-
Pytorch autograd.grad与autograd.backward详解
Pytorch autograd.grad与autograd.backward详解
引言
平时在写 Pytorch 训练脚本时,都是下面这种无脑按步骤走:
outputs = model(inputs) # 模型前向推理 optimizer.zero_grad() # 清除累积梯度 loss.backward() # 模型反向求导 optimizer.step() # 模型参数更新- 1
- 2
- 3
- 4
对用户屏蔽底层自动微分的细节,使得用户能够根据简单的几个 API 将模型训练起来。这对于初学者当然是极好的,也是 Pytorch 这几年一跃成为最流行的深度学习框架的主要原因:易用性。
但是,我们有时需要深究自动微分的机制,比如元学习方法 MAML (参考 Pytorch 代码)中,需要分别根据支持集和查询集的梯度按照不同的策略更新模型参数。这时还是需要了解一些 Pytorch 框架的自动微分机制。幸运的是,Pytorch 关于这部分的框架设计也很清晰,在参考了几个博客之后,笔者将自己的对 Pytorch 自动微分机制接口总结在这里。
注意只是自动微分机制的 Python 接口,而非底层实现。
背景知识
计算图
当今主流深度学习框架的计算图主要有两种形式:静态图(TensoFlow 1.x、Caffe …)和动态图(Pytorch …)。两者的却别简单说来就是:静态图是在模型确定之后就先生成一张计算图,然后每次对于不同的输入样本,都直接丢到计算图中跑;而动态图则是对于每次样本输入都重新构建一张计算图。从它们的区别也可以感受到它们彼此最重要的优劣势:静态图速度快但是不够灵活,动态图灵活但速度稍慢。
在今天,各个框架中动态图与静态图的区分也没有那么绝对了。比如 TensorFlow 2.0 已经采用动态图,而 Pytorch 也可通过 scripting/tracing 转换成 JIT torchscript 静态图。但这不是本文的重点,对深度学习框架计算图感兴趣可参考:机器学习系统:设计与实现 计算图。
我们要讨论的是 Pytorch 的自动微分机制,Pytorch 中主要是动态图,即计算图的搭建和计算是同时的,对每次输入都是重新建图计算。在 Pytorch 的计算图里有两种元素:数据(tensor)和 运算(operation)。
- 运算:包括了加减乘除、开方、幂指对、三角函数等可微分运算。
- 数据:在 Pytorch 中,数据的形式一般就是张量 torch.Tensor。
tensor
Pytorch 中 tensor 具有如下属性:
-
requires_grad:是否需要求导
- 关于 requires_grad 属性的默认值。自己定义的叶子节点默认为 False,而非叶子节点默认为 True,神经网络中的权重默认为 True。判断哪些节点是True/False 的一个原则就是从你需要求导的叶子节点到 loss 节点之间是一条可求导的通路,这条通路上的节点的 requires_grad 都应当是 True。
-
grad_fn:当前节点是经过什么运算(如加减乘除等)得到的
-
grad:导数值
-
data:tensor 的数据
-
is_leaf:是否为叶子节点
-
其他几个概念都比较好理解,这里解释一下什么是叶子节点。
-
在 Pytorch 中,如果一个张量的 requires_grad=True,则进一步可分为:叶子节点和非叶子节点。叶子节点是用户创建的节点,不依赖其它节点,非叶子结点则是由叶子结点计算得到的中间张量。
a = torch.randn(2, 2).requires_grad_() b = a * 2 print(a.is_leaf, b.is_leaf) # 输出:True False- 1
- 2
- 3
- 4
-
对于 requires_grad=False 的 tensor 来说,我们约定俗成地把它们归为叶子张量。但其实无论如何划分都没有影响,因为张量的 is_leaf 属性只有在需要求导的时候才有意义。
-
由于叶子节点是用户创建的,所以它的 grad_fn 为空,而非叶子节点都是经过运算得到的,所以 grad_fn 非空
-
叶子/非叶子表现出来的区别在于:反向传播结束之后,非叶子节点的梯度会被释放掉,只保留叶子节点的梯度,这样就节省了内存。如果想要保留非叶子节点的梯度,可以使用 retain_grad() 方法。
-
关于 Pytorch tensor 的更多细节,可参考:浅谈 PyTorch 中的 tensor 及使用 。
一个例子
以下例子来自:PyTorch 的 Autograd。
了解过背景知识之后,现在我们来看一个具体的计算例子,先用最常见的梯度反传方式
loss.backward(),并画出它的正向和反向计算图。假如我们需要计算这么一个模型:l1 = input x w1 l2 = l1 + w2 l3 = l1 x w3 l4 = l2 x l3 loss = mean(l4)- 1
- 2
- 3
- 4
- 5
这个例子比较简单,涉及的最复杂的操作是求平均,但是如果我们把其中的加法和乘法操作换成卷积,那么其实和神经网络类似。我们可以简单地画一下它的计算图,其中绿色节点表示叶子节点:
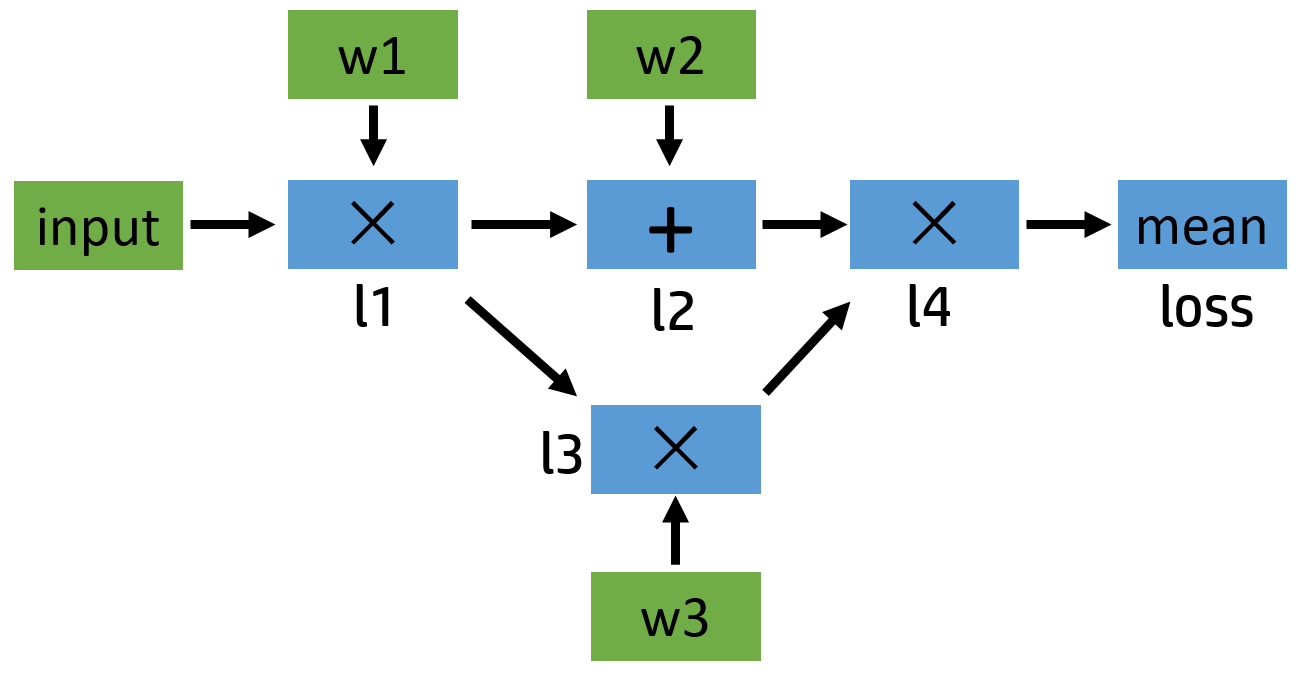
图1:正向计算图 下面给出了对应的代码,我们定义了 input,w1,w2,w3 这三个变量,其中 input 不需要求导结果。根据 Pytorch 默认的求导规则,对于 l1 来说,因为有一个输入需要求导(也就是 w1 需要),所以它自己默认也需要求导,即 requires_grad=True(即前面提到的 ”是否在需要求导的通路上“ ,如果对这个规则不熟悉,欢迎参考 浅谈 PyTorch 中的 tensor 及使用 或者直接查看 官方 Tutorial 相关部分)。在整张计算图中,只有 input 一个变量是 requires_grad=False 的。正向传播过程的具体代码如下:
input = torch.ones([2, 2], requires_grad=False) w1 = torch.tensor(2.0, requires_grad=True) w2 = torch.tensor(3.0, requires_grad=True) w3 = torch.tensor(4.0, requires_grad=True) l1 = input * w1 l2 = l1 + w2 l3 = l1 * w3 l4 = l2 * l3 loss = l4.mean() print(w1.data, w1.grad, w1.grad_fn) # tensor(2.) None None print(l1.data, l1.grad, l1.grad_fn) # tensor([[2., 2.], # [2., 2.]]) Noneprint(loss.data, loss.grad, loss.grad_fn) # tensor(40.) None - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
正向传播的结果基本符合我们的预期。我们可以看到,变量 l1 的 grad_fn 储存着乘法操作符
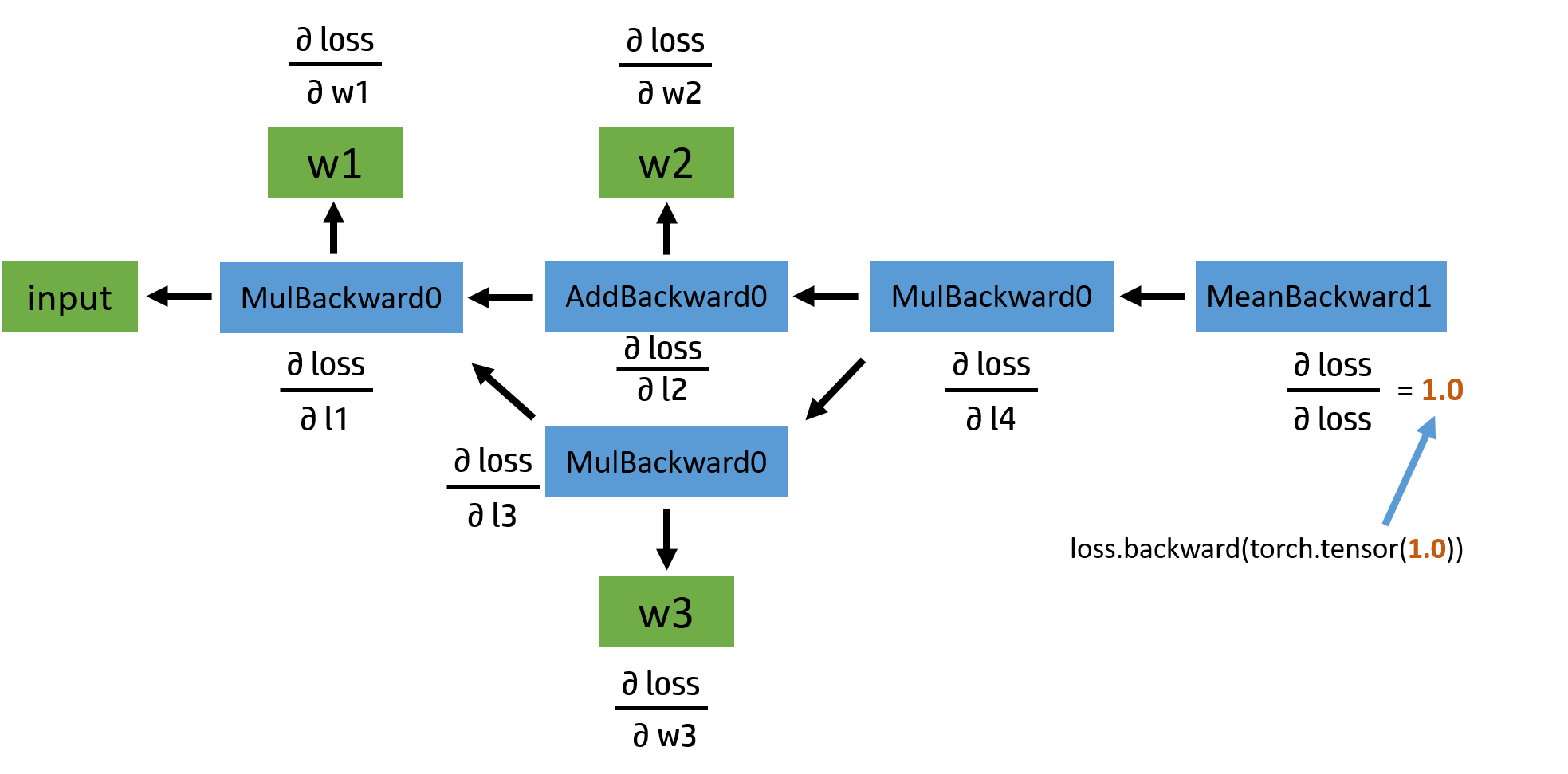
图2:反向计算图 反向图也比较简单,从 loss 这个变量开始,通过链式法则,依次计算出各部分的导数。说到这里,我们不妨先自己手动推导一下求导的结果,再与程序运行结果作对比。如果对这部分不感兴趣的读者,可以直接跳过。
再摆一下公式:
input = [1.0, 1.0, 1.0, 1.0] w1 = [2.0, 2.0, 2.0, 2.0] w2 = [3.0, 3.0, 3.0, 3.0] w3 = [4.0, 4.0, 4.0, 4.0] l1 = input x w1 = [2.0, 2.0, 2.0, 2.0] l2 = l1 + w2 = [5.0, 5.0, 5.0, 5.0] l3 = l1 x w3 = [8.0, 8.0, 8.0, 8.0] l4 = l2 x l3 = [40.0, 40.0, 40.0, 40.0] loss = mean(l4) = 40.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
首先 l o s s = 1 4 ∑ i = 0 3 l 4 i loss=\frac{1}{4}\sum_{i=0}^3l_4^i loss=41∑i=03l4i , 所以 l o s s loss loss 对 l 4 i l_4^i l4i 的偏导分别为 ∂ l o s s ∂ l 4 i = 1 4 \frac{\partial loss}{\partial l_4^i}=\frac{1}{4} ∂l4i∂loss=41 ;
接着 ∂ l 4 ∂ l 3 = l 2 = [ 5.0 , 5.0 , 5.0 , 5.0 ] \frac{\partial l_4}{\partial l_3}=l_2=[5.0,5.0,5.0,5.0] ∂l3∂l4=l2=[5.0,5.0,5.0,5.0] , 同时 ∂ l 4 ∂ l 2 = l 3 = [ 8.0 , 8.0 , 8.0 , 8.0 ] \frac{\partial l_4}{\partial l_2}=l_3=[8.0,8.0,8.0,8.0] ∂l2∂l4=l3=[8.0,8.0,8.0,8.0] ;
现在看 l 3 l_3 l3 对它的两个变量的偏导:
∂ l 3 ∂ l 1 = w 3 = [ 4.0 , 4.0 , 4.0 , 4.0 ] \frac{\partial l_3}{\partial l_1}=w3=[4.0,4.0,4.0,4.0] ∂l1∂l3=w3=[4.0,4.0,4.0,4.0], ∂ l 3 ∂ w 3 = l 1 = [ 2.0 , 2.0 , 2.0 , 2.0 ] \frac{\partial l_3}{\partial w_3}=l1=[2.0,2.0,2.0,2.0] ∂w3∂l3=l1=[2.0,2.0,2.0,2.0]
因此 ∂ l o s s ∂ w 3 = ∂ l o s s ∂ l 4 ∂ l 4 ∂ l 3 ∂ l 3 ∂ w 3 = [ 2.5 , 2.5 , 2.5 , 2.5 ] \frac{\partial loss}{\partial w_3}=\frac{\partial loss}{\partial{l_4}}\frac{\partial{l_4}}{\partial{l_3}}\frac{\partial{l_3}}{\partial w_3}=[2.5,2.5,2.5,2.5] ∂w3∂loss=∂l4∂loss∂l3∂l4∂w3∂l3=[2.5,2.5,2.5,2.5] , 其和为 10 ;
同理,再看一下求 w 2 w_2 w2 导数的过程: ∂ l o s s ∂ w 2 = ∂ l o s s ∂ l 4 ∂ l 4 ∂ l 2 ∂ l 2 ∂ w 3 = [ 2.0 , 2.0 , 2.0 , 2.0 ] \frac{\partial loss}{\partial w_2}=\frac{\partial loss}{\partial{l_4}}\frac{\partial{l_4}}{\partial{l_2}}\frac{\partial{l_2}}{\partial w_3}=[2.0,2.0,2.0,2.0] ∂w2∂loss=∂l4∂loss∂l2∂l4∂w3∂l2=[2.0,2.0,2.0,2.0] ,其和为 8。
其他的导数计算基本上都类似,因为过程太多,这里就不全写出来了,如果有兴趣的话大家不妨自己继续算一下。
接下来我们继续运行代码,并检查一下结果和自己算的是否一致:
loss.backward() print(w1.grad, w2.grad, w3.grad) # tensor(28.) tensor(8.) tensor(10.) print(l1.grad, l2.grad, l3.grad, l4.grad, loss.grad) # None None None None None- 1
- 2
- 3
- 4
- 5
- 6
首先我们需要注意一下的是,在之前写程序的时候我们给定的 w 们都是一个常数,利用了广播的机制实现和常数和矩阵的加法乘法,比如 w2 + l1,实际上我们的程序会自动把 w2 扩展成 [[3.0, 3.0], [3.0, 3.0]],和 l1 的形状一样之后,再进行加法计算,计算的导数结果实际上为 [[2.0, 2.0], [2.0, 2.0]],为了对应常数输入,所以最后 w2 的梯度返回为矩阵之和 8 。
另外还有一个问题,注意到 l1,l2,l3,以及其他的部分的求导结果都为空。这验证了我们之前提到的叶子结点的概念,对于非叶子几点,不会保留其梯度值,如果一定要保留,需要设置 retain_graph=True。
torch.autograd:grad与backward
自动微分机制是深度学习框架的核心,对于 Pytorch 也不例外。 [Pytorch autograd官方文档][https://pytorch.org/docs/stable/autograd.html#]指出,Pytorch 中有两种方式可以实现反向传播求导,分别是
torch.auograd.grad和torch.autograd.backward。在我们日常搭建训练脚本的过程中,最常见的是
loss.backward()。其实这是与torch.autograd.backward(loss)是等价的,即上述后一种方式。两种方式的区别是:前者是返回参数的梯度值列表,而后者是直接修改各个 tensor 的 grad 属性。
接口定义
torch.autograd.backward
torch.autograd.backward( tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)- 1
- 2
- 3
- 4
- 5
- 6
- tensor:用于计算梯度的tensor。前面提到过以下两种方式是等价的:
torch.autograd.backward(z) == z.backward() - grad_tensors:在计算矩阵的梯度时会用到。也是一个tensor,shape一般需要和前面的 tensor 保持一致。
- retain_graph:通常在调用一次 grad/backward 后,Pytorch会自动把计算图销毁,所以要想对某个变量重复调用 backward,则需要将该参数设置为 True
- create_graph:当设置为 True 的时候可以用来计算更高阶的梯度
- grad_variables:这个官方说法是 ‘grad_variables’ is deprecated. Use ‘grad_tensors’ instead.也就是说这个参数后面版本中应该会丢弃,直接使用 grad_tensors 就好了。
torch.autograd.grad
torch.autograd.grad( outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- outputs:结果节点,通常是损失值
- inputs:需要求梯度的叶子节点,通常是模型参数
- grad_outputs:类似于 backward 方法中的 grad_tensors
- retain_graph:同上
- create_graph:同上
- only_inputs:默认为 True。如果为 True, 则只会返回指定 input 的梯度值。 若为 False,则会计算所有叶子节点的梯度,并且将计算得到的梯度累加到各自的grad属性上去。
- allow_unused:默认为 False, 即必须要指定input,如果没有指定的话则报错。
例子
还是通过一个例子来看:
import torch import torch.nn as nn class MyModel(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(in_channels=2, out_channels=2, kernel_size=1, padding=0, bias=False) self.conv2 = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=1, padding=0, bias=False) def forward(self, z): return self.conv2(self.conv1(z)) c = 2 h = 5 w = 5 lr = 0.01 inputs = torch.arange(0, c * h * w).float().view(1, c, h, w) model = MyModel() outputs = model(inputs) loss = outputs.sum() model.zero_grad() grad = torch.autograd.grad(loss, model.parameters(), retain_graph=True) # grad = torch.autograd.grad(loss, model.parameters()) # 注意这里需要 retain_grad = True,否则会报错: # RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward. loss.backward() for i, (name, param) in enumerate(model.named_parameters()): print("******************") print(name) print("grad using loss.backward: ", param.grad.data) print("grad using autograd.grad: ", grad[i]) print("******************") # 更新参数 # 相当于 optimizer.step() # theta_1 = theta_0 - lr * grad param.data.sub_(lr * param.grad.data) # 或者: # param.data.sub_(lr * grad[i])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
我们定义了一个简单的两层卷积模型,然后分别用 grad 和 backward 的方式来计算它们的梯度,并打印出来比较一下,发现是完全一致的。
如果想要根据梯度更新参数的话,也可以在拿到梯度之后,直接按照梯度下降的公式手动进行更新:
θ 1 = θ 0 − α ∇ θ 0 \theta_1=\theta_0-\alpha \nabla\theta_0 θ1=θ0−α∇θ0
这一步就相当于执行了optimizer.step(),它会使用封装好的优化器进行更新。求高阶导
如何求高阶导,比如求二阶导, 无非就是 grad_x 再对 x 求梯度:
x = torch.tensor(2.).requires_grad_() y = torch.tensor(3.).requires_grad_() z = x * x * y grad_x = torch.autograd.grad(outputs=z, inputs=x, retain_graph=True) grad_xx = torch.autograd.grad(outputs=grad_x, inputs=x) print(grad_xx[0]) # 报错:RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
报错了,虽然 retain_graph=True 保留了计算图和中间变量梯度, 但没有保存 grad_x 的运算方式,需要使用 create_graph=True 在保留原图的基础上再建立额外的求导计算图,也就是会把 ∂ z ∂ x = 2 x y \frac{\partial{z}}{\partial{x}}=2xy ∂x∂z=2xy 这样的运算存下来。
一阶二阶导我们可以分别用 autograd.grad 或者 backward 来做,即我们有四种排列组合,都是可以的:
# autograd.grad() + autograd.grad() x = torch.tensor(2.).requires_grad_() y = torch.tensor(3.).requires_grad_() z = x * x * y grad_x = torch.autograd.grad(outputs=z, inputs=x, create_graph=True) grad_xx = torch.autograd.grad(outputs=grad_x, inputs=x) print(grad_xx[0]) # 输出:tensor(6.)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
grad_xx 这里也可以直接用 backward,相当于直接从 ∂ z ∂ x = 2 x y \frac{\partial{z}}{\partial{x}}=2xy ∂x∂z=2xy 开始回传
# autograd.grad() + backward() x = torch.tensor(2.).requires_grad_() y = torch.tensor(3.).requires_grad_() z = x * x * y grad = torch.autograd.grad(outputs=z, inputs=x, create_graph=True) grad[0].backward() print(x.grad) # 输出:tensor(6.)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
也可以先用 backward 然后对 x.grad 这个一阶导继续求导
# backward() + autograd.grad() x = torch.tensor(2.).requires_grad_() y = torch.tensor(3.).requires_grad_() z = x * x * y z.backward(create_graph=True) grad_xx = torch.autograd.grad(outputs=x.grad, inputs=x) print(grad_xx[0]) # 输出:tensor(6.)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
那是不是也可以直接用两次 backward 呢?第二次直接 x.grad 从开始回传,我们试一下
# backward() + backward() x = torch.tensor(2.).requires_grad_() y = torch.tensor(3.).requires_grad_() z = x * x * y z.backward(create_graph=True) # x.grad = 12 x.grad.backward() print(x.grad) # 输出:tensor(18., grad_fn=) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
发现了问题,结果不是 6,而是18,发现第一次回传时输出 x 梯度是12。这是因为 Pytorch 使用 backward 时默认会累加梯度,需要手动把前一次的梯度清零
x = torch.tensor(2.).requires_grad_() y = torch.tensor(3.).requires_grad_() z = x * x * y z.backward(create_graph=True) x.grad.data.zero_() x.grad.backward() print(x.grad) # 输出:tensor(6., grad_fn=) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对输出矩阵自动微分
到此为止我们都是对标量进行自动微分,当我们试图对向量或者矩阵进行梯度反传时,会怎么样呢?
import torch x = torch.tensor([1., 2.]).requires_grad_() y = x * x y.backward() print(x.grad) # 报错:RuntimeError: grad can be implicitly created only for scalar outputs- 1
- 2
- 3
- 4
- 5
- 6
- 7
报错了,只有对标量输出才能隐式地求梯度。即因为只能标量对标量,标量对向量求梯度, x 可以是标量或者向量,但 y 只能是标量;所以只需要先将 y 转变为标量,对分别求导没影响的就是求和。比如下面这样:
import torch x = torch.tensor([1., 2.]).requires_grad_() y = x * x y = y.sum() # 求和,得到标量 y.backward() print(x.grad) # 输出:tensor([2., 4.])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
此时, x = [ x 1 , y 1 ] x=[x_1,y_1] x=[x1,y1], y = [ x 1 2 , x 2 2 ] y=[x_1^2,x_2^2] y=[x12,x22] , y ′ = y . s u m ( ) = x 1 2 + x 2 2 y'=y.sum()=x_1^2+x_2^2 y′=y.sum()=x12+x22 ,很显然,求梯度有:
∂ y ′ ∂ x 1 = 2 x 1 = 2 ∂ y ′ ∂ x 2 = 2 x 2 = 4 \frac{\partial y'}{\partial x_1}=2x_1=2\ \ \ \ \ \ \ \ \ \ \frac{\partial y'}{\partial x_2}=2x_2=4 ∂x1∂y′=2x1=2 ∂x2∂y′=2x2=4
与程序输出相同。为什么必须是标量呢?我们先写出当输出是一个向量 y = [ y 1 , y 2 ] y=[y_1,y_2] y=[y1,y2] 时的雅克比矩阵:
J = [ ∂ y ∂ x 1 , ∂ y ∂ x 2 ] = [ ∂ y 1 ∂ x 1 ∂ y 1 ∂ x 2 ∂ y 2 ∂ x 1 ∂ y 2 ∂ x 2 ] {J}=[\frac{\partial y}{\partial x_1},\frac{\partial y}{\partial x_2}]=[∂y1∂x1∂y1∂x2∂y2∂x1∂y2∂x2]J=[∂x1∂y,∂x2∂y]=[∂x1∂y1∂x1∂y2∂x2∂y1∂x2∂y2]
而我们想要的是 [ ∂ y 1 ∂ x 1 , ∂ y 2 ∂ x 2 ] [\frac{\partial y_1}{\partial x_1},\frac{\partial y_2}{\partial x_2}] [∂x1∂y1,∂x2∂y2] ,从矩阵计算的角度来看,是不是只要对雅克比矩阵左乘个 [ 1 , 1 ] [1,1] [1,1] 就可以得到我们想要的了:
[ ∂ y 1 ∂ x 1 , ∂ y 2 ∂ x 2 ] = [ 1 , 1 ] ⋅ J [\frac{\partial y_1}{\partial x_1},\frac{\partial y_2}{\partial x_2}]=[1,1]\cdot J [∂x1∂y1,∂x2∂y2]=[1,1]⋅J
这就是不使用y.sum()的另一种方式,通过 backward 接口的 grad_tensors 参数(上面介绍过):x = torch.tensor([1., 2.]).requires_grad_() y = x * x y.backward(torch.ones_like(y)) print(x.grad) # 输出:tensor([2., 4.])- 1
- 2
- 3
- 4
- 5
- 6
如果要使用 torch.autograd.grad ,对应的接口形参是 grad_outputs :
x = torch.tensor([1., 2.]).requires_grad_() y = x * x grad_x = torch.autograd.grad(outputs=y, inputs=x, grad_outputs=torch.ones_like(y)) # 或者 # grad_x = torch.autograd.grad(outputs=y.sum(), inputs=x) print(grad_x[0]) # 输出:tensor([2., 4.])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
实际上,grad_tensors 的作用其实可以简单地理解成在求梯度时的权重,因为可能不同值的梯度对结果影响程度不同,所以 Pytorch 弄了个这种接口,而没有固定为全是1。引用自知乎上的一个评论:如果从最后一个节点(总loss)来backward,这种实现(torch.sum(y*w))的意义就具体化为 multiple loss term with difference weights 这种需求了吧。
关于对输出矩阵求微分,更详细的可参考:PyTorch 的 backward 为什么有一个 grad_variables 参数?
几个细节
zero_grad
在写训练脚本时,我们通常在每次 backward 反传之前,都要进行一步
optimizer.zero_gard(),这一步是做什么的呢?实际上就如同名字显示那样,本步的目的就是将目前叶子结点中上一步的梯度 grad 清零,然后再进行反传,计算本 batch 的梯度。那能不能不每次都清零梯度呢?实际上是可以的,这可以作为一种变相增大 batch size 的 trick。如果我们的机器每个 batch 最多只能 64 个样本,那我们设置每步都计算梯度并累计到叶子结点的 grad 属性中,但是每隔一步才进行一次参数更新和梯度清零,这就相当于 batch_size 成了 128。但这也会出现一些问题,比如 BN 怎么办,这在知乎上也有一些问题有讨论过,感兴趣可以查一下。
model.zero_grad()还是optimizer.zero_grad()?
看代码时,有时候会看到
model.zero_grad(),有时又会看到optimizer.zero_grad(),到底有什么区别呢?我们知道模型就是一堆参数按照特定的运算结构组织起来,我们在构建 optimizer 时会把优化器要优化的参数传递给它,比如:
optimizer = Adam(model.parameters(), lr=lr)- 1
常规情况下传入优化器的只有
model.parameters(),但是并不总是如此。有时候,整个模型要优化的不只有模型本身的参数,还可能有一些自定义的 parameters,比如:pref_vec = torch.nn.Parameter(torch.randn(1, 512)) optimizer = Adam([{'params': model.parameters()}, {'params': pref_vec}], lr=lr)- 1
- 2
在这种情况下
model.parameters()与pref_vec是一起更新的,都有 optimizer 这个优化器来更新。指出这一点之后,大家应该就明白
model.zero_grad()和optimizer.zero_grad()的区别了。它们指向的待更新参数(叶子结点)不一定是一样的。一般情况下(优化器待更新参数就是模型参数)二者是等价的,但是如果待更新的参数除了模型的参数之外还有一些自定义的参数,就必须用optimizer.zero_grad()了。detach
detach 会切断当前张量与计算图之间的联系,不会再往后计算梯度。
假设有模型 A 和模型 B,我们需要将 A 的输出作为 B 的输入,但训练时我们只训练模型B,那么可以这样做:
input_B = output_A.detach()- 1
inplace
inplace 操作顾名思义,就是直接在原地改变张量的值,而不是计算后得到一个新的张量并返回。
注意:叶子节点不可执行 in-place 操作,因为反向传播时会访问原来的对象地址。
关于 inplace 操作也有很多坑,经常见到的一个报错是:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: ...- 1
关于 inplace 操作的问题在 PyTorch 的 Autograd 中有详细的讨论。
Ref
-
相关阅读:
Chapter 5 决策树和随机森林实践
ZYNQ7010 PS PL BRAM少量数据通讯测试
Qt开发经验小技巧246-250
python中的继承
java毕业设计InHome阅读平台mybatis+源码+调试部署+系统+数据库+lw
【前端知识】Axios——请求拦截器模板
promise详解
C++变量默认初始化
主机加固如何应对数据世界的绑匪
comsol6.1软件下载+安装教程
- 原文地址:https://blog.csdn.net/weixin_44966641/article/details/126751327
