-
Python统计学09——多元线性回归
参考书目:贾俊平. 统计学——Python实现. 北京: 高等教育出版社,2021.
接上一章的一元线性回归模型,多元线性回归就是多个自变量X。其他都是一样的,求解方法还是最小二乘。
直接来看多元回归的拟合代码。这里的ols() 里面传入的‘y~x1+x2+x3+x4+x5’就是拟合的方程。
- #回归模型的拟合
- from statsmodels.formula.api import ols
- import pandas as pd
- example10_1=pd.read_csv("example10_1.csv",encoding="gbk")
- model = ols('y~x1+x2+x3+x4+x5',data=example10_1).fit()
- print(model.summary())
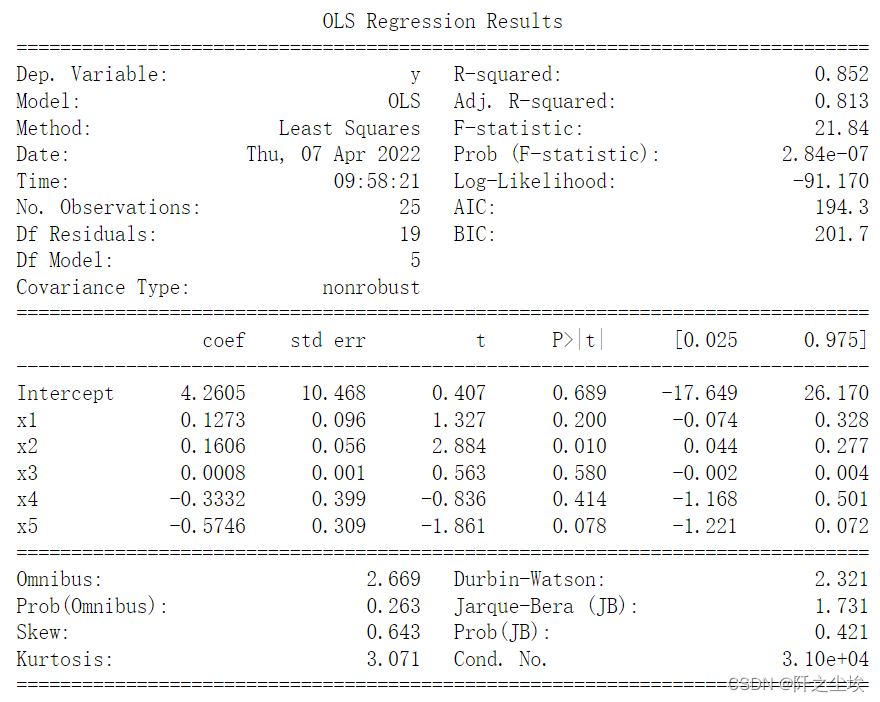
可以看到调整后的拟合优度R2为81.3%,说明y的变动有81.3% 可用这五个x的变动来解释。整体方程的F值为21.84,整体回归显著。再看单个变量的t值和p值,只有x2的p值小于0.05.所以在0.05的显著性水平下,只有X2对y的影响是显著的。其他4个变量不是很显著。
输出方差分析表
- from statsmodels.stats.anova import anova_lm
- anova_lm(model,typ=1)

残差分析
绘制残差图诊断模型
- import matplotlib.pyplot as plt
- import statsmodels.api as sm
- import matplotlib.pyplot as plt
- plt.rcParams ['font.sans-serif'] =['SimHei']
- plt.rcParams['axes.unicode_minus']=False
- #example10_1=pd.read_csv("example10_1.csv",encoding="gbk")
- model=ols('y~x1+x2+x3+x4+x5',data=example10_1).fit()
- x=model.fittedvalues;y=model.resid
- plt.subplots(1,2,figsize=(10,4))
- plt.subplot(121)
- plt.scatter(model.fittedvalues,model.resid)
- plt.xlabel('拟合值')
- plt.ylabel('残差')
- plt.title('(a)残差值与拟合值图',fontsize=15)
- plt.axhline(0,ls='--')
- ax2=plt.subplot(122)
- pplot=sm.ProbPlot(model.resid,fit=True)
- pplot.qqplot(line='r',ax=ax2,xlabel='期望正态值',ylabel='标准化的观测值')
- ax2.set_title('(b)残差正态Q-Q图',fontsize=15)
- plt.show()

整体来看残差没有很偏态,还是比较正态的。
多重共线性
多元回归会可能存在一个问题,就是自变量X们之间的相关性很大,回归模型会存在多重共线性,可能导致求出来的系数存在问题,模型也可能不准确。
我们先计算一下变量之间的相关系数
- #计算相关系数矩阵
- import pandas as pd
- example10_1=pd.read_csv("example10_1.csv",encoding="gbk")
- corr=example10_1.iloc[:,2:].corr()
- corr.style.background_gradient(vmin=0.6,vmax=1)

可以看到X1和X2,X1和X3之间的性关系都很大,模型可能存在多重共线性。
方差膨胀因子
目前主流一般采用方差膨胀因子(VIF)去进行多重共线性的判断,计算方法如下。
- #容忍度和方差扩大因子
- import pandas as pd
- from statsmodels.formula.api import ols
- def vif(df_exog,exog_name):
- exog_use = list(df_exog.columns)
- exog_use.remove(exog_name)
- model=ols(f"{exog_name}~{'+'.join(list(exog_use))}",data=df_exog).fit()
- rsq=model.rsquared
- return 1./(1.-rsq)
- #example10_1=pd.read_csv("example10_1.csv",encoding="gbk")
- df_vif=pd.DataFrame()
- for x in ['x1','x2','x3','x4','x5']:
- vif_i=vif(example10_1.iloc[:,2:],x)
- df_vif.loc['VIF',x]=vif_i
- df_vif.loc['tolerance']=1/df_vif.loc['VIF']
- df_vif
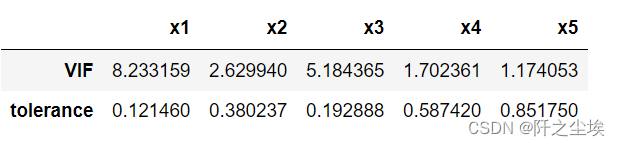
一般方差膨胀因子大于10就存在很严重的多重共线性,这里的五个变量没有大于10,所以把最大的X1和X3扔掉,只用X2,X4 ,X5 再去和y进行回归就行。
当然,还有很多其他方法可以处理,比如向前选择,向后剔除,逐步回归等等,然后比较AIC信息准则。其实都差不多,就是把变量X一个个扔进去试。
利用回归方程预测
model.predict(exog=dict(x1=50,x2=100,x3=50,x4=100,x5=10))上面代码可以计算出当X1=50,X2=100,X3=50,X4=100,X5=10时,y值的预测值。
回归说是数值型变量和数值型变量,但是自变量X还是可以为分类型变量,比如性别男和女,就把男变为0,女性变为1 ,放入回归方程里面就行。如果是三个或者四个更多的分类变量,就再多添加一列。比如第一类用001表示,第二类用010表示,第三类用100表示。
这种方法在经济学里面叫做虚拟变量,在机器学习里面叫哑变量,在计算机科学里面叫做独立热编码。
如果因变量Y是分类型变量,那么再做这种X和Y之间拟合就不叫回归,叫做分类,可以采用逻辑回归进行运算。将Y的值映射为0和1,从而做到分类。还可以使用一系列机器学习的方法,可以参考我之前的文章。
-
相关阅读:
基于3D扫描和3D打印的产品逆向工程实战【数字仪表】
Pytorch - 使用torchsummary/torchsummaryX/torchinfo库打印模型结构、输出维度和参数信息
阿里云r7服务器内存型CPU采用
[新增EA028高压注射器]24套UML+EA和StarUML的建模示范视频-全程字幕(2022.7.4更新)
Matlab信号处理:FFT频谱分辨率
2024年5月系统架构设计师综合知识真题
数据可视化:四种关系图数据可视化的效果对比!
m低信噪比下GPS信号的捕获算法研究,使用matlab算法进行仿真
2022-2028全球前列腺癌诊断和治疗行业调研及趋势分析报告
uni-app的支付与打包上传
- 原文地址:https://blog.csdn.net/weixin_46277779/article/details/126717895
