-
Hadoop大数据初入门----haddop伪分布式安装
一.hadoop解决了什么问题
hdfs 解决了海量数据的分布式存储,高可靠,易扩展,高吞吐量
mapreduce 解决了海量数据的分析处理,通用性强,易开发,健壮性yarn 解决了资源管理调度
二.hadoop生态系统
分层次讲解----> 最底层平台 hdfs yarn mapreduce spark
---- > 应用层 hbase hive pig sparkSQL nutch
----> 工具类 zookeeper flume三.版本
Apache: 官方版本
Cloudera :使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
HDP(Hortonworks Data Platform) : Hortonworks公司发行版本。
四、伪分布式安装与配置
1.新建app文件夹(mkdir app)用于存放
2.需要jdk环境,普通用户拥有sudo执行权限,关闭防火墙(service iptables stop)及自启(chkconfig iptables off),修改主机名和IP的映射关系(vim /etc/hosts)

3.上传(hadoop-2.4.1.tar.gz)并解压hadoop包到app文件夹(tar -zxvf hadoop-2.4.1.tar.gz -C app/)
4.可以删除hadoop/share的doc文件夹(文档)节省体积(cd app/hadoop-2.4.1/share/ --> rm -rf doc)
5进入hadoop下的etc目录(cd …/etc/hadoop/)
6.修改(vim hadoop-env.sh)将JAVA_HOME改成固定的(echo $JAVA_HOME命令可以获得javahome路径)

7.修改core-site(vim core-site.xml),在configuration中添加
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
8.修改hdfs-site(vim hdfs-site.xml),在configuration中添加
- 1
- 2
- 3
- 4

9.修改mapred-site名称(mv mapred-site.xml.template mapred-site.xml)
10.修改mapred-site(vim mapred-site.xml),在configuration中添加
- 1
- 2
- 3
- 4
11.修改yarn-site,(vim yarn-site.xml),在configuration中添加
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
12.将hadoop添加到环境变量(目的可以再任意路径下执行hadoop指令)(vim /etc/profile)(对应修改)(修改完成source /etc/profile)
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export HADOOP_HOME=/root/app/hadoop-2.4.1
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: H A D O O P _ H O M E / b i n : HADOOP\_HOME/bin: HADOOP_HOME/bin:HADOOP_HOME/sbin13.格式化namenode(是对namenode进行初始化)(hadoop namenode -format)

五、启动
1.进入sbin目录(cd ~/app/hadoop-2.4.1/sbin/)
_2._启动HDFS(start-dfs.sh)(可以修改 vim ~/app/hadoop-2.4.1/etc/hadoop/slaves 将localhost改为主机名)
3.启动YARN(start-yarn.sh)
4.使用jps命令验证是否启动成功(jps)

5.可以访问http://192.168.25.151:50070 (HDFS管理界面)(可以修改host文件将ip改为对应的linux机器名)
六、配置ssh免登陆
正常多个机器:
(1-3步骤假设为机器1,机器1中想通过 ssh jokerq01 命令直接连接到jokerq01机器而不需要登录密码的)
1.进入到目录(cd ~/.ssh)
2.执行(ssh-keygen -t rsa)命令 (四个回车,执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥))
3.将公钥拷贝到要免登陆的机器上(需要先修改host文件对应的ip与机器名)(例:scp id_rsa.pub jokerq01:/root)
4.(4-6步骤换到要免登录的机器(jokerq01))(cd ~/.ssh)
5.新建authorized_keys文件(touch authorized_keys)并修改权限(chmod 600 authorized_keys)

6.将拷贝的公钥追加到后面(cat …/id_rsa.pub >> ./authorized_keys)
7.在机器1中通过 (ssh jokerq01) 命令直接登录
伪分布式:
1.(cd ~/.ssh)(ssh-keygen -t rsa)
2.直接追加(cat id_rsa.pub >> authorized_keys)
3.自己连接自己不需要密码(ssh jokerq01)

七、HDFS的JAVA客户端编写()
linux:
1.将linux改为图形界面(内存调大)用来运行eclipse(startx)(失败参考https://blog.csdn.net/baidu_19473529/article/details/54235030)
2.安装eclipse
2.1上传压缩包(eclipse-jee-photon-R-linux-gtk.tar.gz),并解压(可以命令,也可以右键Extract Here)
3.运行文件夹的eclipse(图标不适应可以修改图标),并新建java项目(java project)
4.导入jar包(在hadoop-2.4.1sharehadoophdfs下的hadoop-hdfs-2.4.1.jar,还有hadoop-2.4.1sharehadoophdfslib下的所有jar包,hadoop-2.4.1sharehadoopcommon下的hadoop-common-2.4.1.jar,hadoop-2.4.1sharehadoopcommonlib下的所有jar包)
5.编写测试代码
windows:
1.建项目,导jar包,写代码
2.直接JUnit Test报错,运行需要用户名修改为拥有linux文件可操作权限的用户(右键,run as,run configurations,Arguments,添加-DHADOOP_USER_NAME=root)
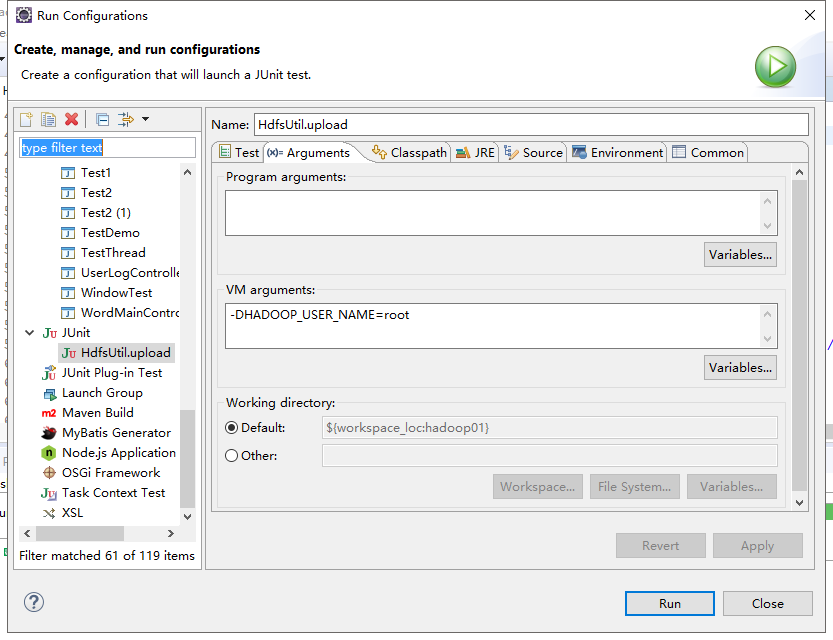
也可以FileSystem.get()方法指定用户
FileSystem fs = null;
@Before
public void init() throws Exception{
//读取classpath下的xxx-site.xml 配置文件,并解析其内容,封装到conf对象中
Configuration conf = new Configuration();
//也可以在代码中对conf中的配置信息进行手动设置,会覆盖掉配置文件中的读取的值
conf.set(“fs.defaultFS”, “hdfs://jokerq01:9000/”);
//根据配置信息,去获取一个具体文件系统的客户端操作实例对象
fs = FileSystem.get(new URI(“hdfs://jokerq01:9000/”),conf,“root”);}- 1
转载于:https://www.cnblogs.com/jokerq/p/9388206.html
l
-
相关阅读:
NASM汇编教程翻译01 第一讲 Hello, World!
数据库级别的审计
手部骨骼跟踪能力,打造控制虚拟世界的手势密码
【FPGA教程案例34】通信案例4——基于FPGA的QPSK调制信号产生,通过matlab测试其星座图
【C++】哈希的应用:位图(bitset)和布隆过滤器(bloomfilter)
UE5中实现沿样条线创建网格体2-SplineMesh版本
视觉SLAM数据集(三):KITTI 数据集
10W 音频功率放大电路芯片TDA2003,可用于汽车收音机及收录机中作音频功率放大器,内部具有短路保护和过热保护等功能
第三章——MySQL数据管理
敏捷开发Scrum Master的职责
- 原文地址:https://blog.csdn.net/m0_67400972/article/details/126717385