微服务 详解
微服务架构:
CREATE DATABASE lagou CHARACTER SET utf8;
USE lagou;
CREATE TABLE products(
id INT PRIMARY KEY AUTO_INCREMENT ,
NAME VARCHAR ( 50 ) ,
price DOUBLE ,
flag VARCHAR ( 2 ) ,
goods_desc VARCHAR ( 100 ) ,
images VARCHAR ( 400 ) ,
goods_stock INT ,
goods_type VARCHAR ( 20 )
) ;
INSERT INTO products ( id, NAME, price, flag, goods_desc, images, goods_stock, goods_type)
VALUE ( 1 , 'aa' , 1.1 , 1 , 1 , 1 , 1 , 1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
< packaging> packaging > < parent> < groupId> groupId > < artifactId> artifactId > < version> version > parent > < dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < scope> scope > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > < scope> scope > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < optional> optional > dependency > dependencies > < build> < plugins> < plugin> < groupId> groupId > < artifactId> artifactId > < configuration> < source> source > < target> target > < encoding> encoding > configuration > plugin > < plugin> < groupId> groupId > < artifactId> artifactId > < executions> < execution> < goals> < goal> goal > goals > execution > executions > plugin > plugins > build >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 mybatis -plus:< dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < scope> scope > dependency > dependencies >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 pojo 包
package com. lagou. common. pojo ;
import lombok. Data ;
import javax. persistence. Id ;
import javax. persistence. Table ;
@Data
@Table ( name = "products" )
public class Products {
@Id
private long id;
private String name;
private double price;
private String flag;
private String goodsDesc;
private String images;
private long goodsStock;
private String goodsType;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 < dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > dependencies >
server :
port : 9000
Spring :
application :
name : lagou- service- product
datasource :
driver-class-name : com.mysql.jdbc.Driver
url : jdbc: mysql: //localhost: 3306/lagou? useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
username : root
password : 123456
package com. lagou. product ;
import org. mybatis. spring. annotation. MapperScan ;
import org. springframework. boot. SpringApplication ;
import org. springframework. boot. autoconfigure. SpringBootApplication ;
@SpringBootApplication
@MapperScan ( "com.lagou.product" )
public class ProductApplication {
public static void main ( String [ ] args) {
SpringApplication . run ( ProductApplication . class , args) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com. lagou. product. mapper ;
import com. baomidou. mybatisplus. core. mapper. BaseMapper ;
import com. baomidou. mybatisplus. core. mapper. Mapper ;
import com. lagou. common. pojo. Products ;
public interface ProductMapper extends BaseMapper < Products > {
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com. lagou. product. service ;
import com. lagou. common. pojo. Products ;
public interface ProductService {
public Products queryById ( Integer id) ;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com. lagou. product. service. impl ;
import com. lagou. common. pojo. Products ;
import com. lagou. product. mapper. ProductMapper ;
import com. lagou. product. service. ProductService ;
import org. springframework. beans. factory. annotation. Autowired ;
import org. springframework. stereotype. Service ;
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductMapper productMapper;
@Override
public Products queryById ( Integer id) {
return productMapper. selectById ( id) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com. lagou. product. controller ;
import com. lagou. common. pojo. Products ;
import com. lagou. product. service. ProductService ;
import org. springframework. beans. factory. annotation. Autowired ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. PathVariable ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
@RestController
@RequestMapping ( "/product" )
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping ( "/query/{id}" )
public Products queryById ( @PathVariable Integer id) {
return productService. queryById ( id) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 < dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > dependencies >
server :
port : 9100
Spring :
application :
name : lagou- service- page
datasource :
driver-class-name : com.mysql.jdbc.Driver
url : jdbc: mysql: //localhost: 3306/lagou? useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
username : root
password : 123456
package com. lagou. page ;
import org. springframework. boot. SpringApplication ;
import org. springframework. boot. autoconfigure. SpringBootApplication ;
import org. springframework. context. annotation. Bean ;
import org. springframework. web. client. RestTemplate ;
@SpringBootApplication
public class PageApplication {
public static void main ( String [ ] args) {
SpringApplication . run ( PageApplication . class , args) ;
}
@Bean
public RestTemplate restTemplate ( ) {
return new RestTemplate ( ) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com. lagou. page. controller ;
import com. lagou. common. pojo. Products ;
import org. springframework. beans. factory. annotation. Autowired ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. PathVariable ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
import org. springframework. web. client. RestTemplate ;
@RestController
@RequestMapping ( "/page" )
public class PageController {
@Autowired
private RestTemplate restTemplate;
@GetMapping ( "/getProduct/{id}" )
public Products getProduct ( @PathVariable Integer id) {
String url = "http://localhost:9000/product/query/" ;
Products forObject = restTemplate. getForObject ( url + id, Products . class ) ;
return forObject;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
< dependencyManagement> < dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > < type> type > < scope> scope > dependency > dependencies > dependencyManagement >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
< dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > dependency > dependencies >
< dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
server :
port : 9200
spring :
application :
name : lagou- cloud- eureka
eureka :
instance :
hostname : localhost
client :
service-url :
defaultZone : http: //localhost: 9200/eureka/
register-with-eureka : false
fetch-registry : false
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package com. lagou. eureka ;
import org. springframework. boot. SpringApplication ;
import org. springframework. boot. autoconfigure. SpringBootApplication ;
import org. springframework. cloud. netflix. eureka. server. EnableEurekaServer ;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main ( String [ ] args) {
SpringApplication . run ( EurekaApplication . class , args) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
eureka :
instance :
prefer-ip-address : true
instance-id : ${ spring.cloud.client.ip- address} : ${ spring.application.name} : ${ server.port} : @project.version@
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
< dependency> < groupId> groupId > < artifactId> artifactId > dependency >
eureka :
client :
serviceUrl :
defaultZone : http: //localhost: 9200/eureka/
instance :
prefer-ip-address : true
instance-id : ${ spring.cloud.client.ip- address} : ${ spring.application.name} : ${ server.port} : @project.version@
package com. lagou. product ;
import org. mybatis. spring. annotation. MapperScan ;
import org. springframework. boot. SpringApplication ;
import org. springframework. boot. autoconfigure. SpringBootApplication ;
import org. springframework. cloud. netflix. eureka. EnableEurekaClient ;
@SpringBootApplication
@MapperScan ( "com.lagou.product.mapper" )
@EnableDiscoveryClient
public class ProductApplication {
public static void main ( String [ ] args) {
SpringApplication . run ( ProductApplication . class , args) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 127.0 .0.1 LagouCloudEurekaServerA
127.0 .0.1 LagouCloudEurekaServerB
defaultZone : http: //LagouCloudEurekaServerB: 9201/eureka/
defaultZone : http: //LagouCloudEurekaServerA: 9200/eureka/
defaultZone : http: //LagouCloudEurekaServerA: 9200/eureka/, http: //LagouCloudEurekaServerB: 9201/eureka/
package com. lagou. page. controller ;
import com. lagou. common. pojo. Products ;
import org. springframework. beans. factory. annotation. Autowired ;
import org. springframework. cloud. client. ServiceInstance ;
import org. springframework. cloud. client. discovery. DiscoveryClient ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. PathVariable ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
import org. springframework. web. client. RestTemplate ;
import java. util. List ;
@RestController
@RequestMapping ( "/page" )
public class PageController {
@Autowired
private RestTemplate restTemplate;
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping ( "/getProduct/{id}" )
public Products getProduct ( @PathVariable Integer id) {
List < ServiceInstance > = discoveryClient. getInstances ( "lagou-service-product" ) ;
ServiceInstance serviceInstance = instances. get ( 0 ) ;
String host = serviceInstance. getHost ( ) ;
System . out. println ( host) ;
int port = serviceInstance. getPort ( ) ;
System . out. println ( port) ;
String url = "http://" + host+ ":" + port+ "/product/query/" + id;
Products forObject = restTemplate. getForObject ( url, Products . class ) ;
return forObject;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64
List < ServiceInstance > = discoveryClient. getInstances ( "lagou-cloud-eureka" ) ;
System . out. println ( instancess. size ( ) ) ;
instance :
prefer-ip-address : true
instance-id : ${ spring.cloud.client.ip- address} : ${ spring.application.name} : ${ server.port} : @project.version@
metadata-map :
ip : 192.168.200.128
port : 10000
user : YuanJing
pwd : 123456
ServiceInstance serviceInstance = instances. get ( 0 ) ;
Map < String , String > = serviceInstance. getMetadata ( ) ;
Set < String > = metadata. keySet ( ) ;
Object [ ] objects = strings. toArray ( ) ;
Collection < String > = metadata. values ( ) ;
Object [ ] objects1 = values. toArray ( ) ;
for ( int a = 0 ; a< strings. size ( ) ; a++ ) {
System . out. println ( objects[ a] + ":" + objects1[ a] ) ;
}
eureka :
instance :
lease-renewal-interval-in-seconds : 30
lease-expiration-duration-in-seconds : 90
eureka :
client :
registry-fetch-interval-seconds : 30
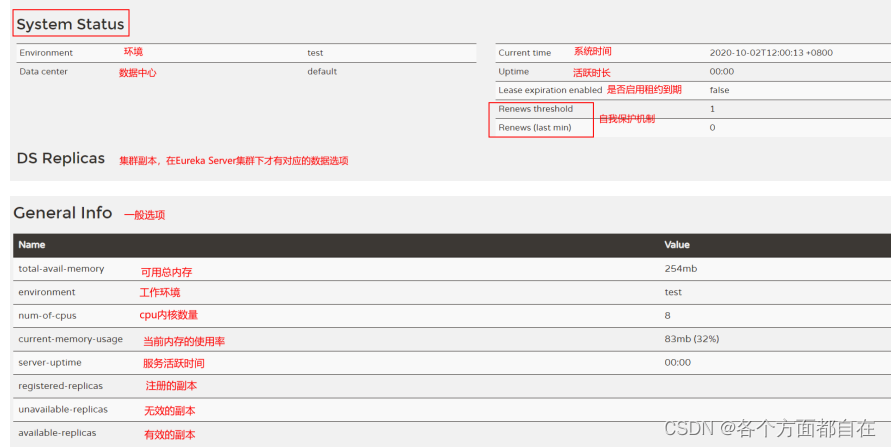
eureka :
server :
enable-self-preservation : false
package com. lagou. product. controller ;
import com. netflix. discovery. converters. Auto ;
import org. springframework. beans. factory. annotation. Autowired ;
import org. springframework. beans. factory. annotation. Value ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
@RestController
@RequestMapping ( "/service" )
public class ServiceInfoController {
@Value ( "${server.port}" )
private String port;
@GetMapping ( "port" )
public String getPort ( ) {
return port;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
@Bean
@LoadBalanced
public RestTemplate restTemplate ( ) {
return new RestTemplate ( ) ;
}
@GetMapping ( "loadProductServicePort" )
public String getProductServerPort ( ) {
List < ServiceInstance > = discoveryClient. getInstances ( "lagou-service-product" ) ;
ServiceInstance serviceInstance = instances. get ( 0 ) ;
String host = serviceInstance. getHost ( ) ;
int port = serviceInstance. getPort ( ) ;
String url = "http://" + host+ ":" + port+ "/service/port/" ;
String forObject = restTemplate. getForObject ( url, String . class ) ;
return forObject;
}
@GetMapping ( "loadProductServicePort" )
public String getProductServerPort ( ) {
String url = "http://lagou-service-product/service/port/" ;
String forObject = restTemplate. getForObject ( url, String . class ) ;
return forObject;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
package com. netflix. loadbalancer ;
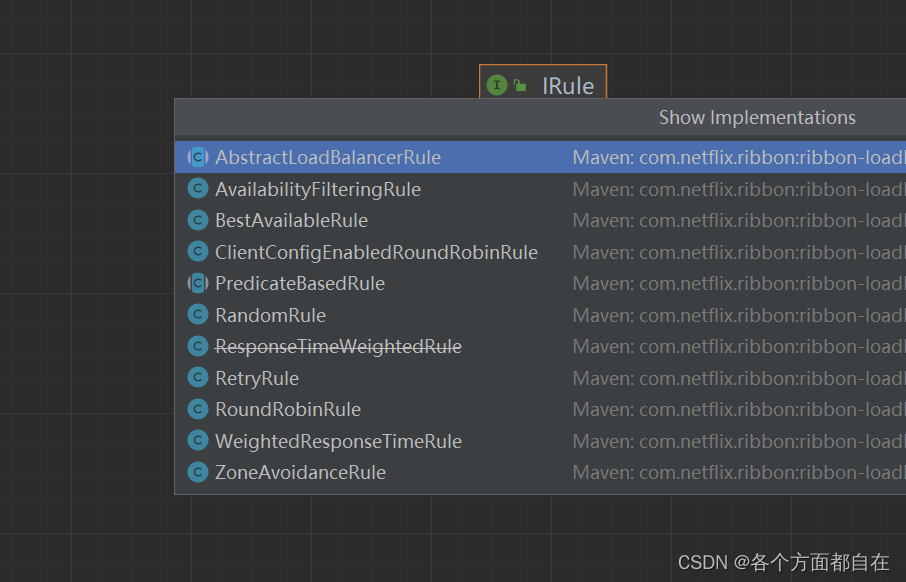
public interface IRule {
Server choose ( Object var1) ;
void setLoadBalancer ( ILoadBalancer var1) ;
ILoadBalancer getLoadBalancer ( ) ;
}
lagou-service-product :
ribbon :
NFLoadBalancerRuleClassName : com.netflix.loadbalancer.RandomRule
lagou-service-product :
ribbon :
NFLoadBalancerRuleClassName : com.netflix.loadbalancer.RoundRobinRule
@Configuration
@ConditionalOnClass ( { RestTemplate . class } )
@ConditionalOnBean ( { LoadBalancerClient . class } )
@EnableConfigurationProperties ( { LoadBalancerRetryProperties . class } )
public class LoadBalancerAutoConfiguration {
@LoadBalanced
@Autowired (
required = false
)
private List < RestTemplate > = Collections . emptyList ( ) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer ( final LoadBalancerInterceptor
loadBalancerInterceptor) {
return ( restTemplate) -> {
List < ClientHttpRequestInterceptor > = new
ArrayList ( restTemplate. getInterceptors ( ) ) ;
list. add ( loadBalancerInterceptor) ;
restTemplate. setInterceptors ( list) ;
} ;
}
public ClientHttpResponse intercept ( final HttpRequest request, final byte [ ] body, final ClientHttpRequestExecution execution) throws IOException {
URI originalUri = request. getURI ( ) ;
String serviceName = originalUri. getHost ( ) ;
Assert . state ( serviceName != null , "Request URI does not contain a valid hostname: " +
originalUri) ;
return ( ClientHttpResponse ) this . loadBalancer. execute (
serviceName, this . requestFactory. createRequest ( request, body, execution) ) ;
}
public < T > T execute ( String serviceId, LoadBalancerRequest < T > ) throws IOException {
return this . execute ( serviceId, ( LoadBalancerRequest ) request, ( Object ) null ) ;
}
public < T > T execute ( String serviceId, LoadBalancerRequest < T > , Object hint) throws
IOException {
ILoadBalancer loadBalancer = this . getLoadBalancer ( serviceId) ;
Server server = this . getServer ( loadBalancer, hint) ;
if ( server == null ) {
throw new IllegalStateException ( "No instances available for " + serviceId) ;
} else {
RibbonLoadBalancerClient. RibbonServer ribbonServer = new
RibbonLoadBalancerClient. RibbonServer ( serviceId, server, this . isSecure ( server, serviceId) , this . serverIntrospector ( serviceId) . getMetadata ( server) ) ;
return this . execute ( serviceId, ( ServiceInstance ) ribbonServer,
( LoadBalancerRequest ) request) ;
}
}
< dependency> < groupId> groupId > < artifactId> artifactId > dependency >
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
public class PageApplication {
@SpringCloudApplication
public class PageApplication {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @GetMapping ( "port" )
public String getPort ( ) {
try {
Thread . sleep ( 5000 ) ;
} catch ( InterruptedException e) {
e. printStackTrace ( ) ;
}
return port;
}
@HystrixCommand (
threadPoolKey = "getProductServerPort2" ,
threadPoolProperties = {
@HystrixProperty ( name= "coreSize" , value = "1" ) ,
@HystrixProperty ( name= "maxQueueSize" , value = "20" ) ,
} ,
commandProperties= {
@HystrixProperty ( name= "execution.isolation.thread.timeoutInMilliseconds" , value = "2000" )
}
)
@GetMapping ( "loadProductServicePort2" )
public String getProductServerPort2 ( ) {
String url = "http://lagou-service-product/service/port/" ;
System . out. println ( 1 ) ;
String forObject = restTemplate. getForObject ( url, String . class ) ;
System . out. println ( forObject) ;
return forObject;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 "message" : "getProductServerPort2 timed-out and fallback failed." ,
@HystrixCommand (
commandProperties= {
@HystrixProperty ( name= "execution.isolation.thread.timeoutInMilliseconds" , value = "2000" )
} ,
fallbackMethod = "fallBack"
)
@GetMapping ( "loadProductServicePort3" )
public String getProductServerPort3 ( ) {
String url = "http://lagou-service-product/service/port/" ;
System . out. println ( 1 ) ;
String forObject = restTemplate. getForObject ( url, String . class ) ;
System . out. println ( 5 ) ;
System . out. println ( forObject) ;
return forObject;
}
public String fallBack ( ) {
return "-1" ;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @HystrixProperty ( name= "execution.isolation.thread.timeoutInMilliseconds" , value = "2000" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 舱壁模式 )
threadPoolKey = "getProductServerPort2" ,
commandProperties= {
@HystrixProperty ( name= "execution.isolation.thread.timeoutInMilliseconds" , value = "2000" ) ,
@HystrixProperty ( name = "metrics.rollingStats.timeInMilliseconds" , value = "8000" ) ,
@HystrixProperty ( name = "circuitBreaker.requestVolumeThreshold" , value = "2" ) ,
@HystrixProperty ( name = "circuitBreaker.errorThresholdPercentage" , value = "50" ) ,
@HystrixProperty ( name = "circuitBreaker.sleepWindowInMilliseconds" , value = "3000" )
} ,
"hystrix" : {
"status" : "UP"
}
"hystrix" : {
"status" : "CIRCUIT_OPEN" ,
"details" : {
"openCircuitBreakers" : [
"PageController::getProductServerPort3"
]
}
}
"hystrix" : {
"status" : "UP"
}
hystrix :
command :
default :
circuitBreaker :
forceOpen : false
errorThresholdPercentage : 50
sleepWindowInMilliseconds : 3000
requestVolumeThreshold : 2
execution :
isolation :
thread :
timeoutInMilliseconds : 2000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
management :
endpoints :
web :
exposure :
include : "*"
endpoint :
health :
show-details : always
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 {
"timestamp" : "2022-09-04T03:10:43.083+0000" ,
"status" : 405 ,
"error" : "Method Not Allowed" ,
"message" : "Request method 'POST' not supported" ,
"trace" : "org.springframework.web.HttpRequestMethodNotSupportedException: Request method 'POST' not supported\ r\ n\ tat org.springframewo
hystrix :
threadpool :
default :
coreSize : 10
maxQueueSize : 1000
queueSizeRejectionThreshold : 800
hystrix :
threadpool :
default :
coreSize : 10
maxQueueSize : 1500
queueSizeRejectionThreshold : 1000
@GetMapping ( "loadProductServicePort3" )
public String getProductServerPort3 ( ) {
List < String > = discoveryClient. getServices ( ) ;
System . out. println ( services) ;
String url = "http://lagou-service-product/service/port/" ;
System . out. println ( 1 ) ;
String forObject = restTemplate. getForObject ( url, String . class ) ;
System . out. println ( 5 ) ;
System . out. println ( forObject) ;
return forObject;
}
< dependency> < groupId> groupId > < artifactId> artifactId > dependency >
@SpringCloudApplication
@EnableFeignClients
public class PageApplication {
package com. lagou. page. feign ;
import com. lagou. common. pojo. Products ;
import org. springframework. cloud. openfeign. FeignClient ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. PathVariable ;
@FeignClient ( name= "lagou-service-product" )
public interface ProductFeign {
@GetMapping ( "/product/query/{id}" )
public Products queryById ( @PathVariable Integer id) ;
@GetMapping ( "/service/port" )
public String getPort ( ) ;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 那么在进行参数绑定的时,可以使用@PathVariable、@RequestParam、@RequestHeader等
@Autowired
private ProductFeign productFeign;
@GetMapping ( "loadProductServicePort3" )
public String getProductServerPort3 ( ) {
String port = productFeign. getPort ( ) ;
return port;
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
lagou-service-product :
ribbon :
ConnectTimeout : 2000
ReadTimeout : 5000
OkToRetryOnAllOperations : true
MaxAutoRetries : 0
MaxAutoRetriesNextServer : 0
NFLoadBalancerRuleClassName : com.netflix.loadbalancer.RoundRobinRule
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
feign :
hystrix :
enabled : true
package com. lagou. page. feign ;
import com. lagou. common. pojo. Products ;
import org. springframework. stereotype. Component ;
@Component
public class ProductFeignFallBack implements ProductFeign {
@Override
public Products queryById ( Integer id) {
return null ;
}
@Override
public String getPort ( ) {
return "-1" ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @FeignClient ( name= "lagou-service-product" , fallback = ProductFeignFallBack . class )
public interface ProductFeign {
feign :
hystrix :
enabled : true
compression :
request :
enabled : true
mime-types : text/html, application/xml, application/json
min-request-size : 2048
response :
enabled : true
< parent> < groupId> groupId > < artifactId> artifactId > < version> version > < relativePath/> parent > < dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < scope> scope > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > < scope> scope > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < optional> optional > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > dependencies > < dependencyManagement> < dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > < type> type > < scope> scope > dependency > dependencies > dependencyManagement > < build> < plugins> < plugin> < groupId> groupId > < artifactId> artifactId > < configuration> < source> source > < target> target > < encoding> encoding > configuration > plugin > < plugin> < groupId> groupId > < artifactId> artifactId > plugin > plugins > build >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 package com. lagou. gateway ;
import org. springframework. boot. SpringApplication ;
import org. springframework. boot. autoconfigure. SpringBootApplication ;
import org. springframework. cloud. client. discovery. EnableDiscoveryClient ;
@SpringBootApplication
@EnableDiscoveryClient
public class GateWayServerApplication {
public static void main ( String [ ] args) {
SpringApplication . run ( GateWayServerApplication . class , args) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 server :
port : 9300
eureka :
client :
serviceUrl :
defaultZone : http: //LagouCloudEurekaServerA: 9200/eureka, http: //LagouCloudEurekaServerB: 9201/eureka
instance :
prefer-ip-address : true
instance-id : ${ spring.cloud.client.ip- address} : ${ spring.application.name} : ${ server.port} : @project.version@
spring :
application :
name : lagou- cloud- gateway
cloud :
gateway :
routes :
- id : service- page- router
uri : http: //127.0.0.1: 9100
predicates :
- Path=/page/**
- id : service- product- router
uri : http: //127.0.0.1: 9000
predicates :
- Path=/product/**
filters :
- StripPrefix=1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 实现了各种路由匹配规则(通过 Header、请求参数等作为条件)匹配到对应的路由
spring :
cloud :
gateway :
routes :
- id : after_route
uri : https: //example.org
predicates :
- After=2017- 01- 20T17: 42: 47.789- 07: 00[ America/Denver]
spring :
cloud :
gateway :
routes :
- id : before_route
uri : https: //example.org
predicates :
- Before=2017- 01- 20T17: 42: 47.789- 07: 00[ America/Denver]
spring :
cloud :
gateway :
routes :
- id : between_route
uri : https: //example.org
predicates :
- Between=2017- 01- 20T17: 42: 47.789- 07: 00[ America/Denver] , 2017- 01- 21T17: 42: 47.789- 07: 00[ America/Denver]
spring :
cloud :
gateway :
routes :
- id : cookie_route
uri : https: //example.org
predicates :
- Cookie=chocolate, ch.p
指定Header,且可以操作正则匹配指定值:
spring :
cloud :
gateway :
routes :
- id : header_route
uri : https: //example.org
predicates :
- Header=X- Request- Id, \d+
spring :
cloud :
gateway :
routes :
- id : host_route
uri : https: //example.org
predicates :
- Host=**.somehost.org , **.anotherhost.org
spring :
cloud :
gateway :
routes :
- id : method_route
uri : https: //example.org
predicates :
- Method=GET, POST
spring :
cloud :
gateway :
routes :
- id : path_route
uri : https: //example.org
predicates :
- Path=/red/{ segment} , /blue/{ segment}
spring :
cloud :
gateway :
routes :
- id : query_route
uri : https: //example.org
predicates :
- Query=green
spring :
cloud :
gateway :
routes :
- id : query_route
uri : https: //example.org
predicates :
- Query=red, gree.
spring :
cloud :
gateway :
routes :
- id : remoteaddr_route
uri : https: //example.org
predicates :
- RemoteAddr=192.168.1.1/24
spring :
application :
name : lagou- cloud- gateway
cloud :
gateway :
routes :
- id : servicrrr
uri : lb: //lagou- service- page
predicates :
- Path=/page/**
- id : serviceee
uri : lb: //lagou- service- product
predicates :
- Path=/product/** ,
filters :
- StripPrefix=1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
predicates :
- Path=/product/**
filters :
- StripPrefix=1
filters :
- StripPrefix=1
predicates :
- Path=/product/**
package com. lagou. gateway. filter ;
import org. springframework. boot. web. servlet. filter. OrderedFilter ;
import org. springframework. cloud. gateway. filter. GatewayFilter ;
import org. springframework. cloud. gateway. filter. GatewayFilterChain ;
import org. springframework. cloud. gateway. filter. GlobalFilter ;
import org. springframework. core. Ordered ;
import org. springframework. core. io. buffer. DataBuffer ;
import org. springframework. http. HttpStatus ;
import org. springframework. http. server. reactive. ServerHttpRequest ;
import org. springframework. http. server. reactive. ServerHttpResponse ;
import org. springframework. stereotype. Component ;
import org. springframework. web. server. ServerWebExchange ;
import reactor. core. publisher. Mono ;
import java. net. InetSocketAddress ;
import java. util. ArrayList ;
import java. util. List ;
@Component
public class BlackListFilter implements GlobalFilter , Ordered {
private static List < String > = new ArrayList < > ( ) ;
static {
blackList. add ( "127.0.0.1" ) ;
}
@Override
public Mono < Void > filter ( ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange. getRequest ( ) ;
ServerHttpResponse response = exchange. getResponse ( ) ;
String hostString = request. getRemoteAddress ( ) . getHostString ( ) ;
if ( blackList. contains ( hostString) ) {
response. setStatusCode ( HttpStatus . UNAUTHORIZED) ;
String data = "request be denied" ;
DataBuffer wrap = response. bufferFactory ( ) . wrap ( data. getBytes ( ) ) ;
return response. writeWith ( Mono . just ( wrap) ) ;
}
return chain. filter ( exchange) ;
}
@Override
public int getOrder ( ) {
return 0 ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84
upstream gateway {
server 127.0 .0.1:9002;
server 127.0 .0.1:9003;
}
location / {
proxy_pass http://gateway;
}
mysal :
user : jetwu
person :
name : hahaha
< dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > dependency > dependencies >
package com. lagou. config ;
import org. springframework. boot. SpringApplication ;
import org. springframework. boot. autoconfigure. SpringBootApplication ;
import org. springframework. cloud. client. discovery. EnableDiscoveryClient ;
import org. springframework. cloud. config. server. EnableConfigServer ;
@SpringBootApplication
@EnableDiscoveryClient
@EnableConfigServer
public class ConfigServerApplication {
public static void main ( String [ ] args) {
SpringApplication . run ( ConfigServerApplication . class , args) ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 server :
port : 9400
eureka :
client :
service-url :
defaultZone : http: //LagouCloudEurekaServerA: 9200/eureka, http: //LagouCloudEurekaServerB: 9201/eureka
instance :
prefer-ip-address : true
instance-id : ${ spring.cloud.client.ip- address} : ${ spring.application.name} : ${ server.port} : @project.version@
spring :
application :
name : lagou- service- config
cloud :
config :
server :
git :
uri : https: //github.com/wobushigoudao/lagou- config.git
username : wobushigoudao
password : wurtr564
search-paths :
- lagou- config
label : master
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 mysal:
user: jetwu
person:
name: hahaha
< dependency> < groupId> groupId > < artifactId> artifactId > dependency >
server :
port : 9100
Spring :
application :
name : lagou- service- page
datasource :
driver-class-name : com.mysql.jdbc.Driver
url : jdbc: mysql: //localhost: 3306/lagou?
useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
username : root
password : 123456
cloud :
config :
name : lagou- service- page
profile : dev
label : master
uri : http: //localhost: 9400
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com. lagou. page. controller ;
import org. springframework. beans. factory. annotation. Value ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
@RestController
@RequestMapping ( "/config" )
public class ConfigClientController {
@Value ( "${mysal.user}" )
private String username;
@Value ( "${person.name}" )
private String name;
@GetMapping ( "/query" )
public String getConfiginfo ( ) {
return username+ ":" + name;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
management :
endpoints :
web :
exposure :
include : refresh
management :
endpoints :
web :
exposure :
include : "*"
@RestController
@RequestMapping ( "/config" )
@RefreshScope
public class ConfigClientController {
{
"timestamp" : "2022-09-04T03:12:37.044+0000" ,
"status" : 405 ,
"error" : "Method Not Allowed" ,
"message" : "Request method 'GET' not supported" ,
"trace" : "org.springframework.web.HttpRequestMethodNotSupportedException: Request method 'GET' not supported\ r\ n\ tat org.springframework
[
"config.client.version" ,
"mysal.user"
]
< dependency> < groupId> groupId > < artifactId> artifactId > dependency >
spring :
rabbitmq :
host : 192.168.164.128
port : 5672
username : laosun
password : 123123
management :
endpoints :
web :
exposure :
include : bus- refresh
management :
endpoints :
web :
exposure :
include : "*"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
linux/mac:sh
startup.sh -m standalone
windows:cmd
startup.cmd
< dependencyManagement> < dependencies> < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > < type> type > < scope> scope > dependency > dependencies > dependencyManagement >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 < dependency> < groupId> groupId > < artifactId> artifactId > dependency >
spring :
cloud :
nacos :
discovery :
server-addr : 127.0.0.1: 8848
这里要注意
< dependency> < groupId> groupId > < artifactId> artifactId > dependency >
${prefix} -${spring.profile.active} . ${file-extension}
${prefix} . ${file-extension}
spring :
cloud :
nacos :
discovery :
server-addr : 127.0.0.1: 8848
config :
server-addr : 127.0.0.1: 8848
group : DEFAULT_GROUP
file-extension : yaml
package com. lagou. page. controller ;
import org. springframework. beans. factory. annotation. Value ;
import org. springframework. cloud. context. config. annotation. RefreshScope ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
@RestController
@RequestMapping ( "/config" )
@RefreshScope
public class ConfigClientController {
@Value ( "${lagou.message}" )
private String message;
@GetMapping ( "/query" )
public String getRemoteConfig ( ) {
return message;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
package com. lagou. page. controller ;
import org. springframework. beans. factory. annotation. Value ;
import org. springframework. cloud. context. config. annotation. RefreshScope ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
@RestController
@RequestMapping ( "/config" )
@RefreshScope
public class ConfigClientController {
@Value ( "${lagou.message}" )
private String message;
@Value ( "${pagea}" )
private String pagea;
@Value ( "${pageb}" )
private String pageb;
@GetMapping ( "/query" )
public String getRemoteConfig ( ) {
return message+ "-" + pagea+ "-" + pageb;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
spring :
cloud :
nacos :
discovery :
server-addr : 127.0.0.1: 8848
config :
server-addr : 127.0.0.1: 8848
group : DEFAULT_GROUP
file-extension : yaml
ext- config[ 0 ] :
data-id : pagea.yaml
group : DEFAULT_GROUP
refresh : true
ext- config[ 1 ] :
data-id : pageb.yaml
group : DEFAULT_GROUP
refresh : true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
< dependency> < groupId> groupId > < artifactId> artifactId > dependency >
server :
port : 9101
Spring :
main :
allow-bean-definition-overriding : true
application :
name : lagou- service- page
datasource :
driver-class-name : com.mysql.jdbc.Driver
url : jdbc: mysql: //localhost: 3306/lagou?
useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
username : root
password : 123456
cloud :
nacos :
discovery :
server-addr : 127.0.0.1: 8848
config :
server-addr : 127.0.0.1: 8848
group : DEFAULT_GROUP
file-extension : yaml
sentinel :
transport :
dashboard : 127.0.0.1: 8080
port : 8719
Management :
endpoints :
web :
exposure :
include : "*"
endpoint :
health :
show-details : always
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 Spring :
main :
allow-bean-definition-overriding : true
application :
name : lagou- service- page
sentinel :
filter :
enabled : false
package com. lagou. page. controller ;
import org. springframework. web. bind. annotation. GetMapping ;
import org. springframework. web. bind. annotation. RequestMapping ;
import org. springframework. web. bind. annotation. RestController ;
@RestController
@RequestMapping ( "/user" )
public class UserController {
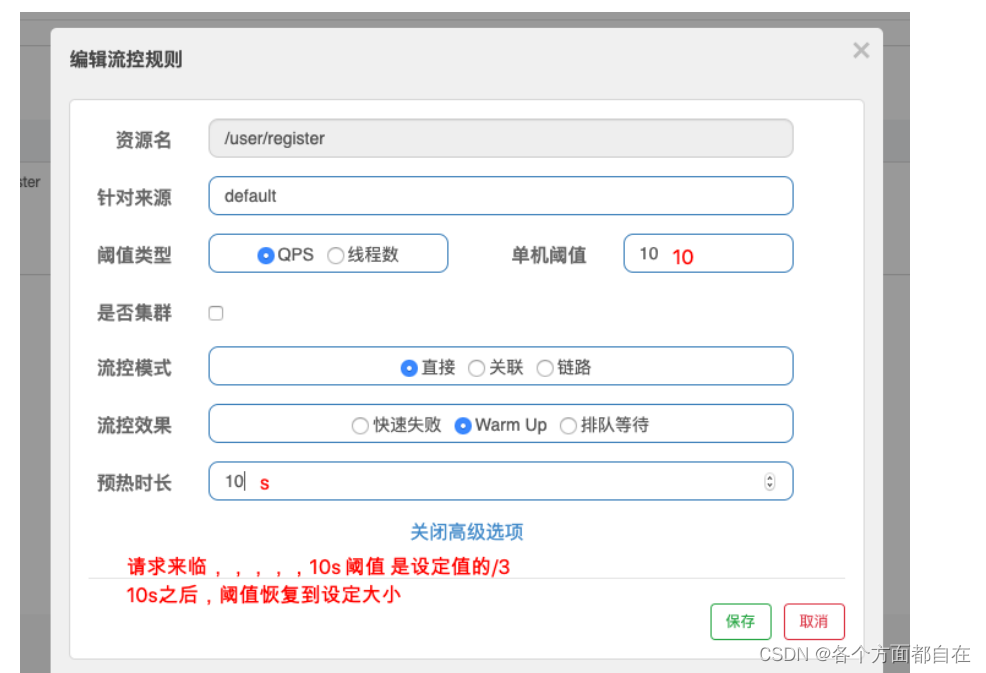
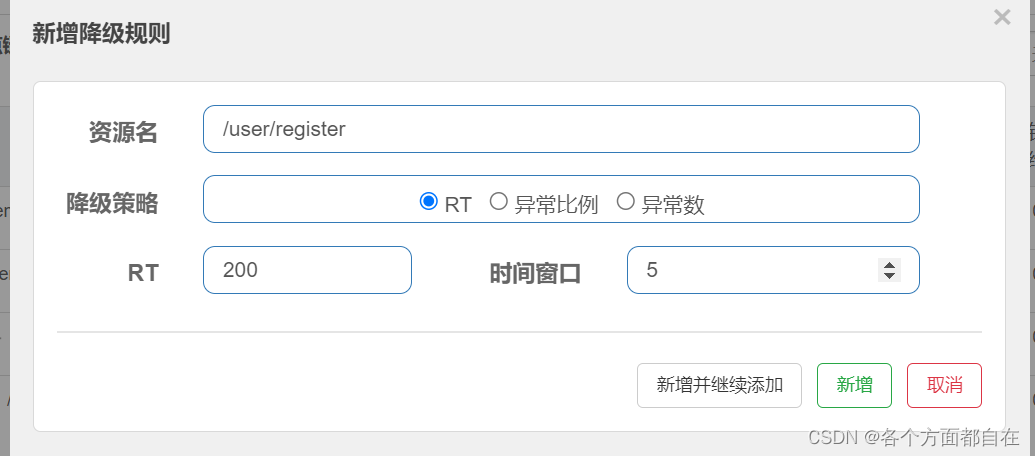
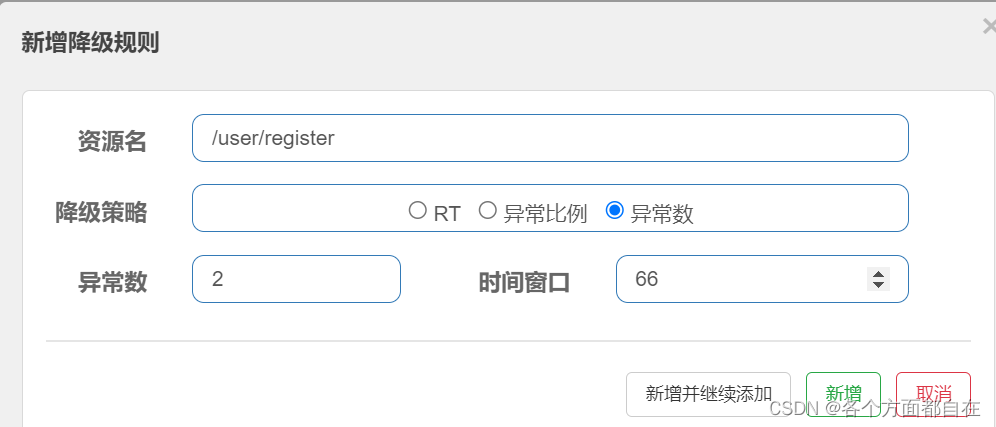
@GetMapping ( "/register" )
public String register ( ) {
System . out. println ( "Register success!" ) ;
return "Register success!" ;
}
@GetMapping ( "/validateID" )
public String validateID ( ) {
System . out. println ( "validateID" ) ;
return "ValidateID success!" ;
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
@GetMapping ( "/validateID" )
public String validateID ( ) {
String format = new SimpleDateFormat ( "yyyy/MM/dd mm:ss" ) . format ( new Date ( ) ) ;
System . out. println ( format) ;
System . out. println ( "validateID" ) ;
return "ValidateID success!" ;
}
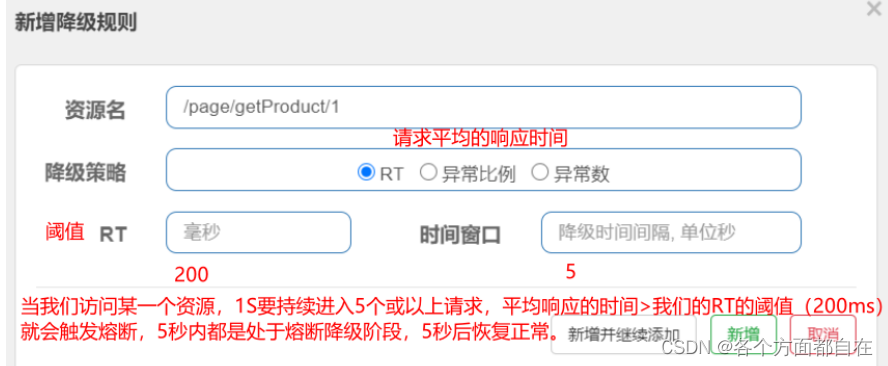
持续 进入 5 个或者5 个以上的请求(注意:最少是5个,否则不会操作熔断)持续 表示,即"1s 内持续进入 5 个或者5 个以上的请求"
@GetMapping ( "/register" )
public String register ( ) throws InterruptedException {
Thread . sleep ( 1000 ) ;
System . out. println ( "Register success!" ) ;
return "Register success!" ;
}
@GetMapping ( "/register" )
public String register ( ) throws InterruptedException {
int i = 1 / 0 ;
System . out. println ( "Register success!" ) ;
return "Register success!" ;
}