-
ElasticSearch入门到入土手册请查阅
这里是weihubeats,觉得文章不错可以关注公众号小奏技术,文章首发。拒绝营销号,拒绝标题党
ElasticSearch来源
伦敦的公寓内,Shay Banon 正在忙着寻找工作,而他的妻子正在蓝带 (Le Cordon Bleu) 烹饪学校学习厨艺。在空闲时间,他开始编写搜索引擎来帮助妻子管理越来越丰富的菜谱。
他的首个迭代版本叫做 Compass。第二个迭代版本就是 Elasticsearch(基于 Apache Lucene 开发)。他将 Elasticsearch 作为开源产品发布给公众,并创建了 #elasticsearch IRC 通道,剩下来就是静待用户出现了。
公众反响十分强烈。用户自然而然地就喜欢上了这一软件。由于使用量急速攀升,此软件开始有了自己的社区,并引起了人们的高度关注,尤其引发了 Steven Schuurman、Uri Boness 和 Simon Willnauer 的浓厚兴趣。他们四人最终共同组建了一家搜索公司

流行程度
这里我们看看github的star数就可以看到喜欢的人到底有多少
用途
- 日志处理和分析(ELK, elasticsearch+logstash+kibana)
- 电商网站,检索商品
Elasticsearch特点
- 性能高,在全文索引方面的搜索非常快
- 分布式,可以分成多分片存储和搜索海量数据
- 存储数据是非结构化的,可以简单理解为存储的是json数据,可以随意添加字段
- 不支持事务
- 支持中文分词、相关读排名搜索
- 近实时,数据写入到被可以被读取到有小延迟,大概在一秒左右
核心概念
为了方便我们理解,我们与数据库中的一些概念做一些简单的比对
index
索引,相当于数据库中的一个数据库(Database)
我们可以简单看看elasticsearch中的所有索引语法
查看索引
GET _cat/indices?v- 1
创建索引
PUT /test_index- 1
删除索引
DELETE /test_index- 1
Type
可以理解为数据库中的表。在elasticsearch 7.0.0之后就不建议使用了,创建文档后面的会有一个type为_doc
8.0.0版本后的elasticsearch将完全废弃
include_type_name 参数可控制type相关api为什么废弃
其实原因很简单- 我们知道数据库中的表在数据库中是独立存储的,而同一个index下不同的type是存储在同一个索引下面的,所以不同type下相同名字的字段定义的mapping也必须一致
- 影响性能

Document
索引(Index)中的每条记录就是
Document我们这里简单查看一下商品索引的里面的一些数据
GET test_index/_search- 1
等价于
GET test_index/_doc/_search- 1
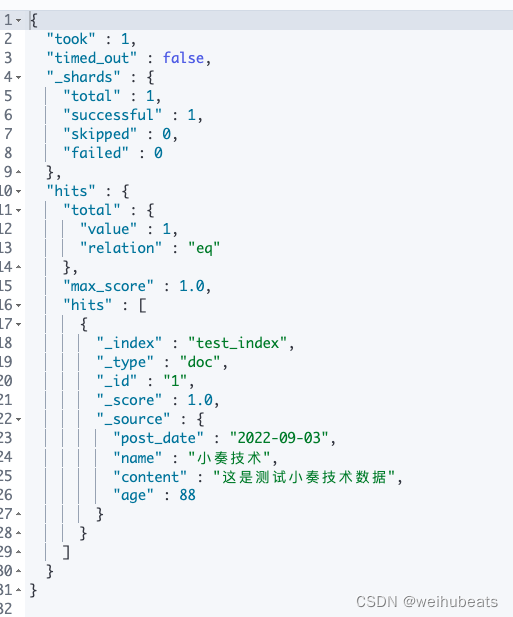
_index: 文档所属索引_type: 后续将废弃_id: Doc的主键。在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值_source: 相关度评分
Document的CRUD
插入数据
指定id
PUT /test_index/doc/1 { "post_date": "2022-09-03", "name": "小奏技术", "content": "这是测试小奏技术数据", "age": 88 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用自动生成id方式
POST /test_index/_doc { "post_date": "2022-09-03", "name": "小奏技术1", "content": "这是测试小奏技术1数据", "age": 882 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
新增字段
PUT /test_index/doc/1 { "post_date": "2022-09-03", "name": "小奏技术", "content": "这是测试小奏技术数据", "age": 88, "label": "开心" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
删除文档
DELETE test_index/_doc/oo0cAoABFI-iZ3BAcffx- 1
这里的
oo0cAoABFI-iZ3BAcffx是_idMapping
Mapping可以简单理解为数据库中表中字段的类型,与数据库不同的是在es中我们可以不用手动指定Mapping,在插入数据的时候es可以为我们自动生成Mapping我们来简单看看我们之前自动生成的
Mapping查看Mapping
查询语法
GET /test_index/_mapping- 1

指定Mapping
我们也可以在创建索引的时候同时指定
_mappingPUT /test_index { "mappings" : { "properties" : { "author_id" : { "type" : "long" }, "content" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "post_date" : { "type" : "date" }, "title" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
mapping只能创建index手动指定mapping或者新增field mapping,但是不能更新update field mapping
mapping的类型主要有如下几种
整体核心架构
倒排索引
假设我们有如下内容,看看是如何建立倒排索引的
文档ID 文档内容 1 Test ElasticSearch 2 ElasticSearch Server 3 ElasticSearch Server1 建立的倒排索引如下
Term Count DocumentId:Position ElasticSearch 3 1:1,2:0,3:0 Test 1 1:0 Server 1 2:1 Server1 1 3:1 es中的每个字段都有自己的倒排索引。
我们也可以对某个字段不做索引- 优点: 节约存储空间
- 缺点: 无法被搜索到
分词
简单来说就将我们的文本通过分词分成很多词根然后去建立倒排索引供我们搜索
我们在搜索的时候也会将我们的搜索词通过分词去搜索ElasticSearch内置分词器
Standard Analyzer
- 默认分词器,按词切分,小写处理
POST _analyze { "analyzer": "standard", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone." }- 1
- 2
- 3
- 4
- 5
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ]
Simple Analyzer:
- 每当遇到不是字母的字符时,分析器就把文本分成词组。它把所有的词组都小写
POST _analyze { "analyzer": "simple", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone." }- 1
- 2
- 3
- 4
- 5
[ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
Whitespace Analyzer
- 按空格切分,不转小写
POST _analyze { "analyzer": "whitespace", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone." }- 1
- 2
- 3
- 4
- 5
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ]
Stop Analyzer
- 小写处理,停用词过滤(the、a、is)
POST _analyze { "analyzer": "stop", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone." }- 1
- 2
- 3
- 4
- 5
[ quick, brown, foxes, jumped, over, lazy, dog, s, bone ]
Keyword Analyzer:
- 不分词 直接接当输入当做输出
POST _analyze { "analyzer": "keyword", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone." }- 1
- 2
- 3
- 4
- 5
[ The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. ]
Pattern Analyzer
- 正则表达式分词,默认\W+(非字符分割)
POST _analyze { "analyzer": "pattern", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone." }- 1
- 2
- 3
- 4
- 5
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
Language Analyzers
- 语言分词,提供了30多种语言

Fingerprint Analyzer:
- 主要用于消除重复词
POST _analyze { "analyzer": "fingerprint", "text": "Yes yes, Gödel said this sentence is consistent and." }- 1
- 2
- 3
- 4
- 5
[ and consistent godel is said sentence this yes ]
自定义分词
- 像中文默认是没有分词器的,我们可以通过安装配置中文分词器比如IK分词
中华人民 -》 中华 人民
URI 搜索
- 完整参数
GET /test_index/_search?q=小奏技术&df=name&sort=age:desc&from=0&size=1&timeout=1s { "profile": "true" }- 1
- 2
- 3
- 4
简单解释参数的意义
- Q: 查询语句
- df:查询的默认字段,默认不指定查询全部字段
- Sort: 排序
- From&Size 分页
- Profile: 查询查询过程
查询DSL
简单理解就是通过HTTP Request Body将查询请求发送到ElasticSearch
查询所有
GET test_index/_search { "query": { "match_all": {} } }- 1
- 2
- 3
- 4
- 5
- 6
分页
GET test_index/_search { "query": { "match_all": {} } , "from": 0, "size": 2 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 默认返回10条结果
- 翻页越靠后性能越低
排序
GET test_index/_search { "query": { "match_all": {} } , "from": 0, "size": 2, "sort": [ { "age": { "order": "desc" } } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
查询指定字段
GET test_index/_search { "query": { "match_all": {} } , "from": 0, "size": 2, "sort": [ { "age": { "order": "desc" } } ], "_source": ["age", "name"] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Match
- 对输入值进行分词查询
GET test_index/_search { "query": { "match": { "name": "小奏 小奏技术" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

实际等价于
GET test_index/_search { "query": { "match": { "name": { "query": "小奏 小奏技术", "operator": "or" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以将 or 改成 and 意思就是必须保护 两者的分词

Term
- 对输入值不做任何分词处理
GET test_index/_search { "query": { "term": { "name": { "value": "小奏" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

match_phrase
- match_phase中的所有term都出现在待查询字段之中
- 2.待查询字段之中的所有term都必须和match_phase具有相同的顺序
GET test_index/_search { "query": { "match_phrase": { "name": "小奏 小奏技术" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
term、match、match_phrase区别
- term:传入的文本原封不动地(不分词)拿去查询。
- match:对输入进行分词处理后再去查询,部分命中的结果也会按照评分由高到低显示出来
- match_phrase: match_phrase按短语查询,会将输入的text进行分词然后进行查询,只有包含所有分词并且分词顺序一致才会查询出来
term、match_phrase都是用于精准匹配,match用于模糊匹配
query_string
GET test_index/_search { "query": { "query_string": { "default_field": "name", "query": "小奏 AND 小奏技术" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
类似URI Query
simple_query_string
GET test_index/_search { "query": { "simple_query_string": { "query": "小奏 AND 小奏技术", "fields": ["name"] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
query_string 与 simple_query_string 区别
query_string查询小奏 AND 小奏技术,会解析成查询必须要同时包含小奏和小奏技术
而simple_query_string则是将其分词成小奏,AND和小奏技术,默认的operator为ORfilter
GET test_index/_search { "query": { "constant_score": { "filter": { "term": { "name": "haofeng" } }, "boost": 1.2 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
有时候我们在一些查询不涉及到相关度评分,或者是完全的精准匹配。我们就可以使用filter代替query
使用filter的好处- filter 可以忽略TF-IDF计算,避免相关性算分的开销
- filter可以有效利用缓存
Filter 查询多条件
GET test_index/_search { "query": { "constant_score": { "filter": { "bool": { "should":[ { "term":{"age":221} }, { "term":{"age":222} } ] } }, "boost": 1.2 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
bool查询
bool查询是一个或多个查询子句的组合
总共四种子句。两种计分、两种不计分
- must:必须匹配,参与计分
- Should: 选择性匹配,参与计分
- must_not: 必须不匹配 不参与计分
- Filter:必须匹配,但不计分
GET test_index/_search { "query": { "bool": { "must": [ { "term": { "name": { "value": "小奏" } } } ], "must_not": [ { "term": { "age": { "value": "222" } } } ], "should": [ { "term": { "content": { "value": "测试" } } }, { "term": { "post_date": { "value": "2022-09-03" } } } ], "minimum_should_match": 1 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
Boost
boost主要用于控制相关得分的
- 当boost > 1 ,相关度得分提升
- 当 0< boost < 1.相关读得分降低
简单举例
GET test_index/_search { "query": { "bool": { "must": [ { "term": { "name": { "value": "haofeng", "boost": 2 } } } ], "must_not": [ { "term": { "age": { "value": "222" } } } ], "should": [ { "term": { "content": { "value": "测试", "boost": 2 } } }, { "term": { "post_date": { "value": "2022-09-03" } } } ], "minimum_should_match": 1 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
Scroll
在搜索返回单页结果的时候。如果数据量很大,一次性查询比如10w数据量数据性能可能会很差,elasticsearch提供了scoll滚动查询,一批一批的查,直到所有数据都查询完处理完
每次scroll搜索我们需要指定一个时间窗口,每次查询请求在这个时间窗口完成就可以
GET test_index/_search?scroll=1m { "query": { "match": { "name":{ "query": "小奏" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
获得的结果会有一个scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
GET /_search/scroll { "scroll":"1m", "scroll_id":"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFms4a1IyNTNlUzlHTmppcTQtV3ZEVEEAAAAAAGmsnBZLNktRZVZBbFFTUzdyTk5EZWZ6TWxn" }- 1
- 2
- 3
- 4
- 5
scroll看着像分页,但实际应用场景可能有所不同,分页是一页一页搜索给用户看。scroll主要用于一批一批查询,让系统进行处理
Aggregation
聚合简单理解就是对数据进行分组聚合查询
类似Mysql 的 select count(lable) from product group by type- 1
其中
count(lable) == Metric
Group by type == Bucket下面我们深入理解下Aggregation中的两个核心概念
Bucket
city name 北京 小张 北京 老李 广州 小奏 广州 关羽 广州 张飞 按city划分bucket,分为北京、广州两个bucket
- 北京bucket:小张、老李
- 广州bucket:小奏、关羽、张飞
Metric
当我们有了bucket之后我们可以对这一系列的bucket数据进行聚合分析。
简单理解就是Metric就是对Bucket进行聚合分析,比如求 平均值、最大值、最小值简单实操
数据准备
- 创建索引
PUT /tvs { "mappings": { "properties": { "price": { "type": "long" }, "color": { "type": "keyword" }, "brand": { "type": "keyword" }, "sold_date": { "type": "date" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 插入数据
POST /tvs/_bulk { "index": {}} { "price" : 1000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-10-28" } { "index": {}} { "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-11-05" } { "index": {}} { "price" : 3000, "color" : "绿色", "brand" : "小米", "sold_date" : "2016-05-18" } { "index": {}} { "price" : 1500, "color" : "蓝色", "brand" : "TCL", "sold_date" : "2016-07-02" } { "index": {}} { "price" : 1200, "color" : "绿色", "brand" : "TCL", "sold_date" : "2016-08-19" } { "index": {}} { "price" : 2000, "color" : "红色", "brand" : "长虹", "sold_date" : "2016-11-05" } { "index": {}} { "price" : 8000, "color" : "红色", "brand" : "三星", "sold_date" : "2017-01-01" } { "index": {}} { "price" : 2500, "color" : "蓝色", "brand" : "小米", "sold_date" : "2017-02-12" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
查询每种电视机的销量
GET /tvs/_search { "size": 0, "aggs": { "group_colors": { "terms": { "field": "color" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- size:0,不展示原始数据
- aggs: 要对一份数据执行分组聚合操作
- group_colors:就是对每个aggs,都要起一个名字,这个名字是随便自定义的
- terms:根据字段的值进行分组
- field:根据指定的字段的值进行分组
查询每种颜色电视机的平均价格
GET /tvs/_search { "size": 0, "aggs": { "colors": { "terms": { "field": "color" }, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
等价于如下sql
Select avg(price) from tvs._doc group by color- 1
多 metric查询
在sql 查询中使用的比较多的就是
- Count
- Avg
- Max
- Min
- Sum
GET /tvs/_search { "size": 0, "aggs": { "group_by_colors": { "terms": { "field": "color" }, "aggs": { "avg_price": { "avg": { "field": "price" } }, "min_price":{ "min": { "field": "price" } }, "max_price":{ "min": { "field": "price" } }, "sum_price":{ "sum": { "field": "price" } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
histogram
指定一个interval去划分bucket
比如指定interval为2000,则划分的区域为
[0,2000) [2000,4000) [4000,6000) [6000,8000) [8000,10000)GET tvs/_search { "size": 0, "aggs": { "price": { "histogram": { "field": "price", "interval": 2000 }, "aggs": { "revenue": { "sum": { "field": "price" } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
下钻分析
按颜色、颜色+品牌下钻分析
GET /tvs/_search { "size": 0, "aggs": { "group_by_color": { "terms": { "field": "color" }, "aggs": { "color_avg_price": { "avg": { "field": "price" } }, "group_by_brand": { "terms": { "field": "brand" }, "aggs": { "brand_avg_price": { "avg": { "field": "price" } } } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
参考
-
相关阅读:
LeetCode 周赛 345(2023/05/14)体验一题多解的算法之美
台州亿丰克瑞斯伺服驱动器调试说明
域控制器BSP开发工程师面试题
python多线程学
HDU_2457
JeecgBoot 3.4.0 版本发布,微服务重构版本
kube-prometheus 系列1 项目介绍
vue 实现弹出菜单,解决鼠标点击其他区域的检测问题
JS手机号码正则
Java.lang.Class类 getFields()方法有什么功能呢?
- 原文地址:https://blog.csdn.net/qq_42651904/article/details/126734037
