-
Java容器之Map
目录
1.之前的综合练习
(1)
 用list。
用list。PS:Math.random()返回的是0-1间的随机浮点数(不包括0-1)。(int)(Math.random()*10+1)可以返回【1,10】之间的整数。


(2)使用set来实现(1)

然后输出一下。
注意!!!这里的输出会出现假排序的现象,

我们明明用的hashset,应该是不会排序,但是这里确确实实给我们排序了,为什么呢?
我们说,hashset底层存放元素是利用hashmap来实现的,hashmap又要会用到hashcode,那么
我们点到Integer的hashcode方法里面:

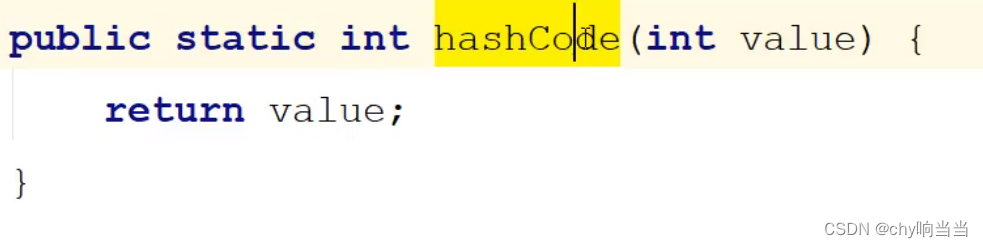
而hashmap初始容量是16(这个16后面再讲),那么按照hashcode()返回的值,再模16,那其实1就是在1,2就是在2,实现了一个假排序。
2.双例集合——Map

 PS:新添加的元素如果key和已有的一样,那么这个元素会替换掉之前已经加入的、和它key一样的元素。
PS:新添加的元素如果key和已有的一样,那么这个元素会替换掉之前已经加入的、和它key一样的元素。3.HashMap

添加元素

但同时如果被覆盖了,还会返回被覆盖的value哦。所以有两个特点:覆盖和返回值。
获取元素方法一:

但是这样子获取不方便,一个要一直写get,一个是我们必须要知道key才能获取。
获取元素方法二:

获取元素方法三:
通过entryset()方法。
首先,Entry是map内部的泛型接口:

内部接口使用,格式是:外部接口.内部接口 Map.Entry

4.Map操作
并集

 abcde是map里面的,f是map2里面的
abcde是map里面的,f是map2里面的那如果map2里面有个(c,cc)那么Putall时,map里面的(c,c)会覆盖掉(c,cc)
删除

判断是否存在

5.HashMap底层分析

 单向链表,然后1.8里面添加hashcode值运算后结果相同的新元素,是添加到链表尾处,而1.7放到链表头。1.8后加了红黑树
单向链表,然后1.8里面添加hashcode值运算后结果相同的新元素,是添加到链表尾处,而1.7放到链表头。1.8后加了红黑树成员变量
PS: alt+7可以查看结构


这里就可看到之前说的,初始容量为16,并且数组长度一定是2的n次幂(英语要学好)

这是最大的容量2的30次方

这是扩容的负载因子,75%,即当数组容量用到75%时,就要扩容了,比如一开始是16,那么到第13个时就要扩容了。

这就是转变为红黑树的数量界限8。
 当数组长度超过64时,才会将长度超过8的链表做树型化处理。
当数组长度超过64时,才会将长度超过8的链表做树型化处理。 这个记录键值对数量
这个记录键值对数量
存放链表和红黑树的数组。
存储元素节点类型
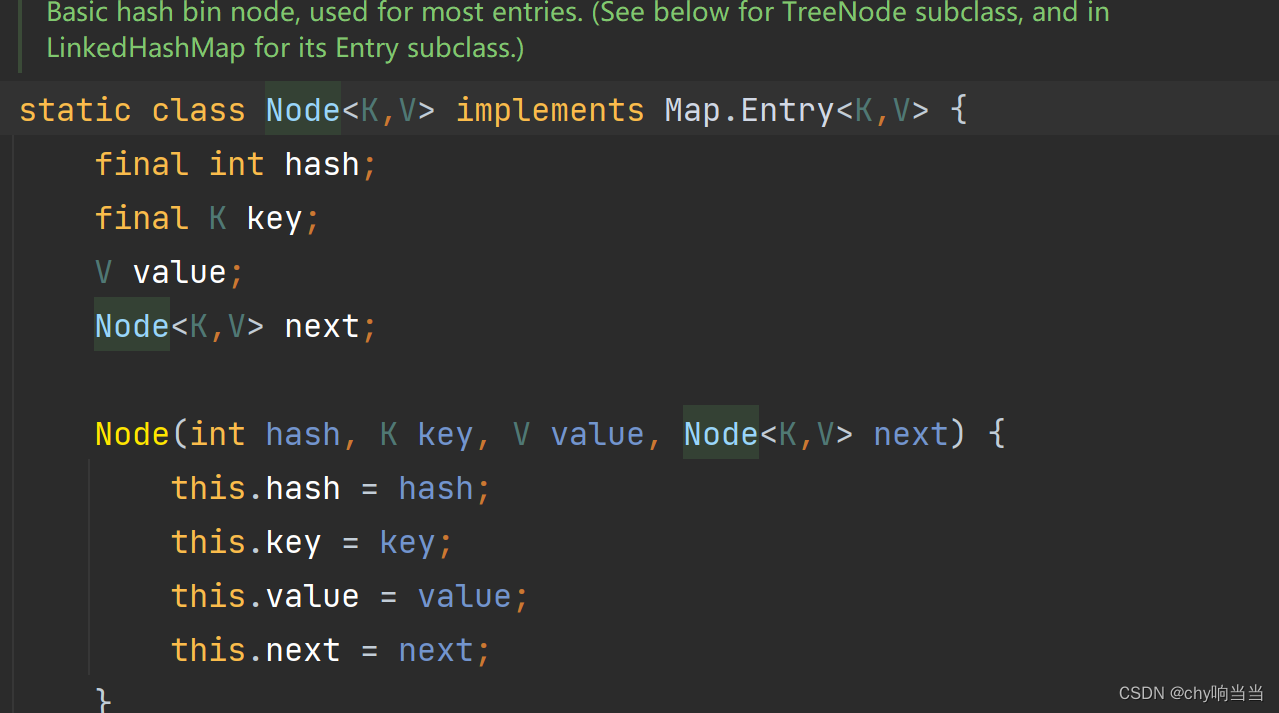
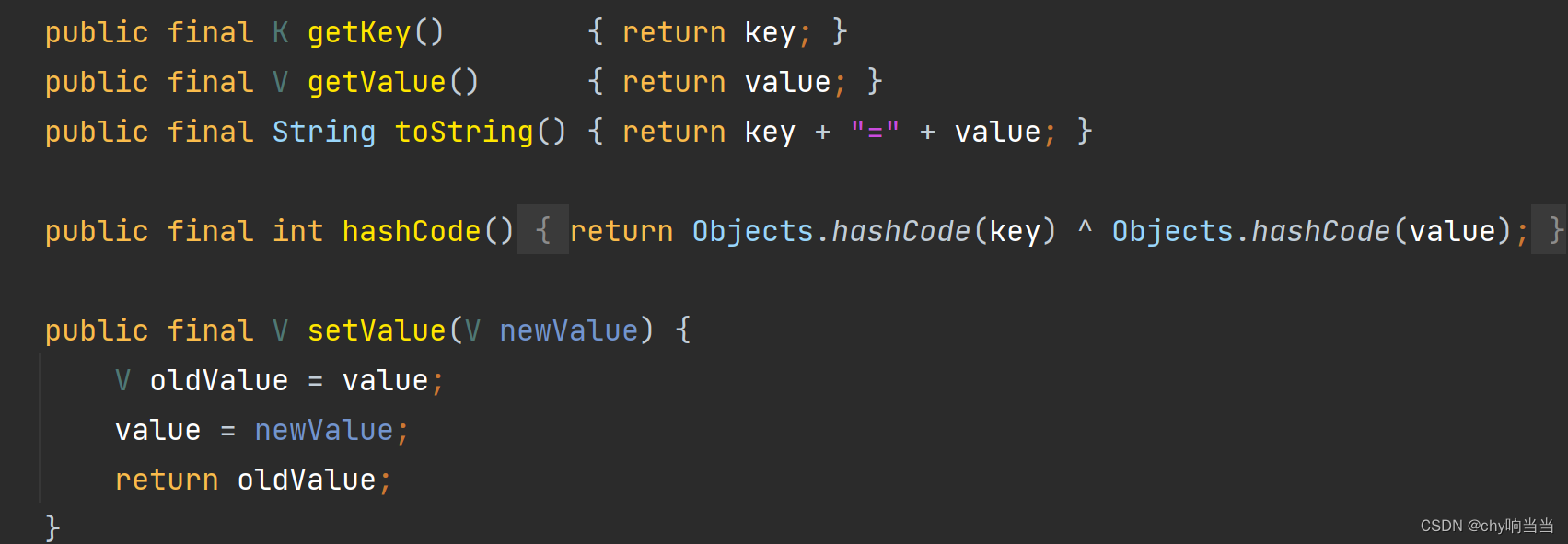
实现了map.entry接口,重写了那个Getkey getvalue
这里回忆之前有个方法
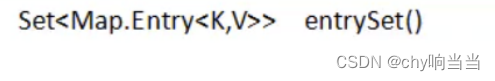 这里的set里面的元素其实就是node,只不过用的是map.entry这个类型,而node实现了map.entry,那当然可以用了。
这里的set里面的元素其实就是node,只不过用的是map.entry这个类型,而node实现了map.entry,那当然可以用了。
treenode是定义红黑树节点的
继承了一个超类,是个内部类:

而我们看到这个linkedhashmap.entry又继承了之前hashmap.node
所以可以得出treenode继承了node这一结论,所以都能放入类型为node的table数组。

而红黑树可能比较难,以后可以慢慢了解具体的
数组初始化



resize()就是完成数组初始化和扩容的,代码长,自己看。
计算Hash值




位运算!!!hash值=hashcode&(数组长度size - 1),而之前我们说除以16只是举例子,cpu做除法那效率也太低了,不可能。
比如上面我们记得put方法里面调用了hash这一个方法:

来看hash这个方法(提醒,hashcode值和hash值是不一样的):

这个式子有一点点难,首先,key==null时,返回0,否则返回:后面那个式子
那么问题来了,后面那个式子是什么呢?这有优先级,我们先算的是一个赋值语句,h=key.hahscode(),也就是把hashcode值给了h,然后是再计算右边括号里的右移16位(注意哦java里面>>>代表无符号右移,>>>16就是把32位整数取了前16位),那么根据我们数电的知识,int二进制计算是32位,那么hashcode值要先补0,
我们举个例子:比如第一个元素的hashcode值的十进制表示是4548489

然后补成32位,右移16位指留下来高位的16位:0000 0000 0000 0000 0000 0000 0100 0101

然后异或,左边是hashcode原值,右边是移动后的:

结果为:

转化为十进制后,结果是4548556。(这可不是hash值,而是在计算hash值之前做的运算处理,之所以要对hashcode值进行处理,就是为了让hash值算出来更散列一些)
然后目光回到putval函数:

这里其实就是在真正计算hash值了,将参数n-1和hash与运算,然后赋给i,然后看数组里面tab[i]是不是非空。
n是length,如果是刚刚开始,n-1=15,与运算:

结果:

12,所以此时这第一个元素会放到数组索引为12的地方。
添加元素
这里我们看putval的代码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node
补充一下instanceof关键字:

数组扩容
之前我们分析Putval时还有个尾巴没说:

modcount就是记录容器改变的次数,然后下面的if用于判断数组是否需要扩容,threshold是一个预期值,这个值是来自于数组长度乘以负载因子(75%)的值。
resize是扩容的:(注意永远都是按二倍来对数组扩容的,也就是2的N次幂)
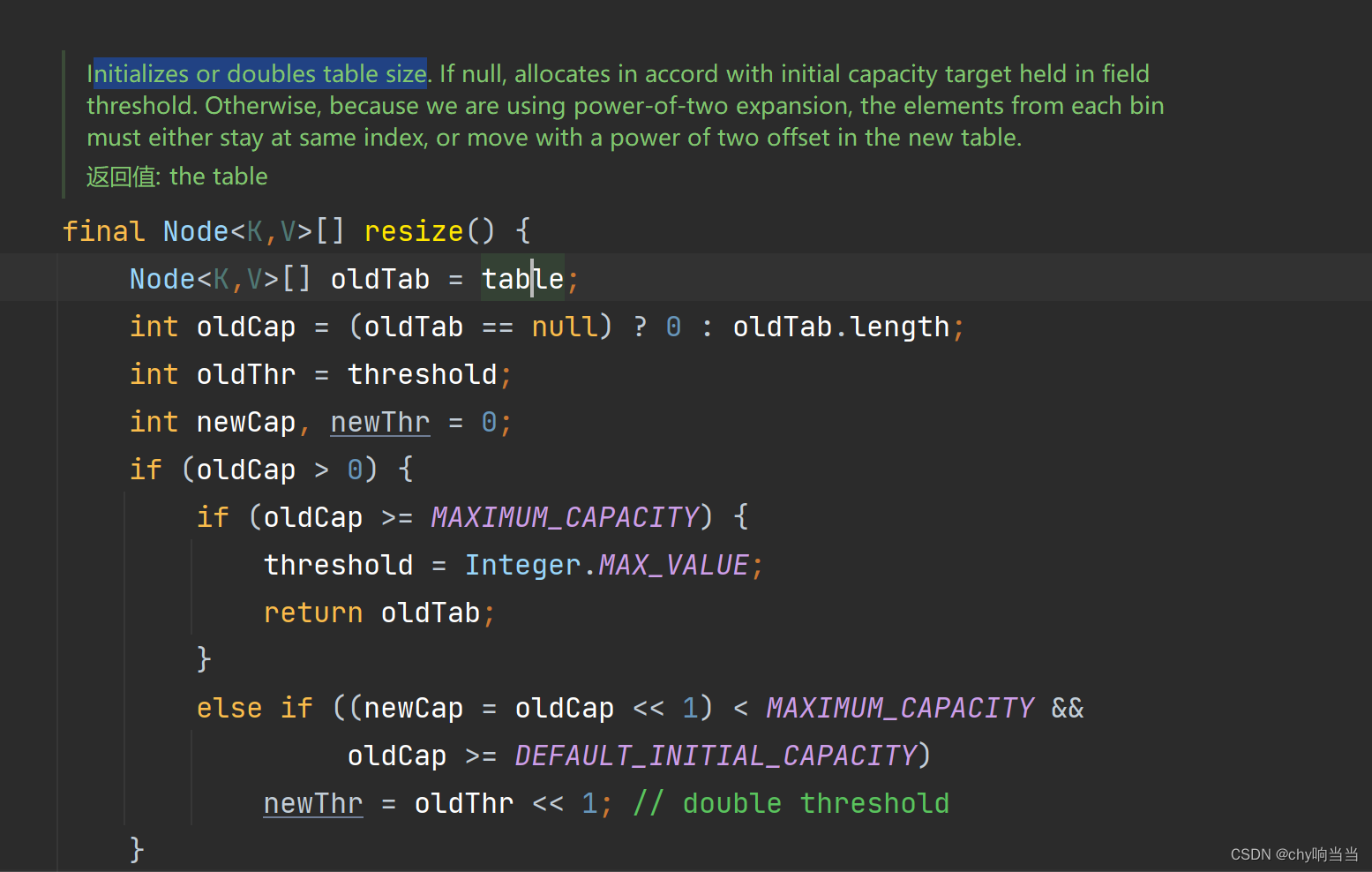
这个函数比较好理解的,自己看一看,锻炼一下。注意,<<1代表的是乘以2,
但是我这里保留一个疑问,希望有会的大佬可以解答:

这里等式右边,new Node的node就是内部类Node
6.TreeMap容器类

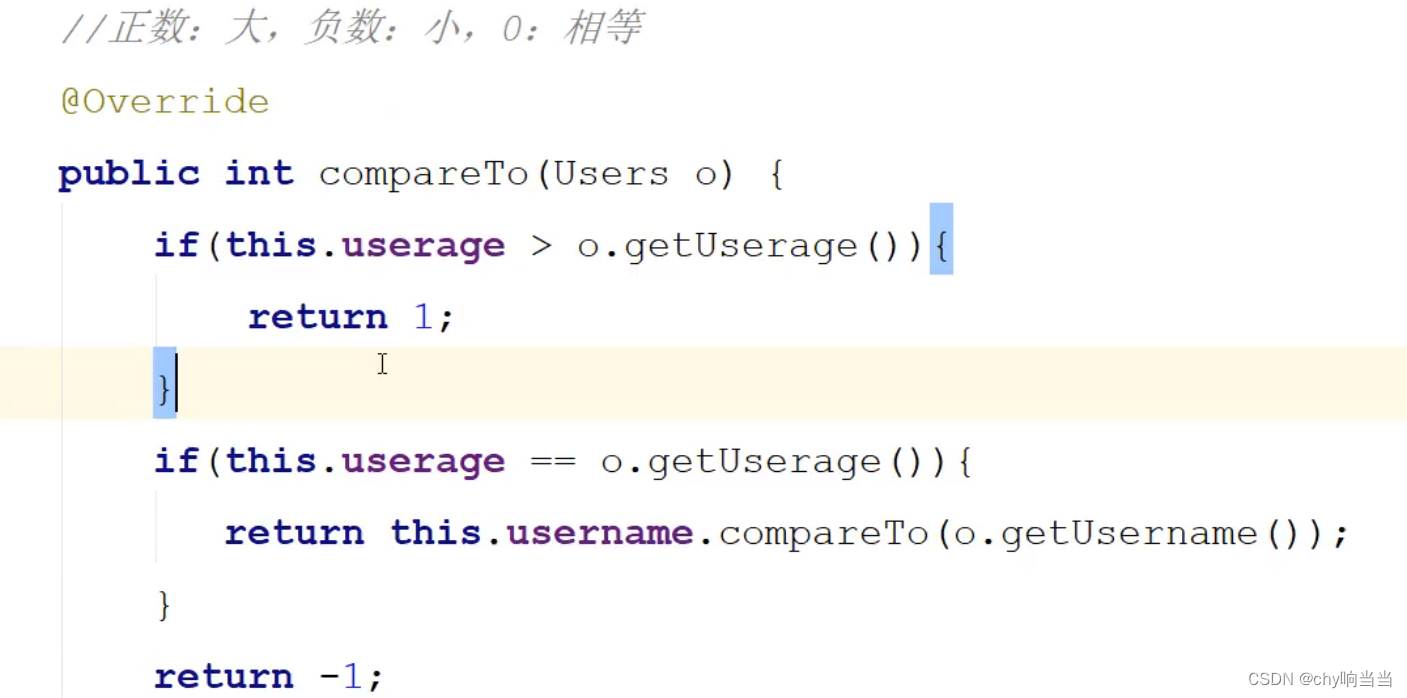
其实那个排序和treeset几乎一样,都演示过了,要注意的是:排序是抽象的从“小”到“大”,所以这个到时候要自己注意一下,和以前c++的cmp差不多。
通过自身排序:


实现接口,进行重写
通过比较器排序

student类里面没有重写compareto,但是我们另外写了一个类也就是比较器

底层用红黑树,用的不多也比较难这里暂时不讲。
-
相关阅读:
RK3399 Android7.1修改安兔兔等读到的Build Fingerprint内容
Spring基础之AOP
WMI使用学习笔记
SparkStreaming的foreachPartition理解
暑期JAVA学习(48)XML检索技术:Xpath
7-39 最优合并问题——优先队列
stm32cubemx hal学习记录:DAC 正弦波
综合应用QGIS软件,实现商场选址分析
linux系统日志
.NET 线程独享的全局数据 TLS
- 原文地址:https://blog.csdn.net/keepstrivingchy/article/details/126686297