-
容错限流框架之Hystrix下
上一篇博客介绍了Hystrix的一些基本概念以及运行官网提供的demo程序来理解Hystrix工作原理,此篇博客将介绍如何使用spring-cloud-hystrix。Demo地址。在spring cloud中使用Hystrix非常简单,首先在pom.xml文件中引入依赖
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-hystrix</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.cloud</groupId>
- <artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
- </dependency>
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-actuator</artifactId>
- </dependency>
接着在程序入口增加注解(@EnableHystrixDashboard,@EnableCircuitBreaker)
在需要引入Hystrix的服务调用地方地方添加@HystrixCommand即可,除了添加注解外,还可以配置Hystrix相关的参数,具体配置如下图所示:

在student服务中,模拟了1/3概率的超时错误,所以在通过school-service调用student-service时会出现一定概率的超时错误,school-service进入降级处理逻辑中,即执行fall-back中封装的逻辑。下面的student服务中封装了超时错误的逻辑。
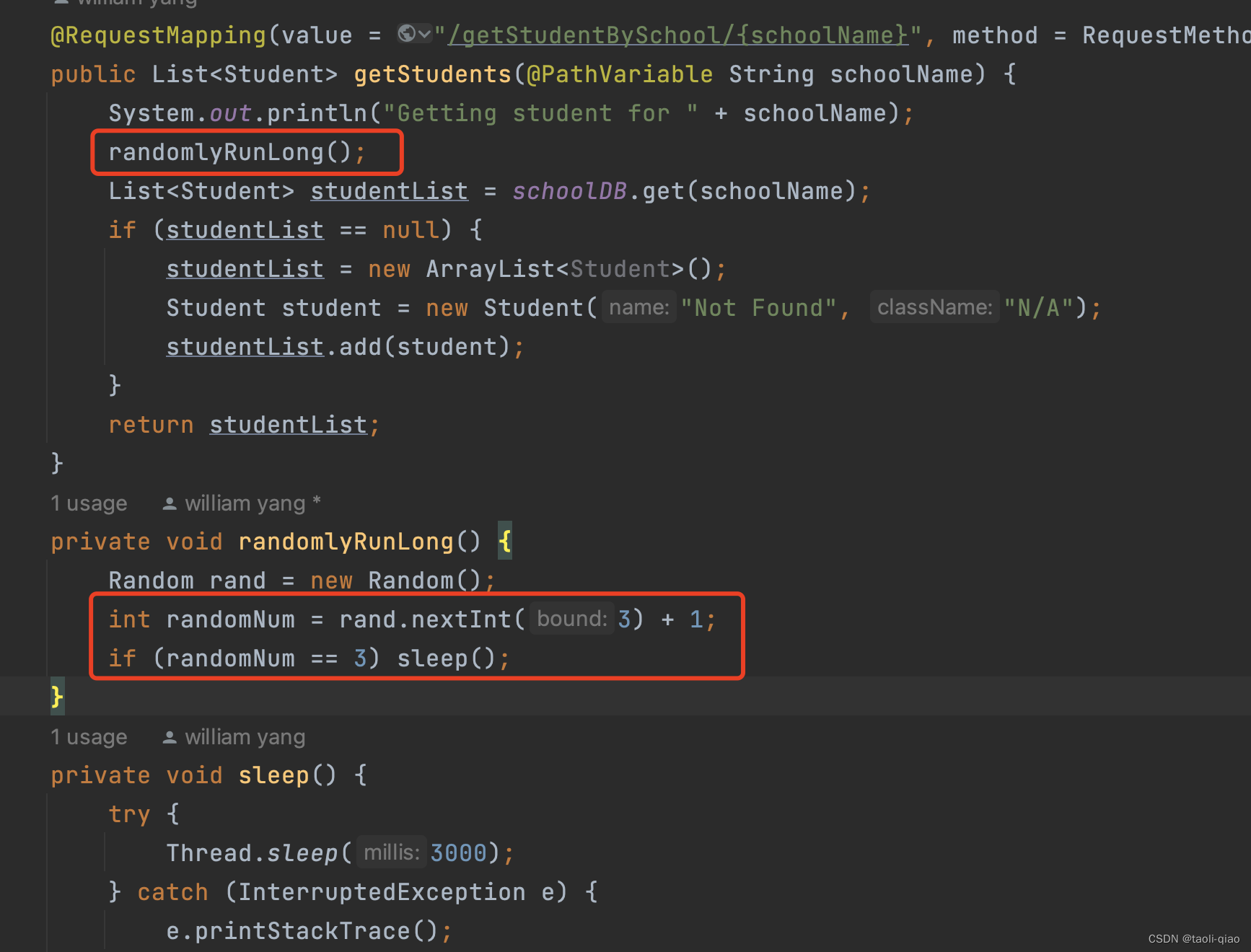
school-service中封装了fall-back逻辑。
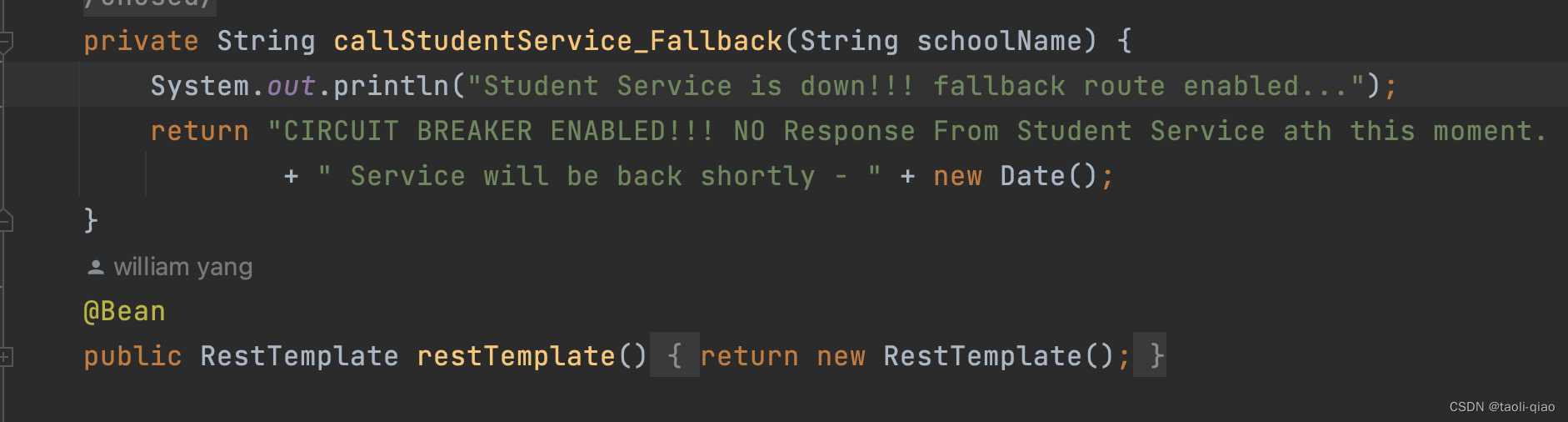
通过postman访问school-service的接口,http://localhost:8088/getSchoolDetails/abcschool ,可以看到失败时打印的是fall-back中封装的信息,说明服务降级处理成功。
 Dashboard添加stream: "http://localhost:8088/hystrix.stream",添加后访问school-service的接口,dashboard上会显示收集到的metrics信息。
Dashboard添加stream: "http://localhost:8088/hystrix.stream",添加后访问school-service的接口,dashboard上会显示收集到的metrics信息。
上面介绍了在spring cloud中如何使用Hystrix进行降级处理,在实际项目中,网关是非常重要的组件之一,往往会在网关上引入Hystrix来做限流降级处理,防止发生雪崩效应。如下图所示在网关上引入hystrix,通过Turbine做数据整合,将收集的多个服务的metrics数据整合显示在Dashboard上。apollo作为配置管理工具,可以把一些关键配置存放在apollo,这样可以做动态切换。另外,引入Eureka做服务注册发现。

接下来看看网关和Hystrix整合的小例子,这个例子中使用的是spring cloud gateway,Demo地址。Demo中包含Hystrix-Dashboard和gateway两部分代码,启动Hystrix-Dashboard,在stream中输入启动的gateway服务的stream(http://localhost:8080/actuator/hystrix.stream),注意,因为这里采用的spring boot版本较老,所以url中有actuator,如果是较新版本的spring boot,那么stream地址就是服务地址+/hystrix.stream.
添加stream后,启动gateway服务,并访问gateway上封装的一些接口,Dashboard上就能看到相关的metrics信息了。
- http://localhost:8080/all - Countries Service
- http://localhost:8080/v1/joke - Joke Service
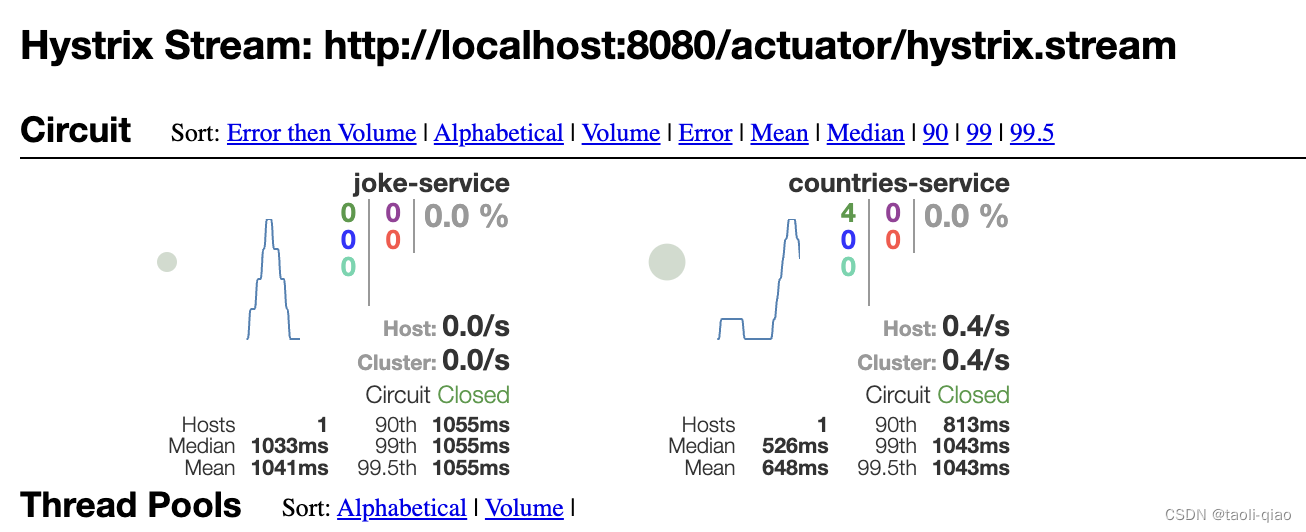
上面展示了Hystrix和网关集成的效果,接下来看看网关上是如何集成的。首先在pom.xml中引入Hystrix依赖,接着在application.yaml文件中配置Hystrix的一些参数设置。最后是网关路由配置,在路由配置部分自定义fallback处理逻辑等,具体代码如下所示:

以上就是网关和Hystrix集成的一个简单例子,实际项目中可以在网关集中埋点,覆盖大部分场景。可以对接Appolo,这样可以动态调整关键配置的值。对于采用信号量隔离还是线程池隔离,可以沿用如下原则:
信号量:主要用于网关、缓存类场景。
线程池:主要用户服务见调用,数据库访问,第三方服务访问
另外,线程池大小设置经验值,官网也给出了计算建议。线程数量设置可以根据期望的TPS来计算,例如假设TPS是30,每个请求的响应时间是0.3second,那么再加一些buffer,来得到最终的线程数量值:
30rps * 0.2 sec = 6 + breathing room = 10 threads
Thread-pool Queue size: 5-10在部署方面,可结合Eureka做服务注册和发现,Turbine做数据整合,统一在Dashboard中显示,如下图所示:

以上就是对Hystrix的学习和理解。
-
相关阅读:
linux网络编程epoll详解
10分钟了解数据架构、数据模型
java异常 | 处理规范、全局异常、Error处理
极客时间之浏览器工作原理与实践笔记
PHP基础学习第七篇五中元素的CSS样式(背景、文本、字体、链接、表格)
Java面试必考题之线程的生命周期,结合源码,透彻讲解!
客服都喜欢的快捷回复软件
java计算机毕业设计社区生鲜电商平台源码+系统+数据库+lw文档+mybatis+运行部署
R语言地理加权回归、主成份分析、判别分析等空间异质性数据分析
LeetCode.565. 数组嵌套____暴力dfs->剪枝dfs->原地修改
- 原文地址:https://blog.csdn.net/qiaotl/article/details/126728281