-
中秋节的广西甘蔗——智蔗见智·向新而生
中秋节的时候我们理论上应该放假,但是放假、什么是放假?咱们程序员需要放假?不可能的。所以利用假期时间搞定广西万顷甘蔗地的图像分析还是会有很大的成就感的。
目录
训练资源地址
接下来我们使用华为云的平台来处理甘蔗地图片。
可以在华为云中下载获取,这里得通过桶进行保存:AI Gallery_数据详情_开发者_华为云
训练集数据压缩包解压后是一系列png格式图片,
*_img.png表示遥感图像,与其同名且后缀为_mask.png的图像为对应的label图像。

obs环境准备
先登录到存储服务
https://storage.huaweicloud.com/obs/?locale=zh-cn®ion=cn-north-4
我这有现成的桶我就不再创建了。

没有的需要自己创建一下。
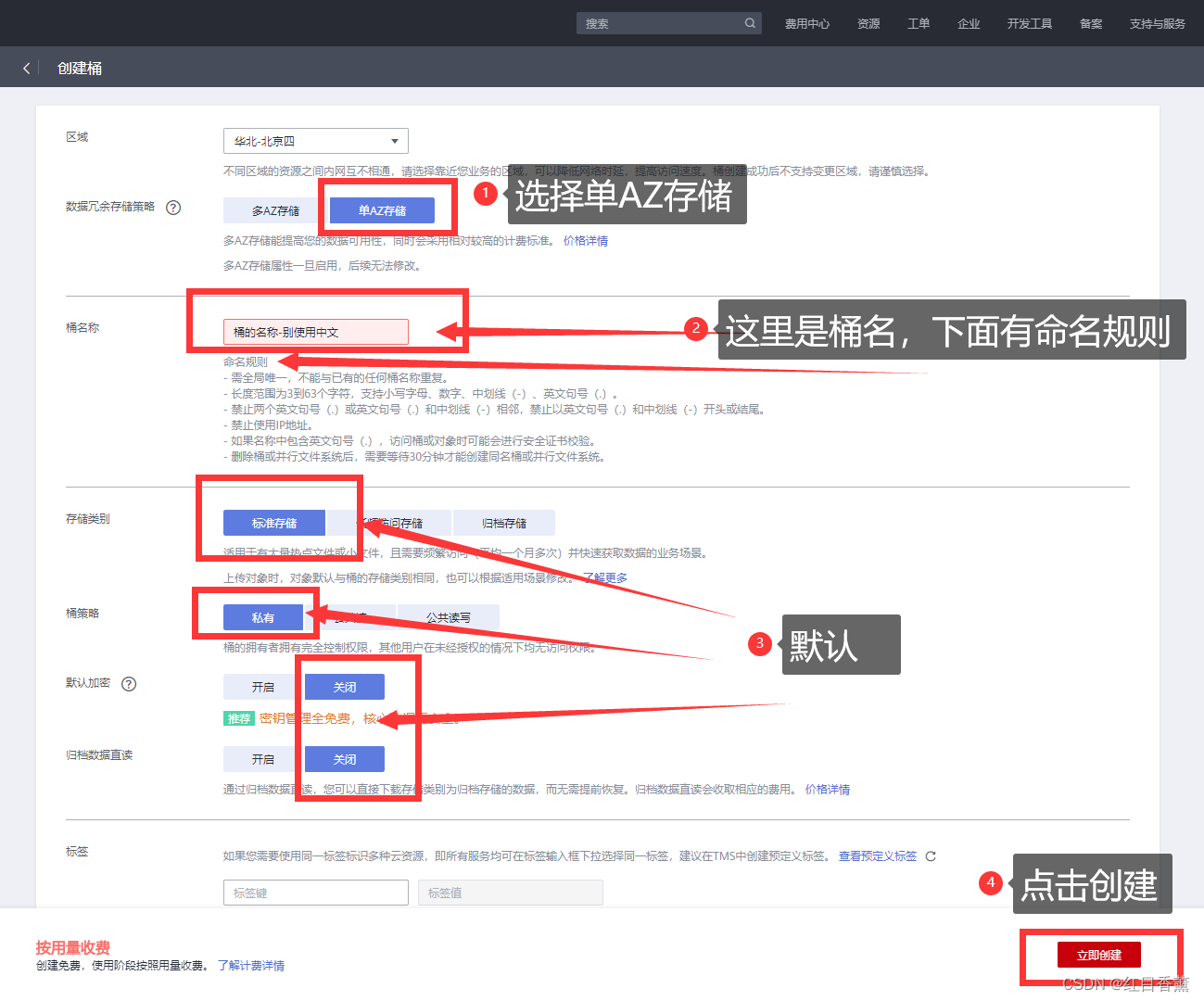
进入桶:
进入:
https://console.huaweicloud.com/modelarts/?region=cn-north-4#/dashboard
咱们需要使用CodeLab
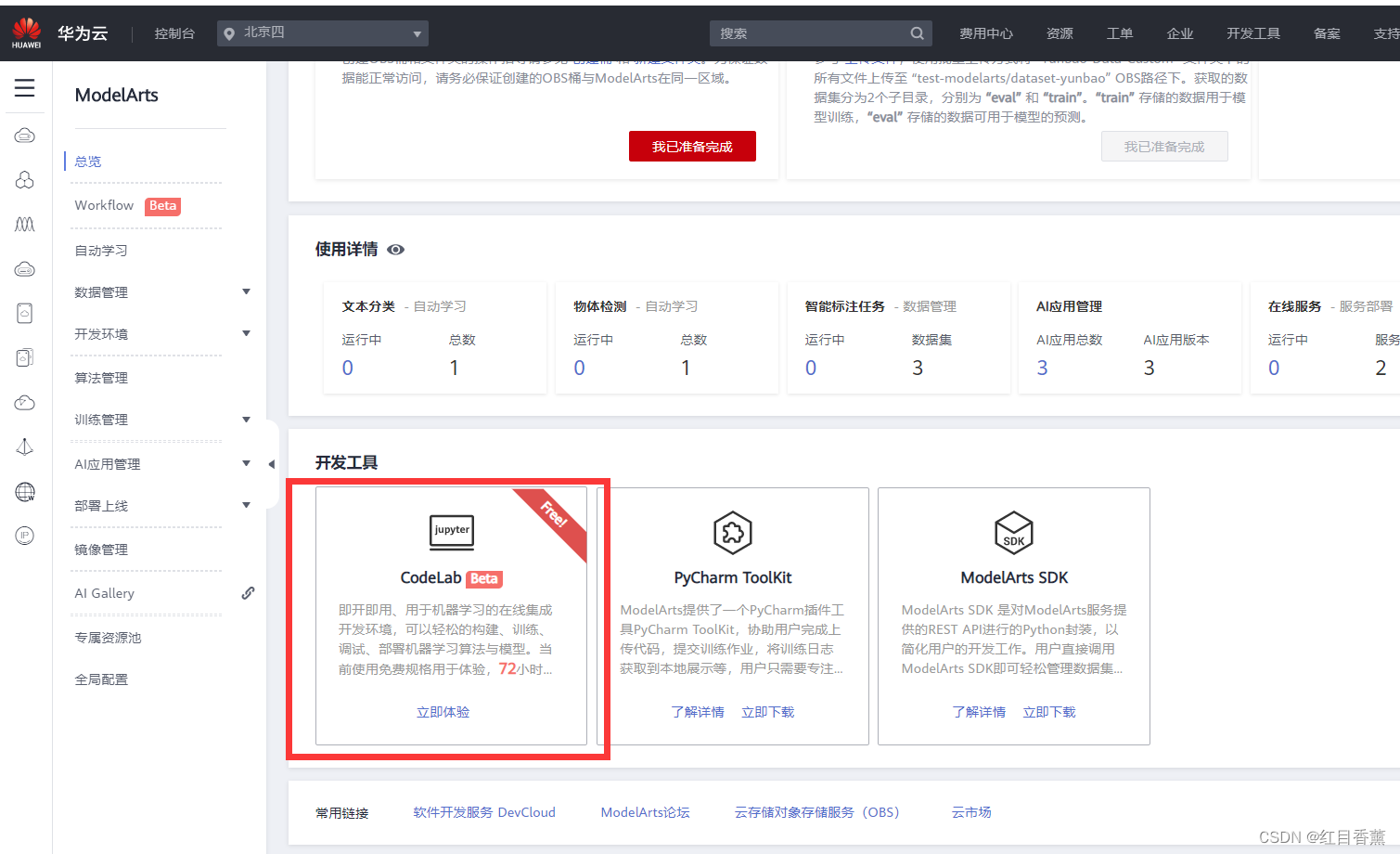
有72小时免费示例,初始化的时候需要等待一会。我9点52开始初始化的。
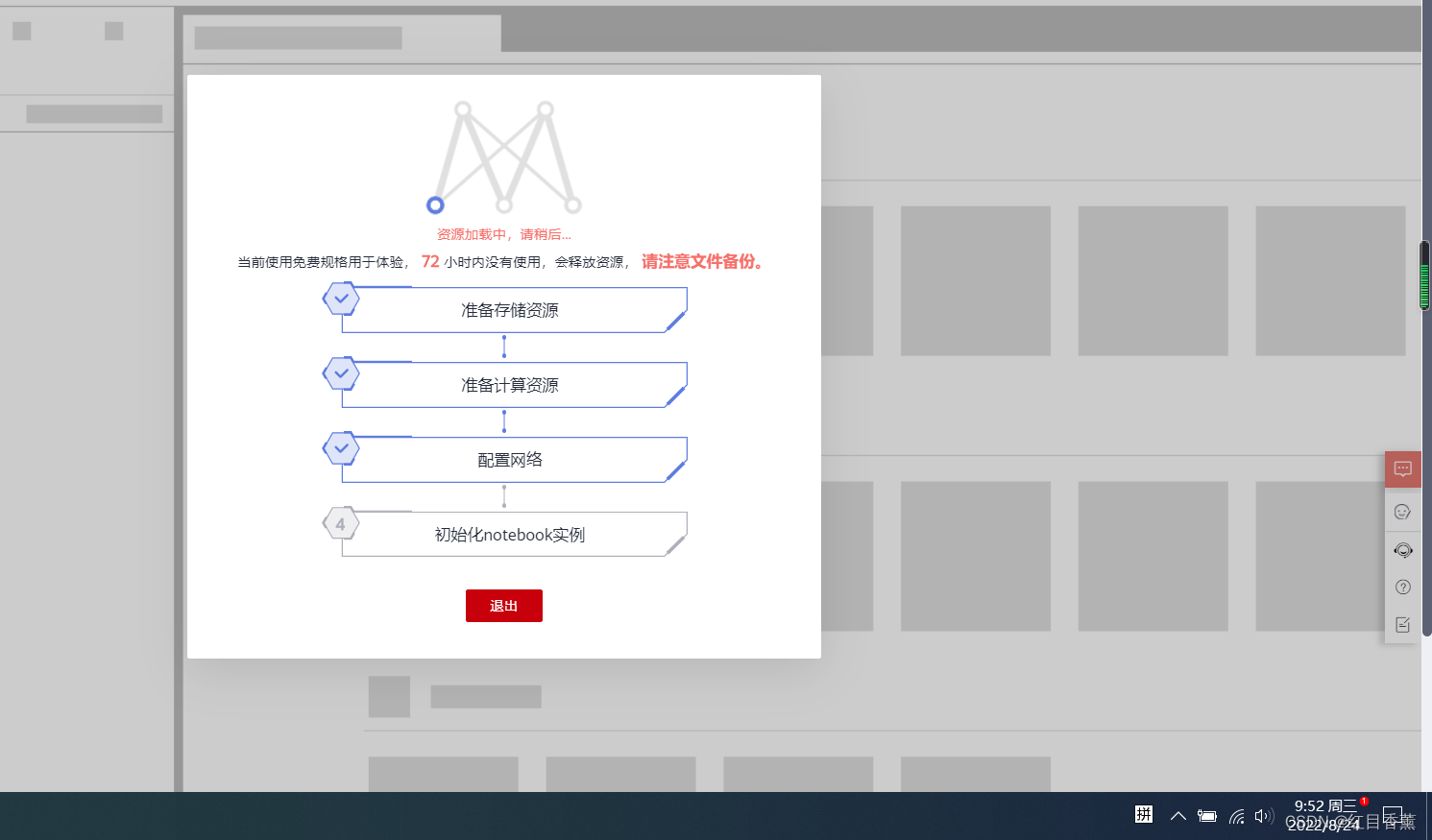
大概1分多钟完成的。
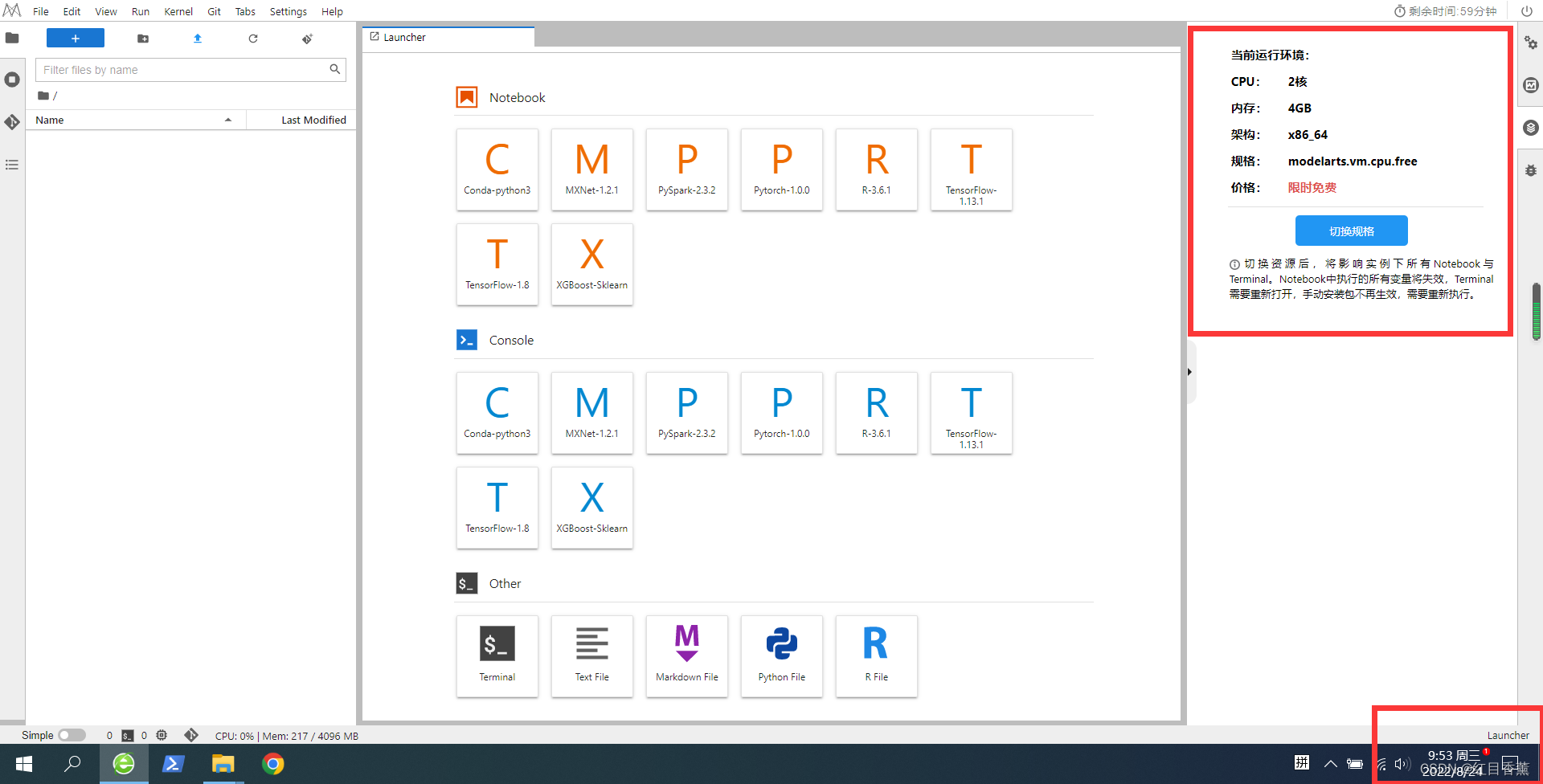
这里咱们选择C【Conda-python3】

进入编码阶段了。示例的桶是我的链接。具体看需求使用啊,从哪里复制到哪里。这里先有个说明,咱们接下来看baseline复现。
- import moxing as mox
- # 拷贝obs数据到notebook环境中
- mox.file.copy('obs://mytestbosqwe8403000/data/train.zip', './train.zip')
- # 拷贝notebook环境中数据到obs
- mox.file.copy('./train.zip', 'obs://mytestbosqwe8403000/data/train.zip')
- !unzip train.zip &> /dev/null
- # copy_parallel用于copy文件夹
- mox.file.copy_parallel('./train', 'obs://mytestbosqwe8403000/data/train/')
baseline复现
通过在modelarts中notebook中编写代码获取(注意这里路径没有换行)
obs地址为
obs://ma-competitions-bj4/guangxi_remote_sense_segmentation/code/,可以通过在notebook中新建如下代码将baseline的代码copy到你的环境下。- import moxing as mox
- mox.file.copy_parallel('obs://ma-competitions-bj4/guangxi_remote_sense_segmentation/code/', 'obs://mytestbosqwe8403000/data/baseline/')
拿到baseline的代码后,可以看到四个文件夹,一共有两个baseline code及其对应的推理代码。对应解释如下
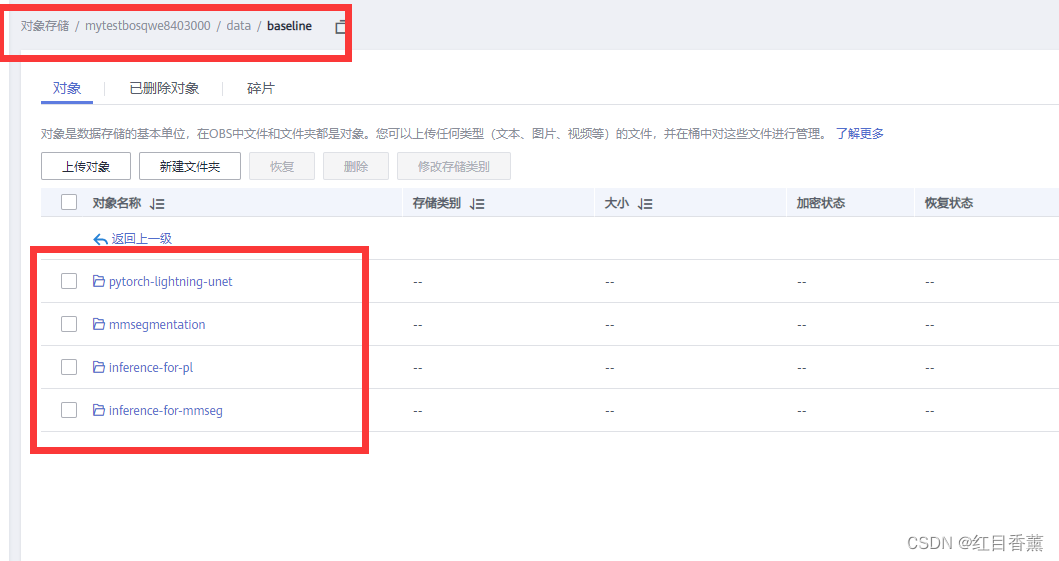
也可以直接复制到代码区
- import moxing as mox
- mox.file.copy_parallel('obs://mytestbosqwe8403000/data/baseline/', './baseline')
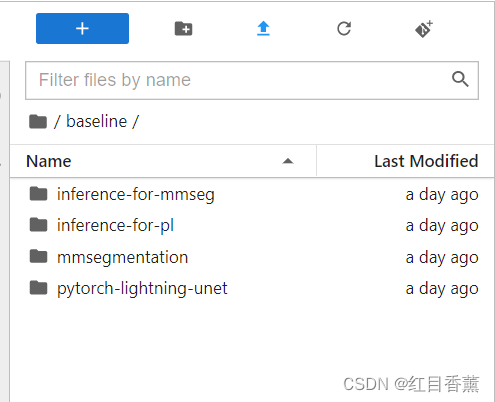
层级介绍
- |-- inference-for-mmseg (推理代码)mmsegmentation 适配 ModelArts 中AI应用的演示代码
- |-- model
- | `-- README.md 演示代码说明文件
- | `-- otherfiles...
- |-- inference-for-pl (推理代码)pytorch-lightning-unet 适配 ModelArts 中AI应用的演示代码
- |-- model
- | `-- README.md 演示代码说明文件
- | `-- otherfiles...
- |-- mmsegmentation mmsegmentation适配于比赛数据的修改版本
- | `-- README.md 安装说明和convnext-upernet相关训练指令说明
- | `-- otherfiles...
- |-- pytorch-lightning-unet 基于pytorch-lightning的unet实现
- | `-- README.md 安装说明和unet相关训练指令说明
- `-- otherfiles...
其中【/baseline/pytorch-lightning-unet/README.md】是说明文档
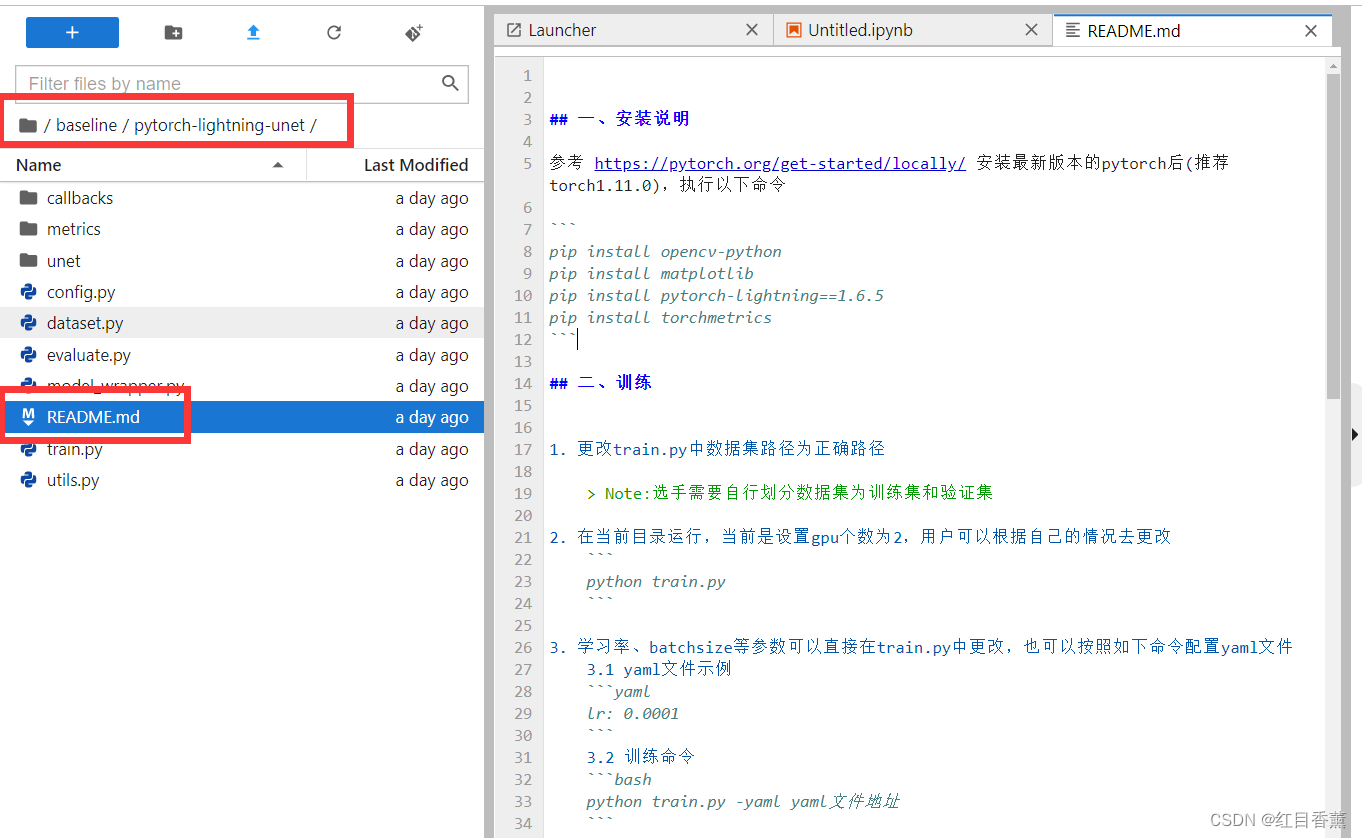
训练方式
https://console.huaweicloud.com/modelarts/?region=cn-north-4#/dev-container/create
直接如下图选择并创建,有券免费。
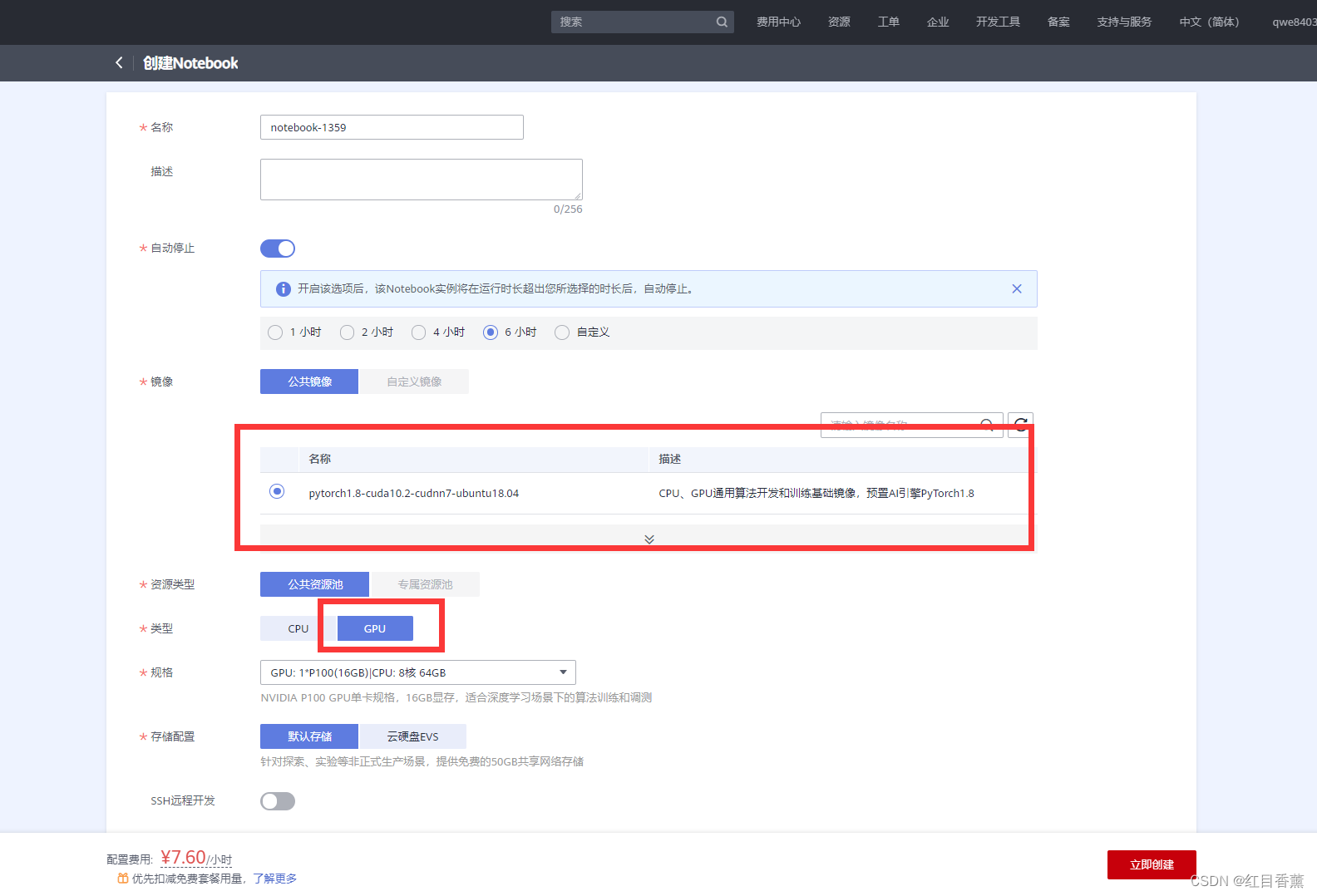
创建需要等一会,完成之后点击【打开】
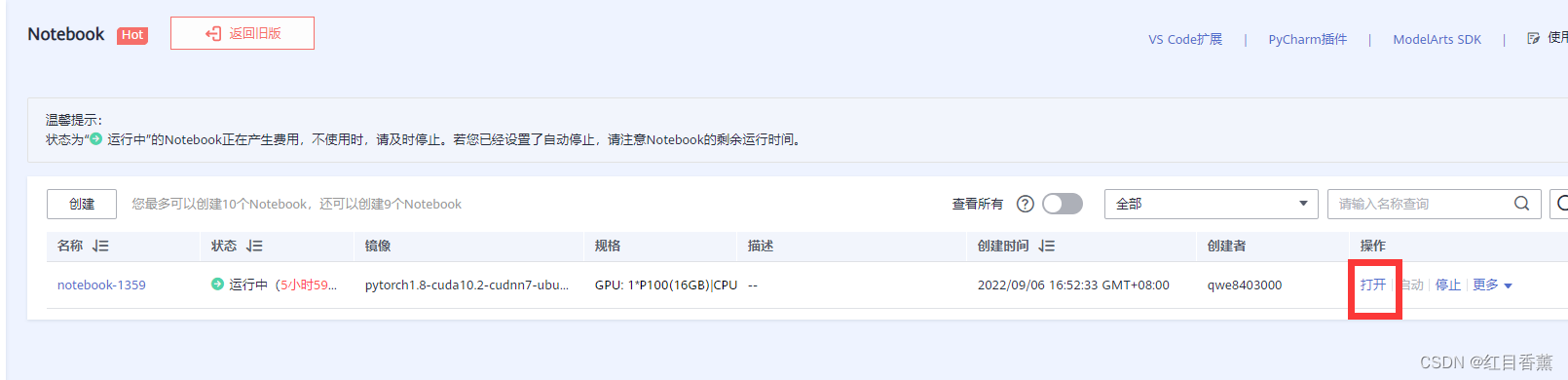
主要使用文件类型
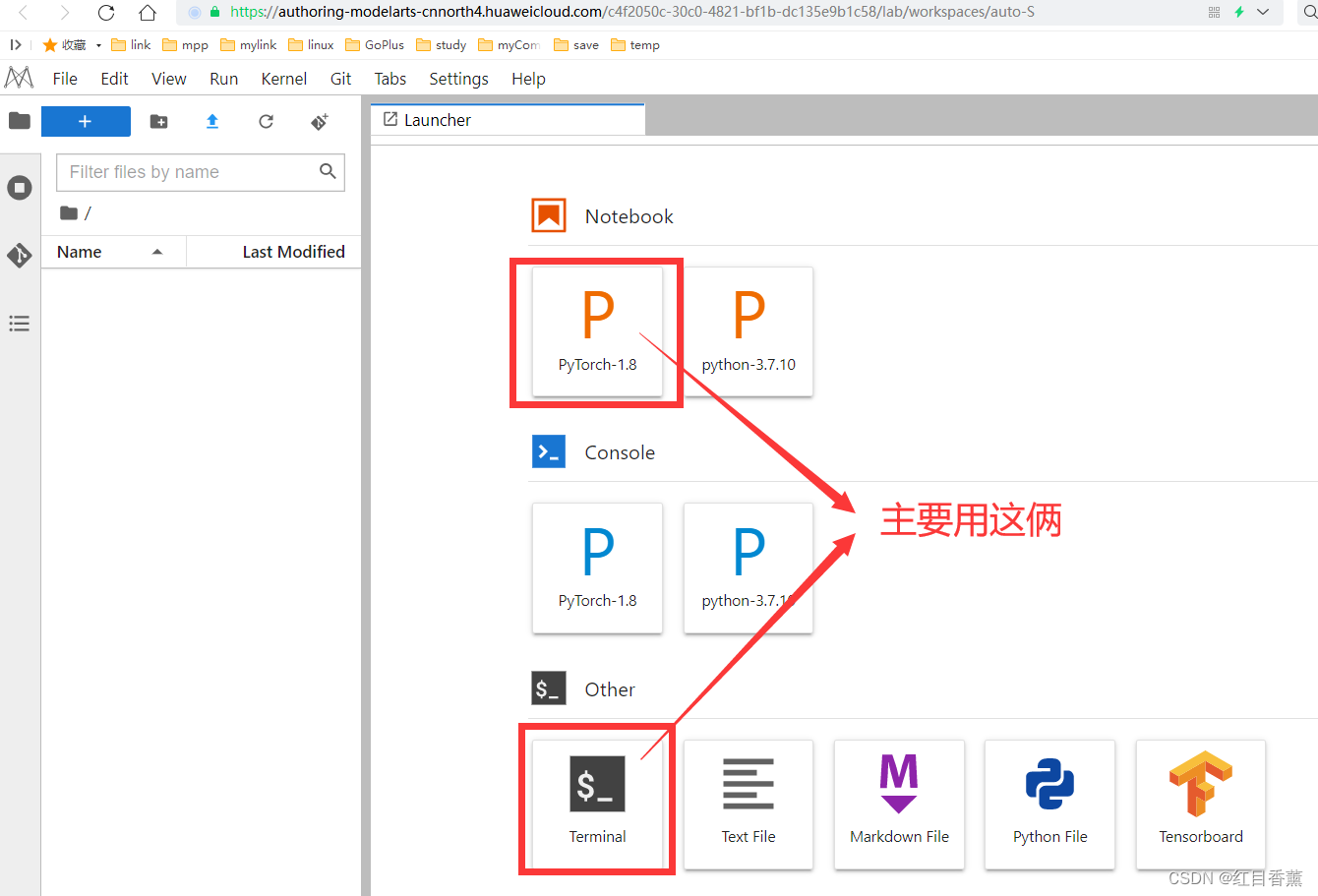
复制baseline
- import moxing as mox
- mox.file.copy_parallel('obs://ma-competitions-bj4/guangxi_remote_sense_segmentation/code/', './baseline')
复制train
mox.file.copy_parallel('obs://mytestbosqwe8403000/data/train.zip', './train.zip')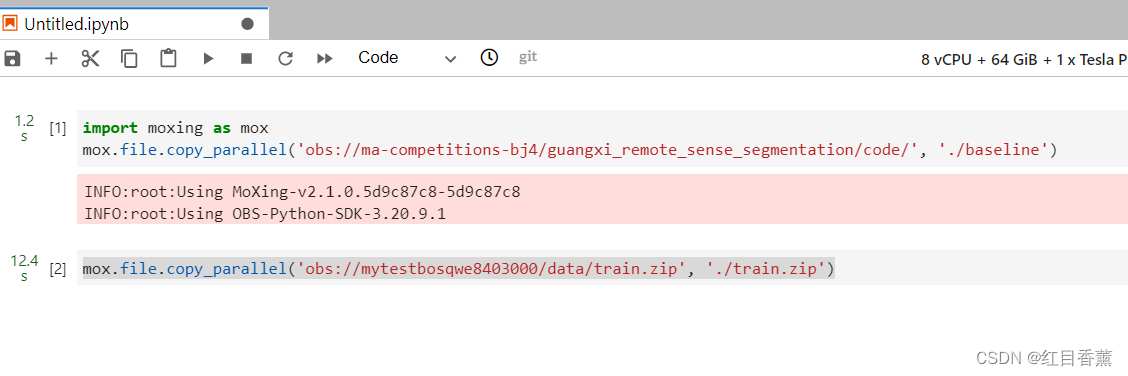
环境升级
添加一个Terminal

升级命令
pip install torchvision==0.12.0 --upgrade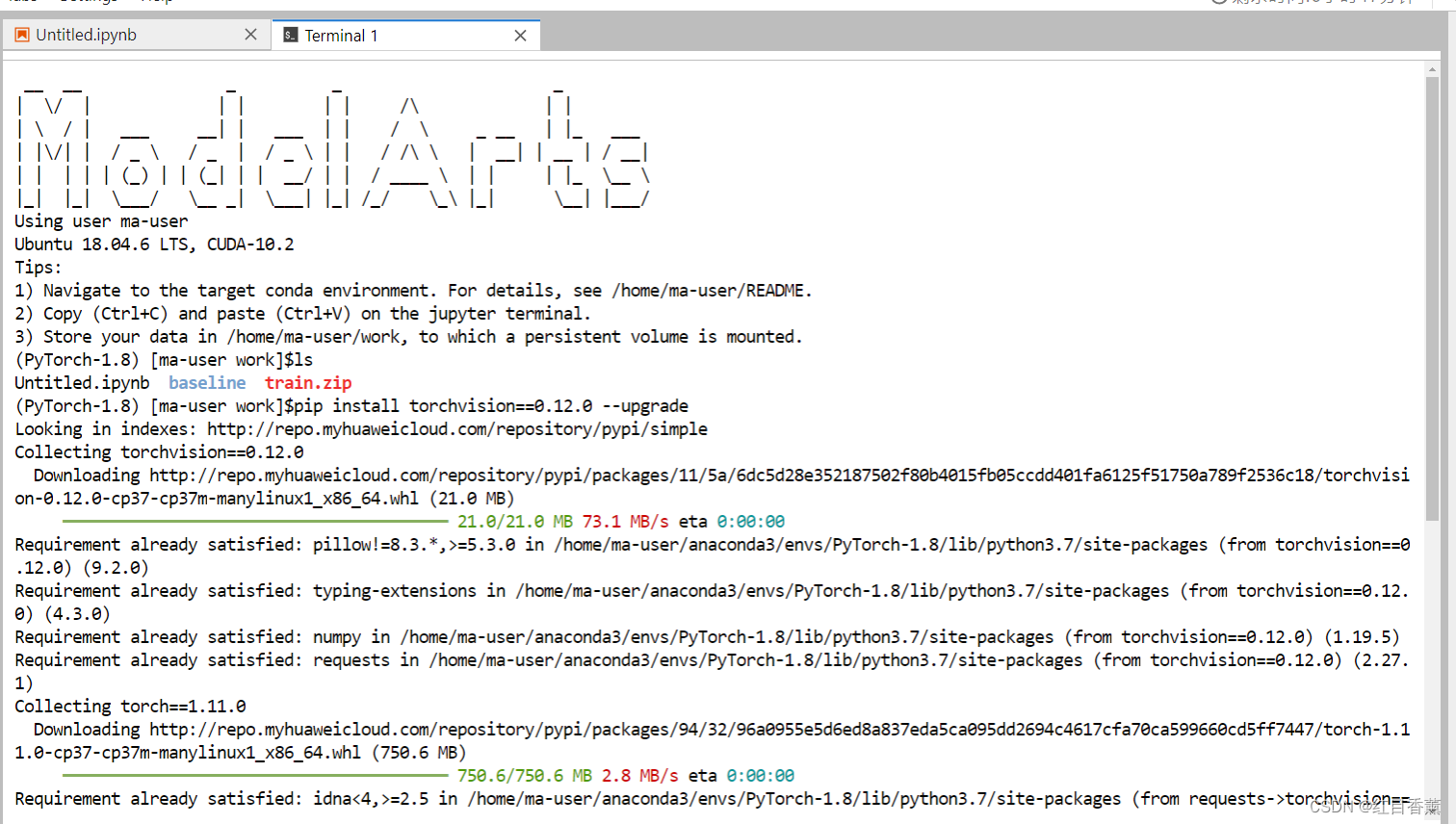
解压zip压缩包
unzip train.zip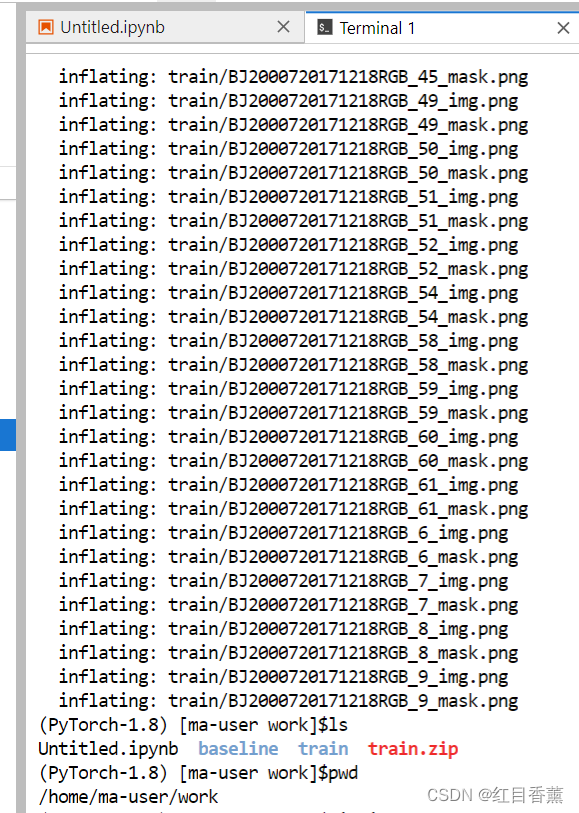
批量操作
- pip install opencv-python
- pip install matplotlib
- pip install pytorch-lightning==1.6.5
- pip install torchmetrics
baseline演示
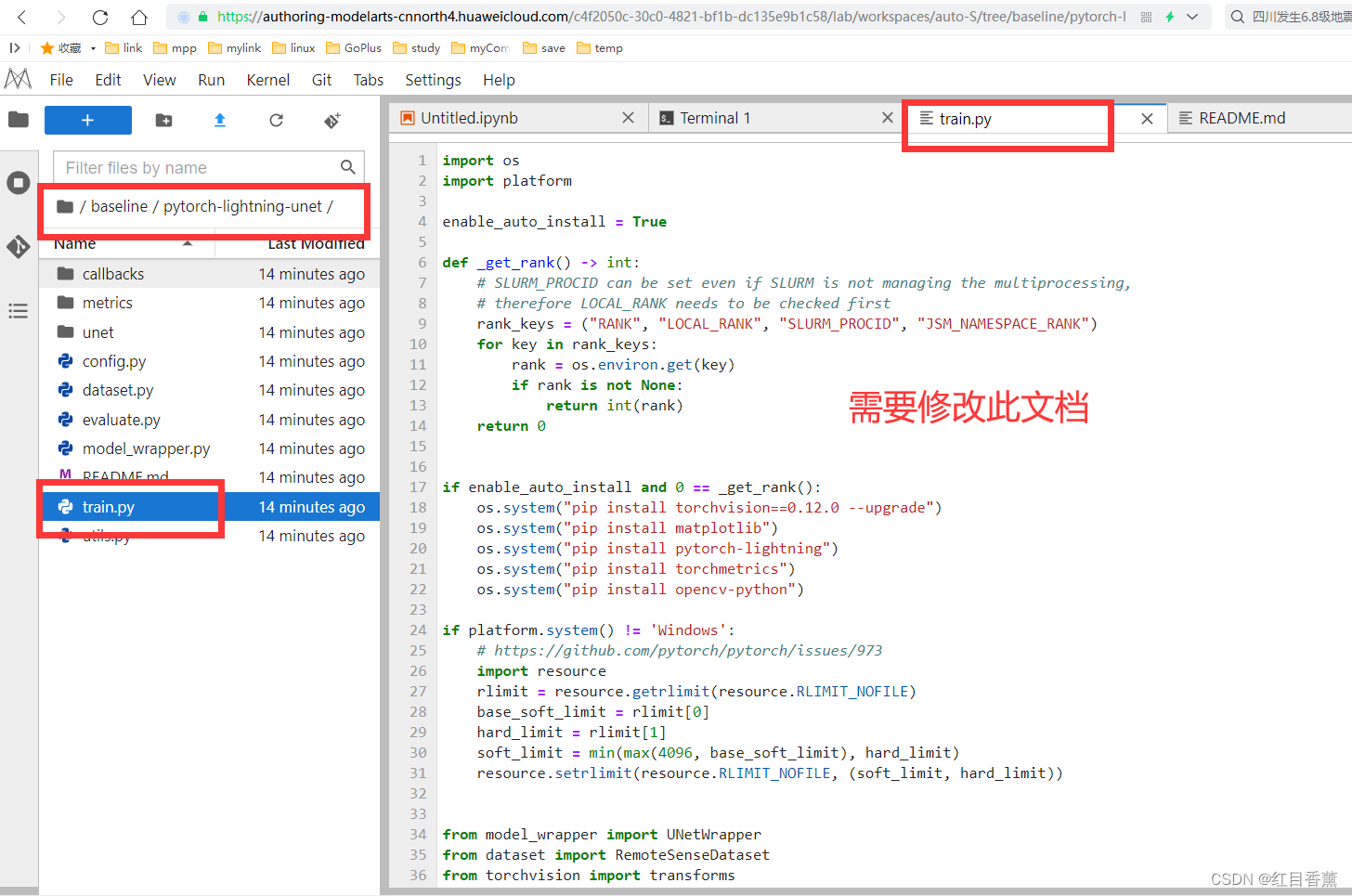
当前的文档中3个内容1是baseline代码,2是操作文件,3是训练图片
训练集和验证集的划分
在72和73行是训练集和测试集
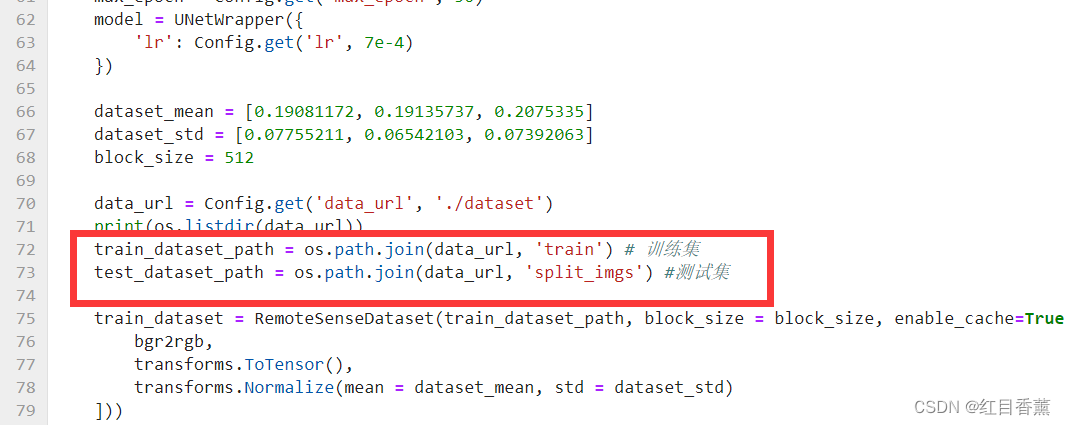
要求的路径是./dataset下,是train.py的相对路径,所以需要单独创建一个dataset文件夹,然后在往里面放置两个文件夹train与split_imgs分别是训练集和测试集,他的代码中有这个文件处理,我们直接都放一个文件夹就行。
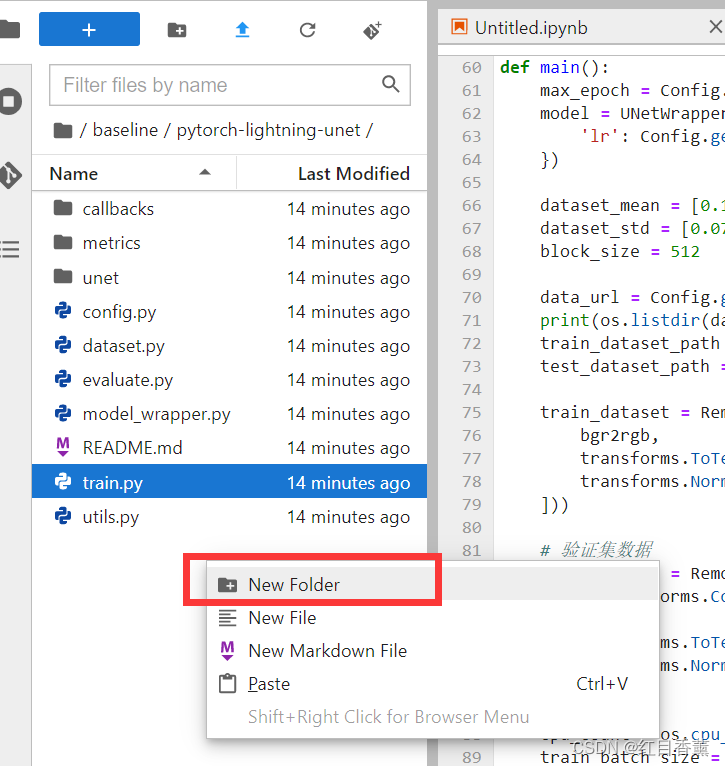
再在/home/ma-user/work/baseline/pytorch-lightning-unet/dataset文件夹下创建train与split_imgs的文件夹,这里复制过来train的文件夹改个名字就行。
- cp -r ./train ./baseline/pytorch-lightning-unet/dataset/train
- cp -r ./train ./baseline/pytorch-lightning-unet/dataset/split_imgs
可以看到已经粘贴过去了。
航拍照片与标记照片都在一个文件夹里面,但是他的代码里面有区分,我们就不用管了。
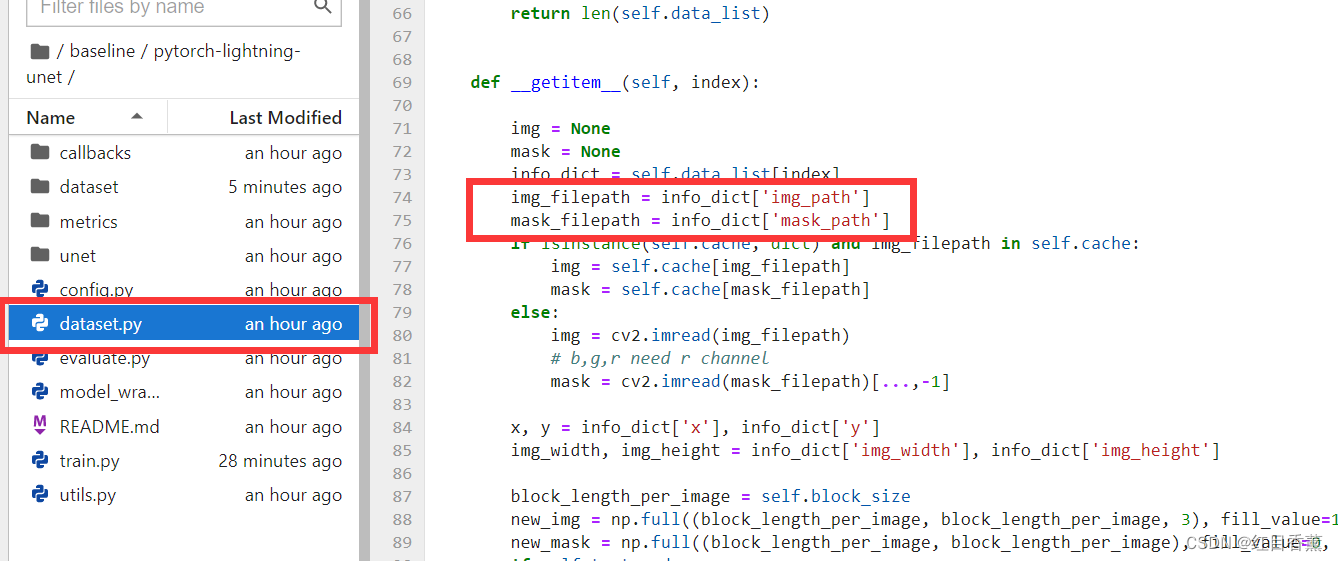
开始训练由于刚才一直在【/home/ma-user/work/】下干活了,咱们需要进入到train.py的文件夹执行
- cd ./baseline/pytorch-lightning-unet/
- python train.py
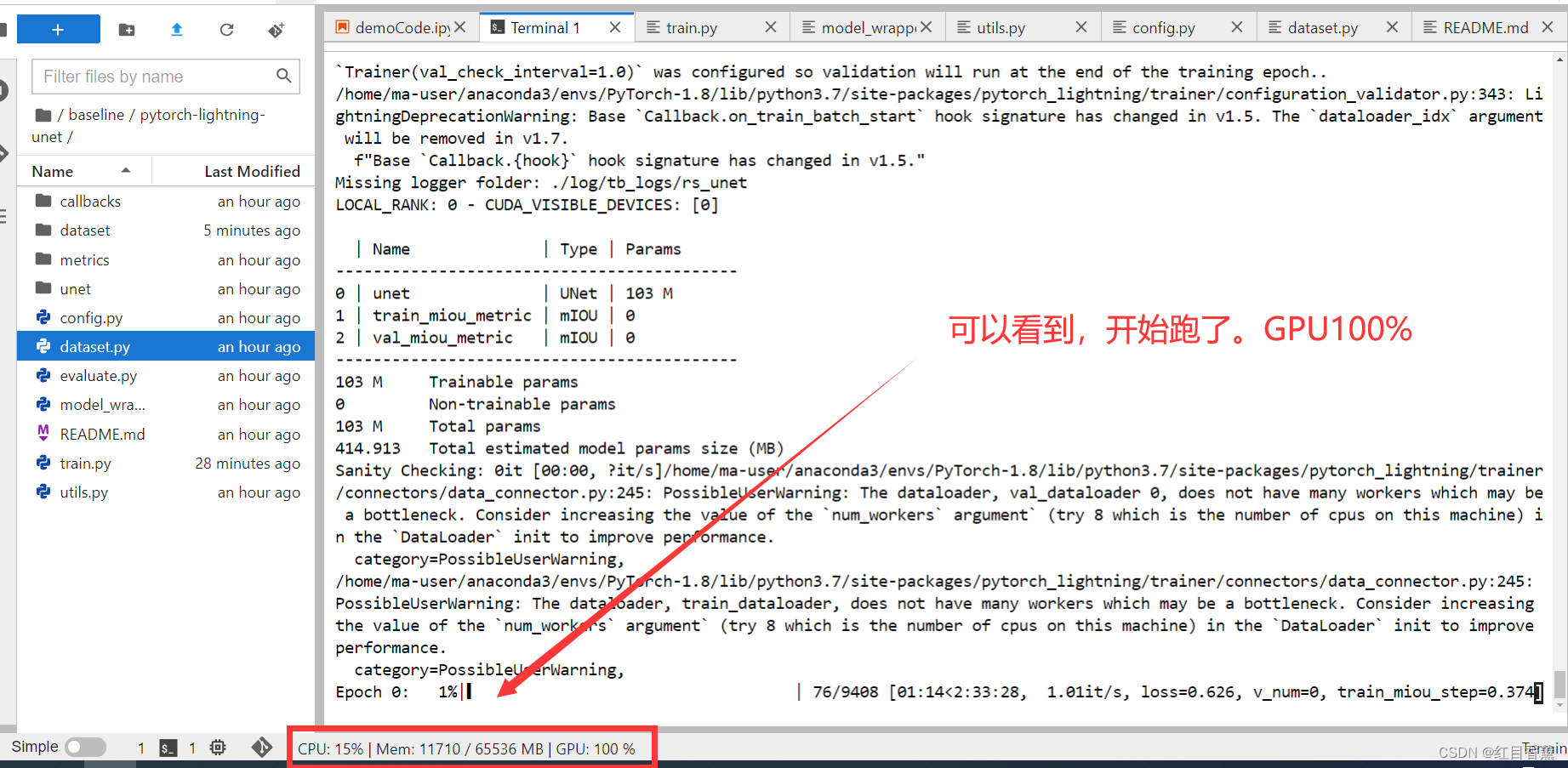
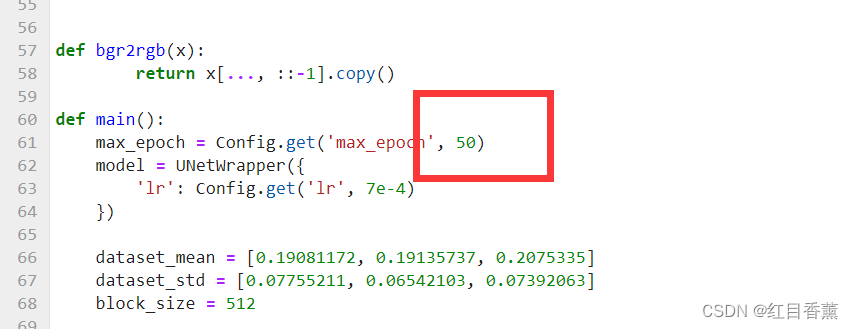
由于max是50,预计时间70小时左右。
-
相关阅读:
大数据之LibrA数据库常见术语(三)
目标检测新SOTA:YOLOv9 问世,新架构让传统卷积重焕生机
【es6】解决箭头函数所有的问题,箭头函数的 this 指针,使用 new 操作符
最新Xcode9 无证书真机调试流程
微软和Red Hat合体:帮助企业更方便部署容器
Mybatis自动映射Java对象 与 MySQL8后的JSON数据
红队隧道应用篇之DNS协议传输(九)
宠物社区风格 商业版(GBK)Discuz模板
关于网络协议的若干问题(一)
生产队有没有驴,我说的算
- 原文地址:https://blog.csdn.net/feng8403000/article/details/126498147