-
ArcGIS Pro中的回归分析浅析(加更)关于广义线性回归工具的补充内容
提问:案例里的cals数据貌似离散,更符合泊松模型啊,为啥不采用泊松而采用高斯呢?
确实,在中篇中写道:
在这个例子中我们为了更好地解释变量,使用高斯模型代替更适合的泊松模型。
那么这句话该怎么理解呢?一般情况下,拿到研究数据之后,如果我们计划使用GLR工具,首先需要判断使用哪个模型,使用哪个模型是由数据来确定的,当数据都是整数时,究竟是用高斯还是泊松呢?
我们知道,高斯模型需要满足数据正态分布。在Pro中如何看数据是否正态分布呢?
打开Pro,在内容列表中选择包含因变量的原始图层,选择创建图表,点击直方图就可以查看数据的分布形态了。
在图表属性中选择数值变量为Calls
存在变换三种形式,无变换、对数变换以及平方根变换。默认情况下选择无变换。
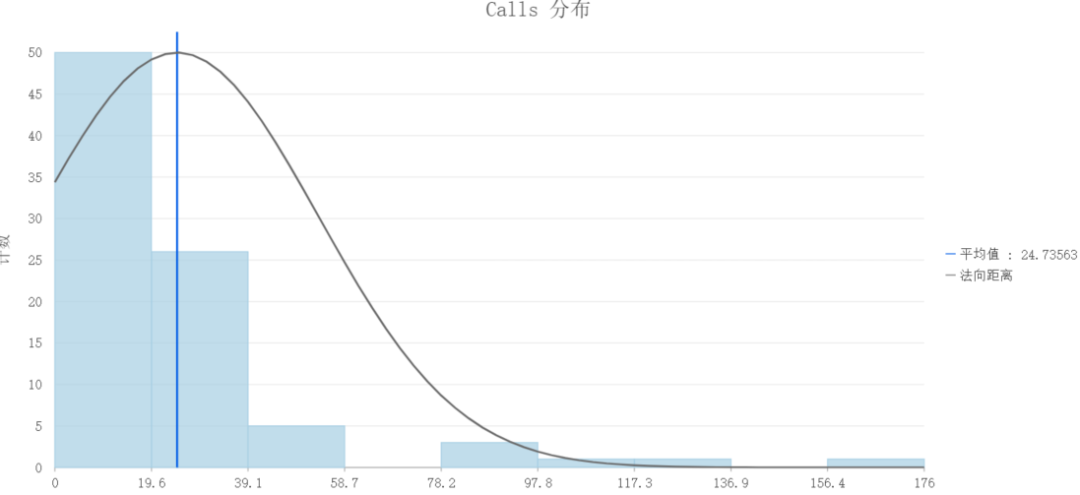
其中横轴是Calls值,纵轴为Calls的数量。
很显然,当前数据是偏斜的,并不是正态分布的。这种情况下是不建议选择高斯模型,更推荐使用泊松的。
但是很多情况下,高斯的性能或者说拟合度都要好于泊松。(大家可以尝试使用本例中的数据,再结合GLR工具中的泊松模型得出该模型的拟合度)
所以为了向高斯模型靠拢,提高模型精度,会尝试将数据进行变换。
你可以理解为在某种程度上,变换可以认为并非在调整数据
-
相关阅读:
Android自定义控件(二) Android下聚光灯实现
使用Python+Flask/Moco框架/Fiddler搭建简单的接口Mock服务
后缀数组复习
wgcna 官网教程II.Consensus analysis of female and male liver expression data
10月第4周榜单丨飞瓜数据B站UP主排行榜(哔哩哔哩平台)发布!
vue下载xlsx表格
什么款式的蓝牙耳机跑步不容易掉?推荐几款很不错的运动耳机
Linux环境变量与程序地址空间
C#中string类型是引用类型
css盒子模型——边框 border
- 原文地址:https://blog.csdn.net/qq_41127811/article/details/126701076