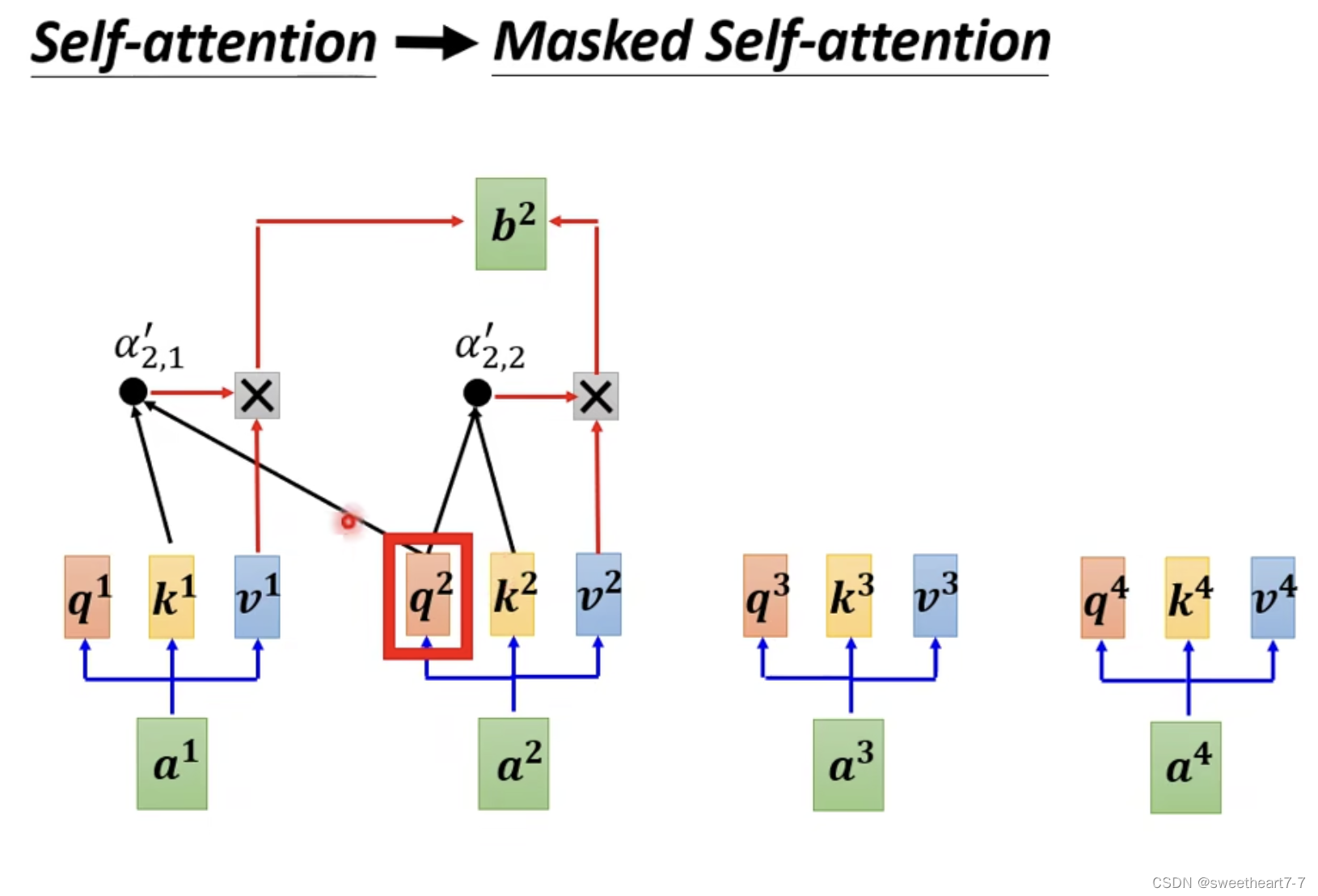
q q q 只和自己及左边的 k k k 相乘。
Decoder 决定输出的长度。
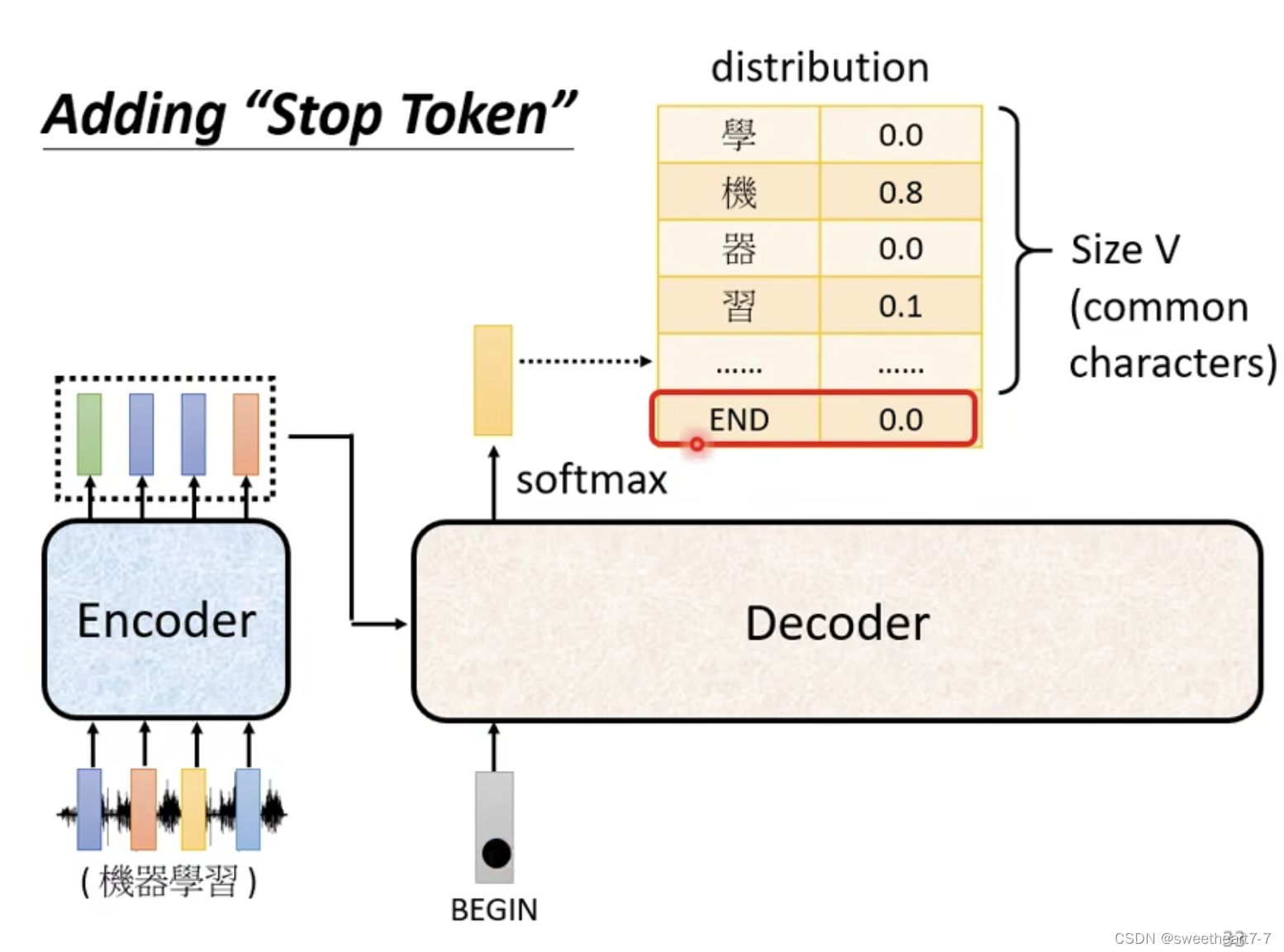
需要加一个特殊的符号,表示结束。
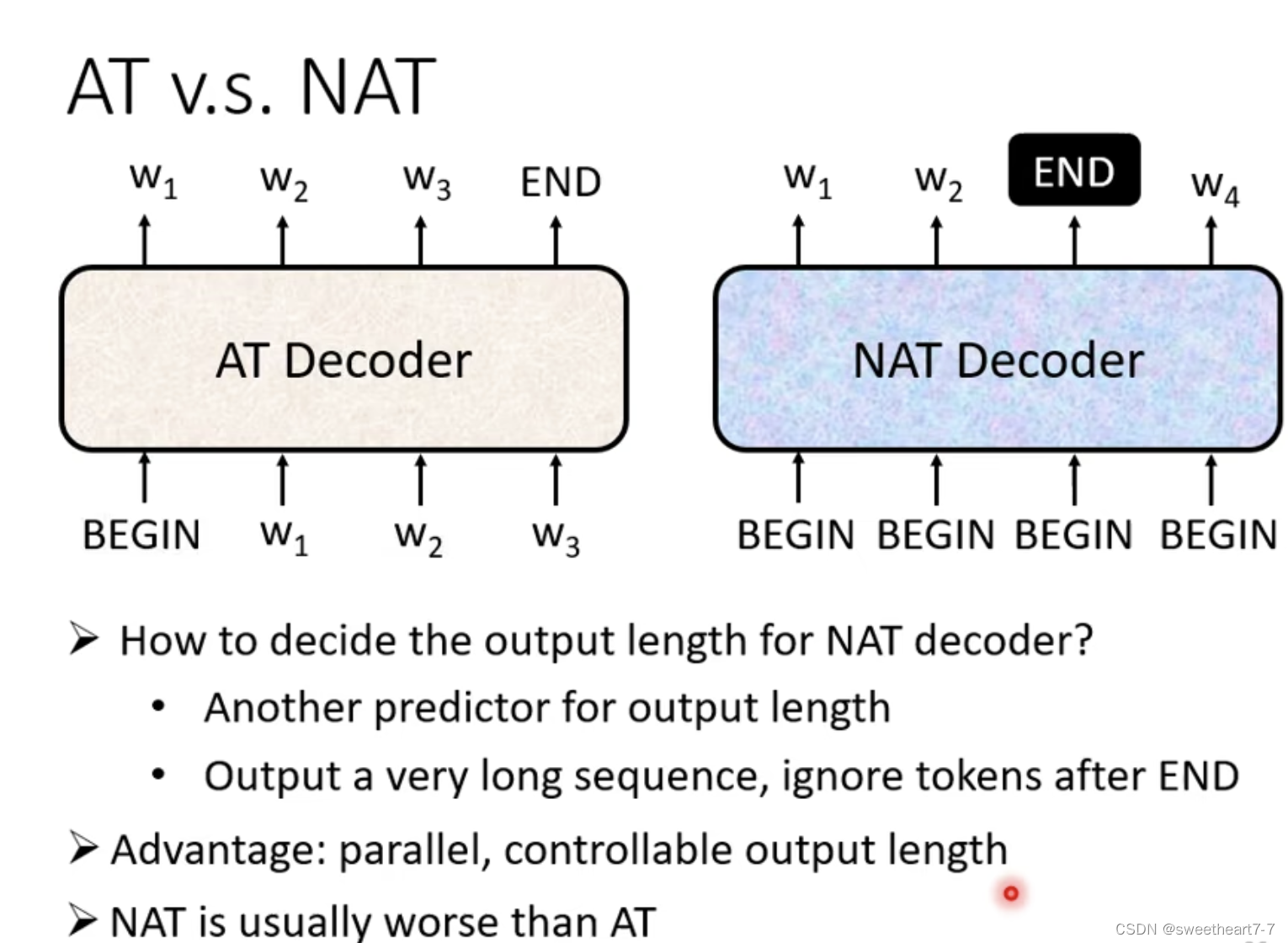
Non-autoregressive
一次产生整个句子:
- Classifier 来决定输入的 Begin 的数量
- 确定最长长度的 begin,然后将输出在 End 处截断。
Encoder-Decoder (Cross attention)
Cross attention(连接 Encoder 和 Decoder 的桥梁)
有两个输入来自 Encoder,一个来自 Decoder。
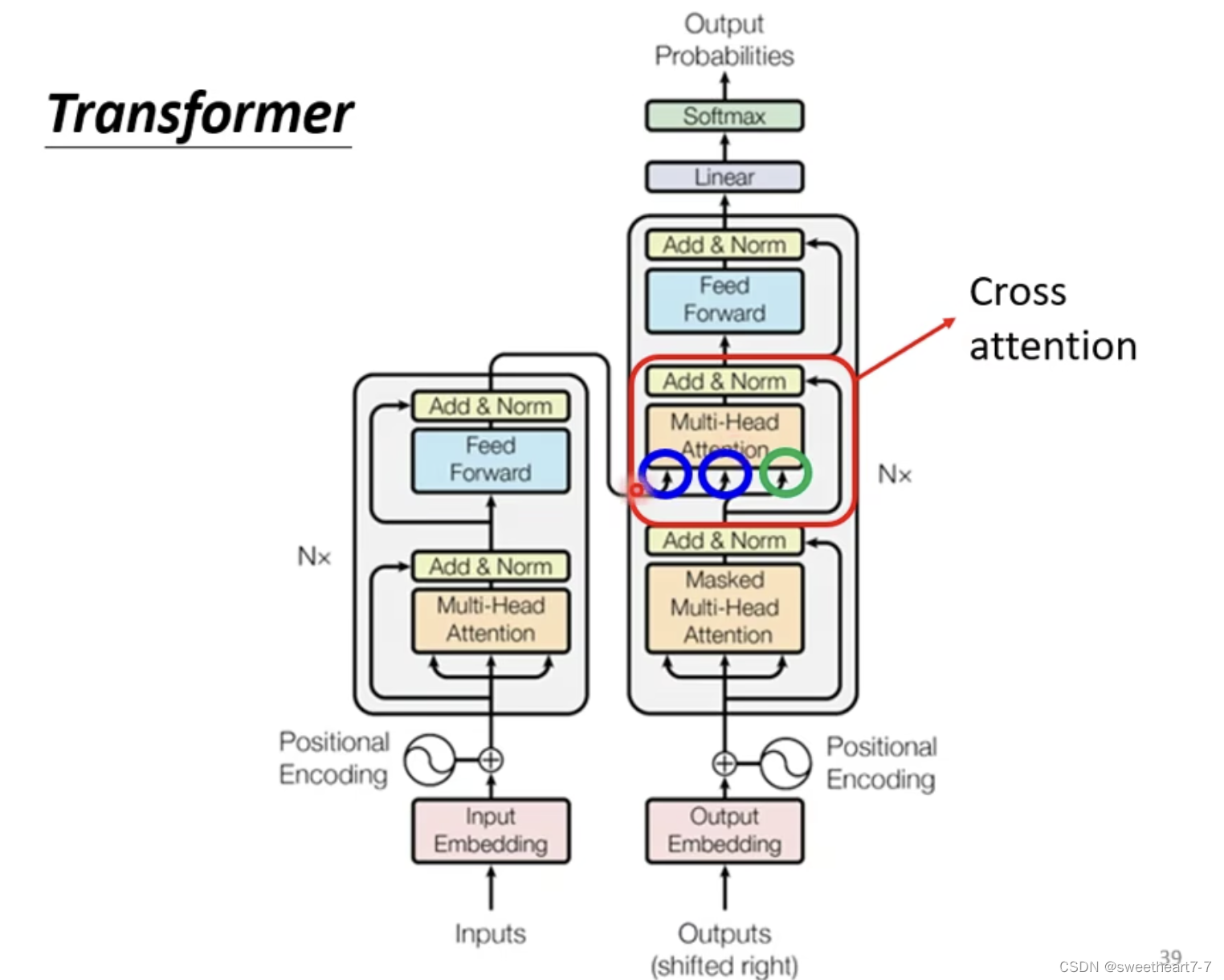
Encoder 的输出是 a 1 , a 2 , a 3 a_1,a_2,a_3 a1,a2,a3,begin 经过 Self-attention(Mask),产生一个向量,然后将这个向量乘一个矩阵得到向量 Query q q q, a 1 , a 2 , a 3 a_1,a_2,a_3 a1,a2,a3 产生 k 1 , k 2 , k 3 k^1,k^2,k^3 k1,k2,k3和 v 1 , v 2 , v 3 v^1,v^2,v^3 v1,v2,v3,然后将 a 1 , a 2 , a 3 a_1,a_2,a_3 a1,a2,a3 和 k 1 , k 2 , k 3 k^1,k^2,k^3 k1,k2,k3 计算 attention 的分数,得到 α 1 , α 2 , α 3 α_1,α_2,α_3 α1,α2,α3,然后将 α 1 , α 2 , α 3 α_1,α_2,α_3 α1,α2,α3 分别乘 v 1 , v 2 , v 3 v^1,v^2,v^3 v1,v2,v3,然后再把其加起来的到 v v v,然后再经过 F C FC FC。
Cross attention: q q q 来自 Decoder, k k k 和 v v v 来自 Encoder

下一个输出的产生同上

Training
跟分类很像。

Decoder 每次的输出都是 One-hot 的 vector
分别对每一个 Decoder 的输出作 Cross Entropy,来训练。训练的时候,给它正确的答案作为 Decoder 的输入。

-
相关阅读:
Mybatis保存时参数携带了逗号和空格导致SQL保存异常
JavaScript逻辑题:一个篮球的高度为100米 每次落地弹起高度为前一次高度的0.6 问多少次之后高度小于1米?
逻辑回归算法推理与实现
rsync 远程同步
力扣第617题 合并二叉树 c++ 前中后序 完成 附加迭代版本
前缀和与树状数组(数据结构基础篇)
码蹄集 - MT2201 · 各位之和
【Codeforces 1367F】 Flying Sort (Hard Version)
项目自动化构建工具——make/Makefile
前后端数据传输的两者方法——GET和POST
- 原文地址:https://blog.csdn.net/qq_46456049/article/details/126711860