通常,我们谈的高斯模糊,都知道其是可以行列分离的算法,现在也有着各种优化算法实现,而且其速度基本是和参数大小无关的。但是,在我们实际的应用中,我们可能会发现,有至少50%以上的场景中,我们并不需要大半径的高斯,反而是微小半径的模糊更有用武之地(比如Canny的预处理、简单去噪等),因此,小半径的高斯是否能进一步加速就值的研究,正因为如此,一些商业软件都提供了类似的功能,比如在halon中,直接的高斯模糊可以用smooth_image实现,但是你在其帮助文档中搜索gauss关键字后,你会发现有以下两个函数:
gauss_filter — Smooth using discrete gauss functions.
gauss_image — Smooth an image using discrete Gaussian functions.
两个函数的功能描述基本是一个意思,但是在gauss_image函数的注释下有这么一条:
gauss_image is obsolete and is only provided for reasons of backward compatibility. New applications should use the operator gauss_filter instead.
即这个函数已经过时,提供他只是为了向前兼容,新的应用建议使用gauss_filter 函数,那我们再来看下halcon中其具体的描述:
Signature
gauss_filter(Image : ImageGauss : Size : )
Description
The operator gauss_filter smoothes images using the discrete Gaussian, a discrete approximation of the Gaussian function,

The smoothing effect increases with increasing filter size. The following filter sizes (Size) are supported (the sigma value of the gauss function is indicated in brackets):
3 (0.600)
5 (1.075)
7 (1.550)
9 (2.025)
11 (2.550)
For border treatment the gray values of the images are reflected at the image borders. Notice that, contrary to the operator gauss_image, the relationship between the filter mask size and its respective value for the sigma parameter is linear.
可见gauss_filter的Size只能取3、5、7、9、11这五个值,括号里给出了对应的sigma值。
这种小半径的模糊的优化其实在我博客里有讲过好几个这方面的。但是前面讲述的基本都是直径不超过5,半径不大于2的,比如这里的3和5就可以直接用那种方法处理。
我们先来看看这个权重怎么计算:
简单的例子,比如Size=3时,其实就是一个3*3的卷积,这个3*3的卷积核可以用下述方式计算出来:

const int Diameter = 3, Radius = 1; float Sum = 0, Delta = 0.600, Weight[Diameter][Diameter]; for (int Y = 0; Y < Diameter; Y++) { for (int X = 0; X < Diameter; X++) { Weight[X][Y] = exp(-((X - Radius) * (X - Radius) + (Y - Radius) * (Y - Radius)) / (2 * Delta * Delta)); Sum += Weight[X][Y]; } } // 0.027682 0.111015 0.027682 // 0.111015 0.445213 0.111015 // 0.027682 0.111015 0.027682 for (int Y = 0; Y < Diameter; Y++) { for (int X = 0; X < Diameter; X++) { Weight[X][Y] /= Sum; } }
注意卷积和要中心对称。
要计算这个3*3的卷积,可以直接用浮点数据计算,很明显,这里我们可以直接硬计算,而无需其他什么优化技巧,但是为了不必要的浮点计算,我们很明显可以把这个卷积核定点话,弄成整数,比如整体乘以16384倍,得到下面的卷积核:
// 454 1819 454 // 1819 7292 1819 // 454 1819 454
这样,就可以直接借助整数的乘法和一个移位来得到最终的结果值。
另外,还有一个特点,就是借助于SIMD执行还可以是实现一次性进行4个整数的计算,如果在厉害一点,还可以使用_mm_madd_epi16这个特别的SIMD指令,一次性实现8位整数的计算,效率大大的提高。
有兴趣的可以找找我以前的博文。
当半径大于3时,在使用直接卷积就带来了一定的性能问题,比如直径为7时,每个点的计算量有49次了,这个时候即使借助于SSE也会发现,其耗时和优化后的任意核的高斯相比已经不具有任何优势了,当半径进一步加大时,反而超过了任何核心的优化效果,这个时候我们就需要使用另外一个特性了,即高斯卷积的行列分离特性。我们以9*9的高斯卷积核为例:
使用类似上面的代码,可以得到这个时候的归一化的高斯卷积核如下:
// 0.000825 0.001936 0.003562 0.005135 0.005801 0.005135 0.003562 0.001936 0.000825 // 0.001936 0.004545 0.008363 0.012056 0.013619 0.012056 0.008363 0.004545 0.001936 // 0.003562 0.008363 0.015386 0.022181 0.025057 0.022181 0.015386 0.008363 0.003562 // 0.005135 0.012056 0.022181 0.031977 0.036124 0.031977 0.022181 0.012056 0.005135 // 0.005801 0.013619 0.025057 0.036124 0.040809 0.036124 0.025057 0.013619 0.005801 // 0.005135 0.012056 0.022181 0.031977 0.036124 0.031977 0.022181 0.012056 0.005135 // 0.003562 0.008363 0.015386 0.022181 0.025057 0.022181 0.015386 0.008363 0.003562 // 0.001936 0.004545 0.008363 0.012056 0.013619 0.012056 0.008363 0.004545 0.001936 // 0.000825 0.001936 0.003562 0.005135 0.005801 0.005135 0.003562 0.001936 0.000825
我们看到这个卷积核其转置后的结果和原型一模一样,这样的卷积核就具有行列可分离性,我们要得到其可分离的卷积列向量或者行列量,可以通过归一化其第一行或者第一列的得到,比如将上述核心第一行归一化后得到:
0.028714 0.067419 0.124039 0.178822 0.202011 0.178822 0.124039 0.067419 0.028714
用matlab验证下:
>> a=[0.028714 0.067419 0.124039 0.178822 0.202011 0.178822 0.124039 0.067419 0.028714] a = 0.0287 0.0674 0.1240 0.1788 0.2020 0.1788 0.1240 0.0674 0.0287 >> a'*a ans = 0.0008 0.0019 0.0036 0.0051 0.0058 0.0051 0.0036 0.0019 0.0008 0.0019 0.0045 0.0084 0.0121 0.0136 0.0121 0.0084 0.0045 0.0019 0.0036 0.0084 0.0154 0.0222 0.0251 0.0222 0.0154 0.0084 0.0036 0.0051 0.0121 0.0222 0.0320 0.0361 0.0320 0.0222 0.0121 0.0051 0.0058 0.0136 0.0251 0.0361 0.0408 0.0361 0.0251 0.0136 0.0058 0.0051 0.0121 0.0222 0.0320 0.0361 0.0320 0.0222 0.0121 0.0051 0.0036 0.0084 0.0154 0.0222 0.0251 0.0222 0.0154 0.0084 0.0036 0.0019 0.0045 0.0084 0.0121 0.0136 0.0121 0.0084 0.0045 0.0019 0.0008 0.0019 0.0036 0.0051 0.0058 0.0051 0.0036 0.0019 0.0008
和前面计算的核是一致的。
这个时候的策略就需要改变了,不能直接计算,我们分配一个临时的中国内存,考虑到精度问题,建议中间内存至少使用short类型。我们对原始数据先进行行方向的一维卷积,并取适当的移位数据,将这个中间结果保留在临时的内存中,然后在对临时内存记性列方向的卷积,保存到目标中,考虑到卷积时边缘部分会超出边界,所以还可以使用一个临时扩展的内存,提前把边界位置的内容设计好并填充进去,计算时,就可以连续访问了。
其实这里也有两种选择,即先只计算那些领域不会超出边界的中心像素(使用SIMD优化),然后再用普通的C代码组防边界溢出的普通算法,但是测试发现,这些普通的C代码的耗时占整体的比例有点夸张了,还不如前面的做个临时扩展内存来的快速和方便。
同样的道理,水平和垂直方向的一维卷积也应该用定点化来实现,同样的可借助于_mm_madd_epi16指令。
我们测试了halcon的gauss_filter 的速度,测试代码如下所示:
HalconCpp::HObject hoImage0; HalconCpp::ReadImage(&hoImage0, "D:\\1.bmp"); int max_iter = 100; int multi = 3; timepoint tb; long long tp; static int w[] = { 3, 5, 7, 9, 11, 13, 15, 21, 31, 41, 51 }; static int h[] = { 3, 5, 7, 9, 11, 13, 15, 21, 31, 41, 51 }; HalconCpp::SetSystem("parallelize_operators", "false"); HalconCpp::HObject hoImageT; for (int i = 0; i < 5; i++) { tb = time_now(); for (int k = 0; k < max_iter; ++k) HalconCpp::GaussFilter(hoImage0, &hoImageT, w[i]); tp = time_past(tb); std::cout << "GaussFilter " << w[i] << " use time:" << tp / max_iter/1000 << "ms" << std::endl; }
测试的结果如下:
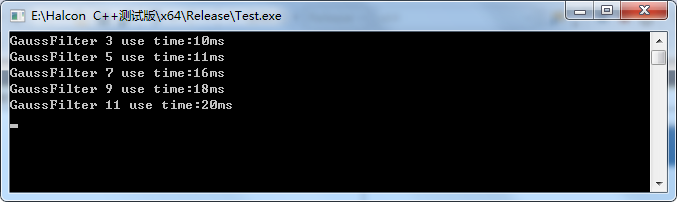
为了测试的公平,我们关闭了halcon的多线程优化方面的功能,即使用了如下的语句:
HalconCpp::SetSystem("parallelize_operators", "false");
我也对我优化后的算法进行了速度测试,主要耗时如下表所示:

和halcon相比,基本在同一个数量级别上。
不过halcon的smooth_image似乎非常的慢,即使我不用其"gauss"参数,同样的图片,其耗时如下所示:
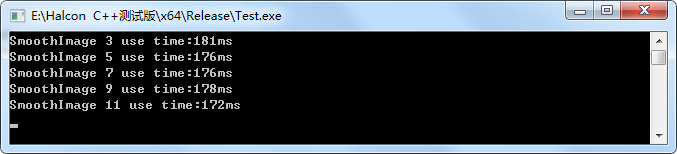
调用代码为:
HalconCpp::SmoothImage(hoImage0, &hoImageT, "deriche1", w[i]);
但是说明一点,smoothimage的deriche1参数耗时和sigma值无关。
最近关于高斯模糊方面的我写了不少文章,都综合在我的SSE优化DEMO里,最近我也把这个DEMO做了更好的分类管理,如下图所示:

有兴趣的朋友可以从:https://files.cnblogs.com/files/Imageshop/SSE_Optimization_Demo.rar?t=1660121429 下载。
如果想时刻关注本人的最新文章,也可关注公众号:
