-
Python每日一练(牛客数据分析篇新题库)——第30天:逻辑运算
1. 正则查找网址
描述: 牛牛最近正在研究网址,他发现好像很多网址的开头都是’https://www’,他想知道任意一个网址都是这样开头吗。于是牛牛向你输入一个网址(字符串形式),你能使用正则函数re.match在起始位置帮他匹配一下有多少位是相同的吗?(区分大小写)
输入描述:输入一行字符串表示网址。
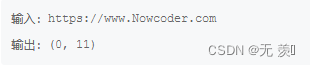
输出描述:输出网址从开头匹配到第一位不匹配的范围。实现代码:
import re str1 = input() result = re.match("https://www", str1, re.I) print(result.span())- 1
- 2
- 3
- 4
运行结果:
2. 提取数字电话
描述: 牛牛翻看以前记录朋友信息的电话薄,电话号码几位数字之间使用-间隔,后面还接了一下不太清楚什么意思的英文字母,你能使用正则匹配re.sub将除了数字以外的其他字符去掉,提取一个全数字电话号码吗?
输入描述:输入一行字符串,字符包括数字、大小写字母和-
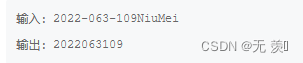
输出描述:输出该字符串提取后的全数字信息。实现代码:
import re #导入模块 p=r'[-A-Za-z]+' #第一个‘-’表示字符‘-’,A-Za-z表示匹配大小字母 #‘+’号表示连续匹配 text=input() #输入测试字符串 print(re.sub(p,'',text)) #利用sub()函数过滤再输出- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果:
3. 截断电话号码
描述: 牛牛记录电话号码时,习惯间隔几位就加一个-间隔,方便记忆,同时他还会在电话后面接多条#引导的注释信息。拨打电话时,-可以被手机正常识别,#引导的注释信息就必须要去掉了,你能使用正则匹配re.match将前面的数字及-信息提取出来吗,去掉后面的注释信息。
输入描述:输入一行字符串,包括数字、大小写字母、#、-及空格。
输出描述:输出提取的仅包含数字和-的电话号码。实现代码:
import re s = input() r = re.match('[0-9-]+',s) print(r.group())- 1
- 2
- 3
- 4
运行结果:

《100天精通Python》专栏推荐白嫖80g Python全栈视频
《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)!
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等

-
相关阅读:
时间序列预测的输入
Allegro怎样标识尺寸?
react 路由的组件说明、路由的执行过程
纯html项目配置babel,报错Uncaught ReferenceError: require is not defined
1281. 整数的各位积和之差
信息学奥赛一本通 1361:产生数(Produce) | 洛谷 P1037 [NOIP2002 普及组] 产生数
Matlab多维数组漫谈教程
ES6中什么是Promise?
iOS自动化测试元素定位
备战数学建模43-决策树&随机森林&Logistic模型(攻坚站7)
- 原文地址:https://blog.csdn.net/yuan2019035055/article/details/126709221