-
9月6日关键点检测学习笔记——人脸和手部特征点检测
前言
本文为9月6日关键点检测学习笔记——人脸和手部特征点检测,分为五个章节:
- 干扰因素;
- 特征点检测;
- 人脸比对;
- 高清分辨率网络;
- 手部关键点检测。
一、干扰因素
1、主动因素

- 可通过用户简单配合来消除;
- 系统可通过拒绝识别和质量判断来获取高质量图像。
2、固有因素

- 现场很难去除的干扰因素,识别器需对其鲁棒。
二、特征点检测
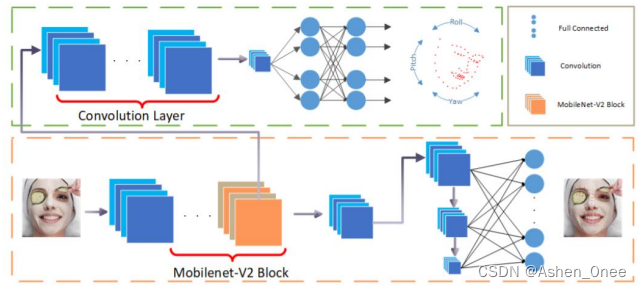
1、PFLD
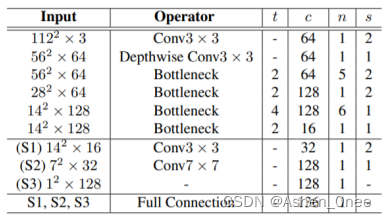
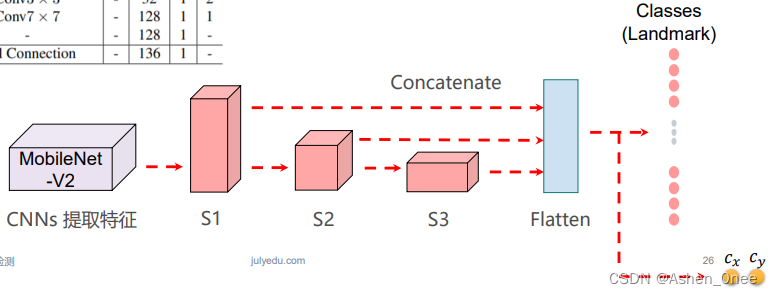
- Loss:
L : = 1 M ∑ m = 1 M ∑ m = 1 N γ n ∣ ∣ d n m ∣ ∣ γ n = ∑ c = 1 C ω n c ∑ k = 1 K ( 1 − c o s θ n k ) ∣ ∣ d n m ∣ ∣ 2 2 \mathcal{L} := \frac{1}{M} \sum_{m=1}^{M} \sum_{m=1}^{N} \gamma_n ||d_n^m||\\ \gamma_n = \sum_{c=1}^{C} \omega _n^c \sum_{k=1}^{K} (1 - cos\theta_n^k) ||d_n^m||_2^2 L:=M1m=1∑Mm=1∑Nγn∣∣dnm∣∣γn=c=1∑Cωnck=1∑K(1−cosθnk)∣∣dnm∣∣22
其中, ∣ ∣ d n m ∣ ∣ ||d_n^m|| ∣∣dnm∣∣ 是第 m个输入的第 n个 landmark 的误差; θ 1 , θ 2 , θ 3 ( K = 3 ) \theta_1, \theta_2, \theta_3\ (K=3) θ1,θ2,θ3 (K=3) 是 GT 值与 estimated yaw, pitch, and roll angles 间的偏向角; C C C 代表 6个类别:侧脸,正脸,抬头,低头,清晰,模糊。
2、LLCV
8000 点人脸关键点技术。
- 单张彩色图像或单段视频作为输入;
- 支持全方位姿态、各种极端表情。
三、人脸比对
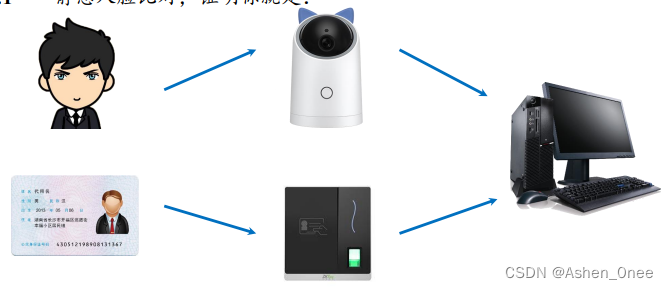
1、人脸 1:1
将一张人脸照片与人脸库中的多张人脸逐一比对,将所有人脸全部比对一次。
2、人脸 1:n
- 静态大库检索,找相似。
- 图片检索,进行N次(亿级)人脸比对,并留下比分大于阈值的结果。

3、人脸 1:N
4、人脸 M:N
- 不同人脸库进行比对。
- 相当于是M个人脸1:N相加的结果。

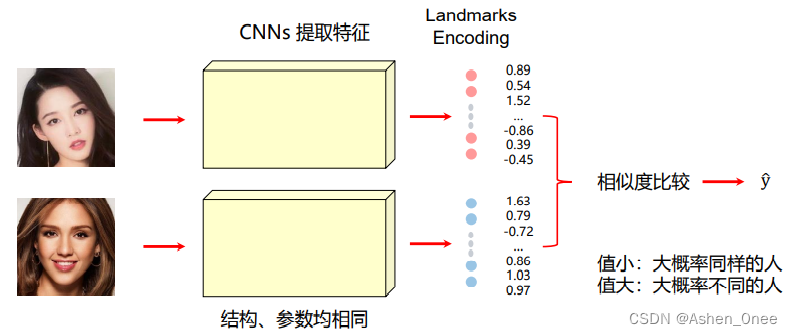
- Siamese Network:
四、高清分辨率网络
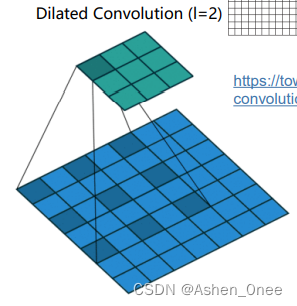
- Dilated convolution 空洞卷积:
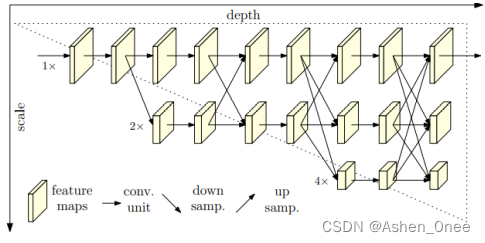
1、HRNet
- 并行的高分辨率 ⇒ 低分辨率网络;
- 多尺度融合。
train.py 代码如下:import os import pprint import argparse import torch import torch.nn as nn import torch.optim as optim import torch.backends.cudnn as cudnn from tensorboardX import SummaryWriter from torch.utils.data import DataLoader import sys sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..')) import lib.models as models from lib.config import config, update_config from lib.datasets import get_dataset from lib.core import function from lib.utils import utils def parse_args(): parser = argparse.ArgumentParser(description='Train Face Alignment') parser.add_argument('--cfg', help='experiment configuration filename', required=True, type=str) args = parser.parse_args() update_config(config, args) return args def main(): args = parse_args() logger, final_output_dir, tb_log_dir = \ utils.create_logger(config, args.cfg, 'train') logger.info(pprint.pformat(args)) logger.info(pprint.pformat(config)) cudnn.benchmark = config.CUDNN.BENCHMARK cudnn.determinstic = config.CUDNN.DETERMINISTIC cudnn.enabled = config.CUDNN.ENABLED model = models.get_face_alignment_net(config) # copy model files writer_dict = { 'writer': SummaryWriter(log_dir=tb_log_dir), 'train_global_steps': 0, 'valid_global_steps': 0, } gpus = list(config.GPUS) model = nn.DataParallel(model, device_ids=gpus).cuda() # loss criterion = torch.nn.MSELoss(size_average=True).cuda() optimizer = utils.get_optimizer(config, model) best_nme = 100 last_epoch = config.TRAIN.BEGIN_EPOCH if config.TRAIN.RESUME: model_state_file = os.path.join(final_output_dir, 'latest.pth') if os.path.islink(model_state_file): checkpoint = torch.load(model_state_file) last_epoch = checkpoint['epoch'] best_nme = checkpoint['best_nme'] model.load_state_dict(checkpoint['state_dict']) optimizer.load_state_dict(checkpoint['optimizer']) print("=> loaded checkpoint (epoch {})" .format(checkpoint['epoch'])) else: print("=> no checkpoint found") if isinstance(config.TRAIN.LR_STEP, list): lr_scheduler = torch.optim.lr_scheduler.MultiStepLR( optimizer, config.TRAIN.LR_STEP, config.TRAIN.LR_FACTOR, last_epoch-1 ) else: lr_scheduler = torch.optim.lr_scheduler.StepLR( optimizer, config.TRAIN.LR_STEP, config.TRAIN.LR_FACTOR, last_epoch-1 ) dataset_type = get_dataset(config) train_loader = DataLoader( dataset=dataset_type(config, is_train=True), batch_size=config.TRAIN.BATCH_SIZE_PER_GPU*len(gpus), shuffle=config.TRAIN.SHUFFLE, num_workers=config.WORKERS, pin_memory=config.PIN_MEMORY) val_loader = DataLoader( dataset=dataset_type(config, is_train=False), batch_size=config.TEST.BATCH_SIZE_PER_GPU*len(gpus), shuffle=False, num_workers=config.WORKERS, pin_memory=config.PIN_MEMORY ) for epoch in range(last_epoch, config.TRAIN.END_EPOCH): lr_scheduler.step() function.train(config, train_loader, model, criterion, optimizer, epoch, writer_dict) # evaluate nme, predictions = function.validate(config, val_loader, model, criterion, epoch, writer_dict) is_best = nme < best_nme best_nme = min(nme, best_nme) logger.info('=> saving checkpoint to {}'.format(final_output_dir)) print("best:", is_best) utils.save_checkpoint( {"state_dict": model, "epoch": epoch + 1, "best_nme": best_nme, "optimizer": optimizer.state_dict(), }, predictions, is_best, final_output_dir, 'checkpoint_{}.pth'.format(epoch)) final_model_state_file = os.path.join(final_output_dir, 'final_state.pth') logger.info('saving final model state to {}'.format( final_model_state_file)) torch.save(model.module.state_dict(), final_model_state_file) writer_dict['writer'].close() if __name__ == '__main__': main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
五、手部关键点检测
1、分类 + 定位问题
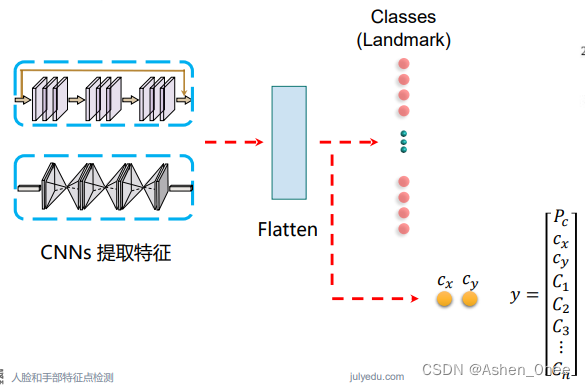
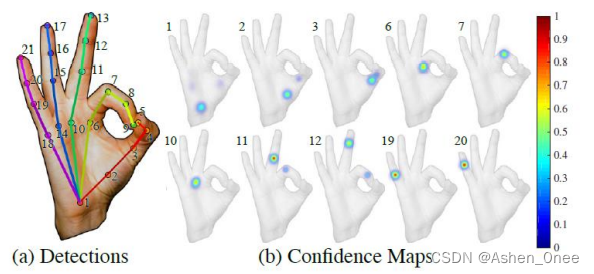
2、2D-3D hand detection
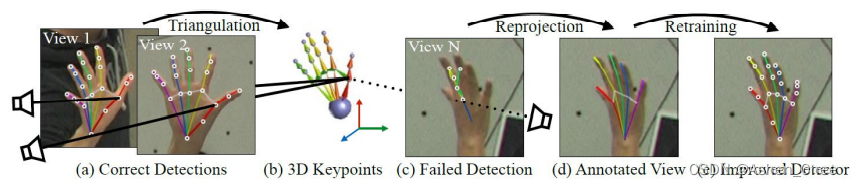
-
相关阅读:
node.js—基于Egg框架的简单后端搭建(包含传参数据库操作)
MySQL update正在执行中突然断电,数据是否更改成功?
ElasticSearchDSL
三、GoLang字符串的基本操作
3、CSS动态时钟
【SpringCloud】微服务技术栈入门3 - Gateway快速上手
秋招春招,网申在线测评中的智力测试
微服务保护——sentinel
mysql基于Python的影院会员管理系统的设计与实现毕业设计源码131621
一起瓜分20万奖金!第三届火焰杯软件测试大赛开始公开选拔!
- 原文地址:https://blog.csdn.net/Ashen_0nee/article/details/126719650
