-
MySQL查询优化之order by 与 group by优化
在MySQL中,支持两种排序方式,分别是FileSort和Index排序。
- Index排序中,索引可以保证数据的有序性,不需要再进行排序,效率更好。
- FileSort排序则一般在内存中进行排序,占用CPU较多。如果待排结果较大,会产生临时文件IO到磁盘进行排序的情况,效率较低。
order by 子句尽量使用index方式排序(即using index),避免使用filesort方式排序(即using filesort)。Index方式效率高,它指MySQL扫描索引本身完成排序,filesort则效率低。
常见优化建议
- SQL中,可以在where子句和order by子句中使用索引,目的是在where子句中避免全表扫描,在order by子句避免使用FileSort排序。当然,某些情况下全表扫描,或者FileSort排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
- 尽量使用Index完成order by排序。如果where和order by后面是相同的列就使用单索引列,如果不同就使用联合索引。
- 无法使用index时,需要对FileSort方式进行调优。
order by满足两种情况,会使用 index 方式排序:
- order by语句使用索引最左前列(最左匹配法则)
- where子句和order by子句条件列组合满足最左匹配法则(where条件使用索引的最左前缀为常量)
下面给出几个实例来说明,如下所示我们创建表并为其创建组合索引(c1,c2,c3)。
CREATE TABLE `testc` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `c1` varchar(100) DEFAULT NULL, `c2` varchar(100) DEFAULT NULL, `c3` varchar(100) DEFAULT NULL, `c4` varchar(100) DEFAULT NULL, `c5` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), KEY `testc_c1_IDX` (`c1`,`c2`,`c3`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
【1】 order by不使用limit,索引失效
explain select * from testc order by c1,c2- 1

可以看到没有用到索引,排序采用的是FileSort。explain select SQL_NO_CACHE * from testc order by c1,c2 limit 1;- 1

需要注意的是,如果你的表数量级很小。比如表数量只有10条,你limit 5,那么MySQL优化器会自行考虑是否使用索引。explain select SQL_NO_CACHE * from testc order by c1,c2 limit 5;- 1

当然,order by不使用limit,索引失效,这句话的应用场景(索引的应用场景)指的是表数据量比较大时,那么order by XXX limit n是一种比较好的优化。
那如果不是
select *呢?explain select SQL_NO_CACHE c1,c2 from testc order by c1,c2 ;- 1

可以看到使用到了索引,数据均在二级索引上,不需要回表(覆盖索引)。另外,这里也说明了尽量不要select *。【2】 where与order by满足最左匹配法则
这里要说明一下,所有的排序都是先过滤数据。如果存在where且where能过过滤大部分数据,那么可能只基于where条件字段进行索引,order by字段索引并没有使用。在平时是实战中可以观察不同过滤条件下,ken_len大小进行验证。
# c1 c2满足最左匹配法则 explain select * from testc where c1='a1' order by c2 # 与上面等价 explain select * from testc where c1='a1' order by c2,c3- 1
- 2
- 3
- 4
- 5

key_len标明查找用到了索引c1,Extra中是Using index condition没有同时出现using where ,表明 c2 索引用来读取数据而非执行查找动作。key_len=403=4(utf8mb4)*100(长度)+1(default null)+2(变长字段)。MySQL Innodb下的B+树本身就是多路平衡树,那么索引换句话就是
排好序的快速查找数据结构。如果order by用到了索引且排序和索引次序一样,那么无疑效果是最好的。那如果是下面这条SQL呢? 按照规则来讲,其是用不到索引的。
explain select * from testc where c2='a1' order by c1 limit 1;- 1
我们查看执行计划,明显用到了索引。可以这样理解:MySQL优化器在发现你有limit时,就会考虑使用索引。比如这里首先根据c1排序,然后进行where过滤,最后取一条。
MySQL优化器认为这样更好,当然如果你没有limit 1。比如下面:explain select * from testc where c2='a1' order by c1- 1

很显然没有使用到索引,MySQL优化器会采用FileSort方式进行排序。【3】 中间断裂
如下所示,缺少了c2,order by不满足最左匹配法则。
explain select * from testc where c1='a1' order by c3- 1
可以看到Extra中
Using index condition; Using filesort说明虽然where可以用到索引(单独c1满足最左匹配),但是排序不满足,故而出现了filesort。
Using index condition; 表示索引下推,我们后面展开学习。
【4】 大哥不在
如下c1不在,那么很显然无论查找还是排序都用不到索引。
explain select * from testc where c2='a2' order by c3- 1
这里Extra是
Using where; Using filesort,说明通过where子句过滤结果,然后对结果进行文件排序。
【5】 范围失效
如下所示,中间c2是个范围搜索,那么其后索引将失效也就是order by c3无法与where连接满足最左匹配法则。
explain select * from testc where c1='a1' and c2 > 'a2' order by c3- 1
如下图所示,这里
type = range,ken_len表示用到了 c1,c2索引。Extra是Using index condition; Using filesort表示查询用到了索引但是无法利用索引完成的排序操作。
这种情况如何优化呢?
order by c2,c3!这样就可以保证索引排序而不需要filesort。explain select * from agriculture.testc where c1='a1' and c2 > 'a2' order by c2,c3- 1
- 2

【6】 order by规则不一致,索引失效
① order by 顺序错误,索引失效
如下所示,order by的次序没有与索引次序保持一致。这里Extra为
Using index condition; Using filesort。explain select * from testc where c1='a1' order by c3,c2- 1

② order by 方向错误,索引失效
explain select * from testc order by c1 asc,c2 asc limit 1;- 1

explain select * from testc order by c1 desc,c2 desc limit 1;- 1

explain select * from testc order by c1 asc,c2 desc limit 1- 1

可以看到前两者无论ASC还是desc 方向都是一致的,显然都使用到了索引。而第三者方向是相反的,没有使用到索引。
【7】 覆盖索引
前面几个都是
select *,这里查找索引列。没有where,order by满足全值匹配,select查询的数据是索引列。explain select c1 from testc order by c1, c2,c3- 1
这里Extra中只有
Using index;
没有where,order by 大哥丢失,select查询的数据是索引列。
explain select c1 from testc order by c2,c3- 1
这里Extra中是
Using index; Using filesort。
这里Extra信息为
Using where; Using index; Using filesort。explain select c1 from testc where c1='a1' order by c3,c2- 1

【8】 FileSort一定比index性能低吗?
我们基于student表进行分析说明,该表有50W数据。
CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `stuno` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, `age` int(3) DEFAULT NULL, `classId` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=500001 DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如下我们查询
age = 30 AND stuno <101000的同学并且按照name进行排序。EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ; [SQL]SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ; 受影响的行: 0 时间: 0.317s- 1
- 2
- 3
- 4
- 5

方案一: 为了去掉filesort我们可以把索引建成(age,NAME)CREATE INDEX idx_age_name ON student(age,NAME); EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ; [SQL]SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ; 受影响的行: 0 时间: 2.949s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

key_len=5说明只使用到了age索引字段,NAME没有涉及到。这里确实是优化掉了FileSort,那么效率一定是最高的吗?方案二:尽量让where的过滤条件和排序使用上索引,我们创建索引(age,stuno,NAME)
CREATE INDEX idx_age_stuno_name ON student(age,stuno,NAME); EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;- 1
- 2
- 3
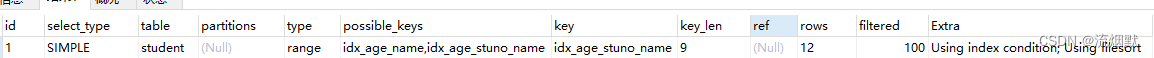
我们发现using filesort依然存在,所以name没有使用到索引,而且type还是range。光看执行计划确实不太好,这里stuno是一个范围过滤,所以索引后面的字段不会再使用索引了。我们查看其SQL运行结果:
[SQL]SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ; 受影响的行: 0 时间: 0.003s- 1
- 2
- 3
结果是竟然有FileSort的SQL运行速度,超过了已经优化掉FileSort的SQL,而且快了很多。这是因为所有的排序都是在条件过滤之后才执行的。所以如果条件过滤掉大部分数据的话,剩下几百几千条数据进行排序其实并不是很消耗性能,即时索引优化了排序,但实际提升性能很有限。
相对的stuno<101000这个条件,如果没有用到索引的话,要对几万条的数据进行扫描,这是非常消耗性能的,所以索引放在这个字段上性价比最高,是最优选择。
这就得出如下结论
- 两个索引同时存在,MySQL自动选择最优的方案。但是,随着数据量的变化,选择的索引也会随之变化的。
- 当【范围条件】和【group by | order by】的字段出现二选一时,优先观察条件字段的过滤数量。如果过滤的数据足够多,而需要排序的 数据并不多时,优先把索引放在范围字段上,反之亦然。
我们删掉索引idx_age_stuno_name ,只给(age,stuno)创建索引,再次执行上面SQL。
DROP INDEX idx_age_stuno_name ON student; CREATE INDEX idx_age_stuno ON student(age,stuno); EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;- 1
- 2
- 3
- 4
- 5
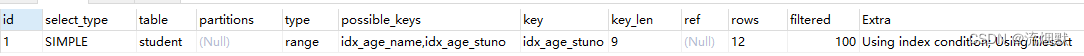
查看SQL运行结果,可以发现与前面效果是一致的。[SQL]SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ; 受影响的行: 0 时间: 0.004s- 1
- 2
- 3
- 4
【9】 filesort的两种算法
① 概念介绍
filesort有两种机制:双路排序和单路排序。双路排序简单来讲就是两次扫描磁盘,最终得到数据。单路排序则是只需要读取一次,也就是一次磁盘IO。
双路排序
MySQL4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据。读取行指针和order by列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出(可以理解为从磁盘读取排序字段,在buffer进行排序,然后再从磁盘读取其他字段)。
取一批数据要进行两次磁盘IO,这是很耗时的。故而在MySQL4.1之后,出现了第二种改进的算法,也就是单路排序。
单路排序
从磁盘读取查询需要的所有列,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出。它的效率更快一点,避免了第二次读取数据,并且把随机IO变成了顺序IO。但是其会使用更多的空间,因为其缓存了数据在内存中。
单路的问题
在sort_buffer中,单路比多路要占用很多空间。因为单路是把所有字段都取出,可能取出的数据大小超过了
sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小…从而多次IO(可能比双路更多)。在恶劣情况下,单路本来想省一次IO操作,反而导致了大量的IO操作,反而得不偿失。
② 优化策略
可以尝试增大
sort_buffer_size参数的设置或者max_length_for_sort_data参数的设置。sort_buffer_size不管哪种算法,提高
sort_buffer_size参数都会提高效率,要根据系统的能力去提高,因为这个参数是针对每个进程(connection)的1M-8M之间调整。MySQL5.7,InnoDB存储引擎默认值是1048576字节,1MB。show VARIABLES like '%sort_buffer_size%' innodb_sort_buffer_size 1048576 myisam_sort_buffer_size 8388608 sort_buffer_size 262144- 1
- 2
- 3
- 4
max_length_for_sort_data提高这个参数,会增加用改进算法的概率。如果需要返回的列的总长度(
即查询的字段长度与max_length_for_sort_data进行对比)大于max_leng_for_sort_data,使用双路算法,否则使用单路算法。建议在1024-8192之间调整。show VARIABLES like '%max_length_for_sort_data%' # 默认1024字节- 1
但是如果设的太高,数据总容量超出
sort_buffer_size的概率就增大,明显症状是高的磁盘IO活动和低的处理器使用率。order by时
select *是一个大忌,应该是查询需要的字段当query的字段大小总和小于
max_length_for_sort_data,而且排序字段不是text|blob类型时,会用改进后的算法–单路排序,否则使用双路排序。两种算法的数据都有可能超出
sort_buffer的容量,超出之后会创建tmp文件进行合并排序导致多次IO。尤其对于单路排序来说风险更大,所以需要适当调整sort_buffer的容量。【10】 group by优化
前面提到的规则针对group by均适用,group by 实质是先排序后分组,遵照索引建的最佳左前缀。
这里给出一些注意事项- group by使用索引的原则几乎跟order by一致,group by即使没有过滤条件用到索引,也可以直接使用索引。
- group by先排序后分组,遵照索引建的最佳左前缀法则。
- 当无法使用索引列,增大max_length_for_sort_data和sort_buffer参数的值。
- where效率高于having,能写在where限定的条件就不要写在having中了。
- 减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。order by / group by / distinct 这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 包含了order by / group by / distinct 这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
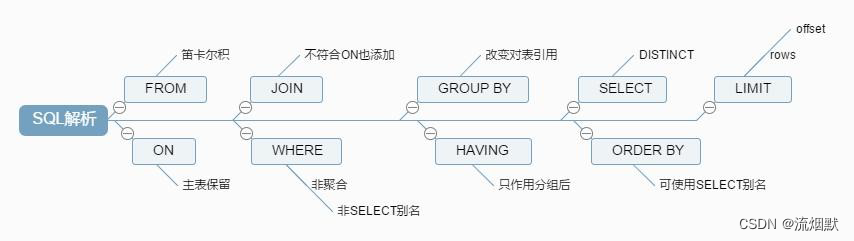
最后我们再回顾下SQL执行顺序:
【11】优化分页查询
一般分页查询时,通过创建覆盖索引能够比较好的提高性能。一个常见又非常头疼的问题就是limit 2000000,10 。此时需要MySQL排序前2000010记录,仅仅返回2000000-2000010的记录,其他记录丢弃,查询排序的代价非常大。
explain select * from student limit 2000000,10;- 1

优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
expalin select * from student t, (select id from student order by id limit 2000000,10) a where t.id =a.id;- 1
- 2
- 3
优化思路二
该方案适用于主键自增的表,可以把limit查询转换成某个位置的查询。
explain select * from student where id > 2000000 limit 10;- 1
- 2
-
相关阅读:
【DesignMode】单例模式(singleton pattern)
Impala 安装
final修饰的变量必须初始化吗?
【HarmonyOS】鸿蒙系统中应用权限等级介绍、定义、申请授权讲解
一文读懂Persistence One- 如何将Restaking带入Cosmos
1375. 二进制字符串前缀一致的次数-前序遍历法
【消息中心】kafka消费失败重试10次的问题
【游戏客户端】制作节奏大师Like音游(下)
Windows-vscode安装与简单配置
Linux——Linux驱动之iMX6ULL硬件平台下使用MfgTool工具进行系统烧写的原理及步骤总结(uboot、kernel、dtb、rootfs)
- 原文地址:https://blog.csdn.net/J080624/article/details/126750827