-
图解LeetCode——652. 寻找重复的子树(难度:中等)
一、题目
给定一棵二叉树
root,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
如果两棵树具有相同的结构和相同的结点值,则它们是重复的。
二、示例
2.1> 示例 1:
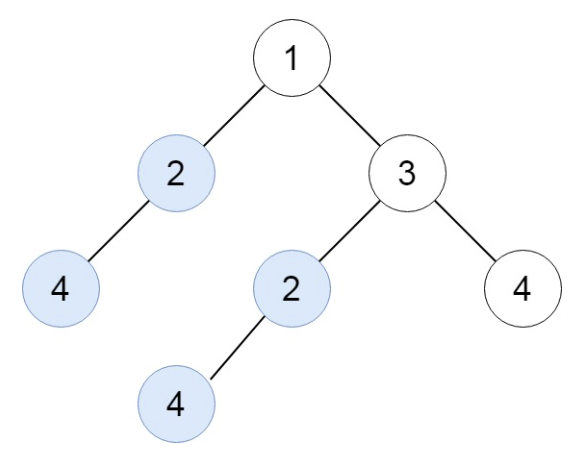
【输入】root = [1,2,3,4,null,2,4,null,null,4]
【输出】[[2,4],[4]]示例 2:
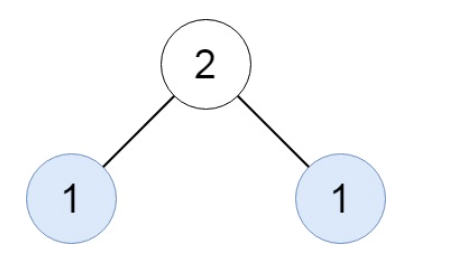
【输入】root = [2,1,1]
【输出】[[1]]示例 3:
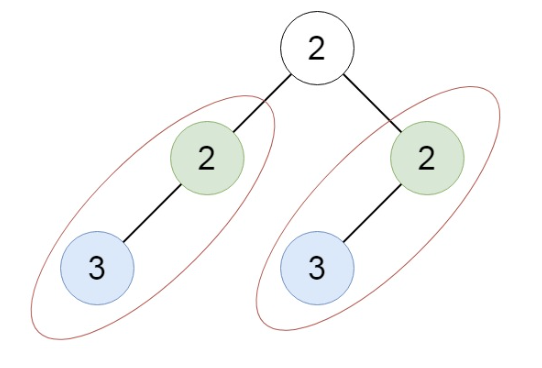
【输入】root = [2,2,2,3,null,3,null]
【输出】[[2,3],[3]]提示:
- 树中的结点数在
[1,10^4]范围内。 -200<= Node.val <=200
三、解题思路
根据题意,我们要找出重复的子树,那么,就需要我们针对给出的树进行遍历,来统计这个树是由哪些子树构成的。所以,基于这种解题思路,我们首先采用深度优先遍历方式,对树中的每个节点进行遍历,每当遍历一个子树的时候,我们就将该子树存储到哈希表中,我们这里采用的是
Map,其中key存储的是前序/后续拼装的树的字符串(每个节点以“/”分割),value存储的是遍历子树过程中,相同子树出现的个数。那么,为了排重,当且仅当出现了第2次的时候,才放入到待返回的变量List中。最终,将result作为结果返回即可。具体操作如下图所示:result 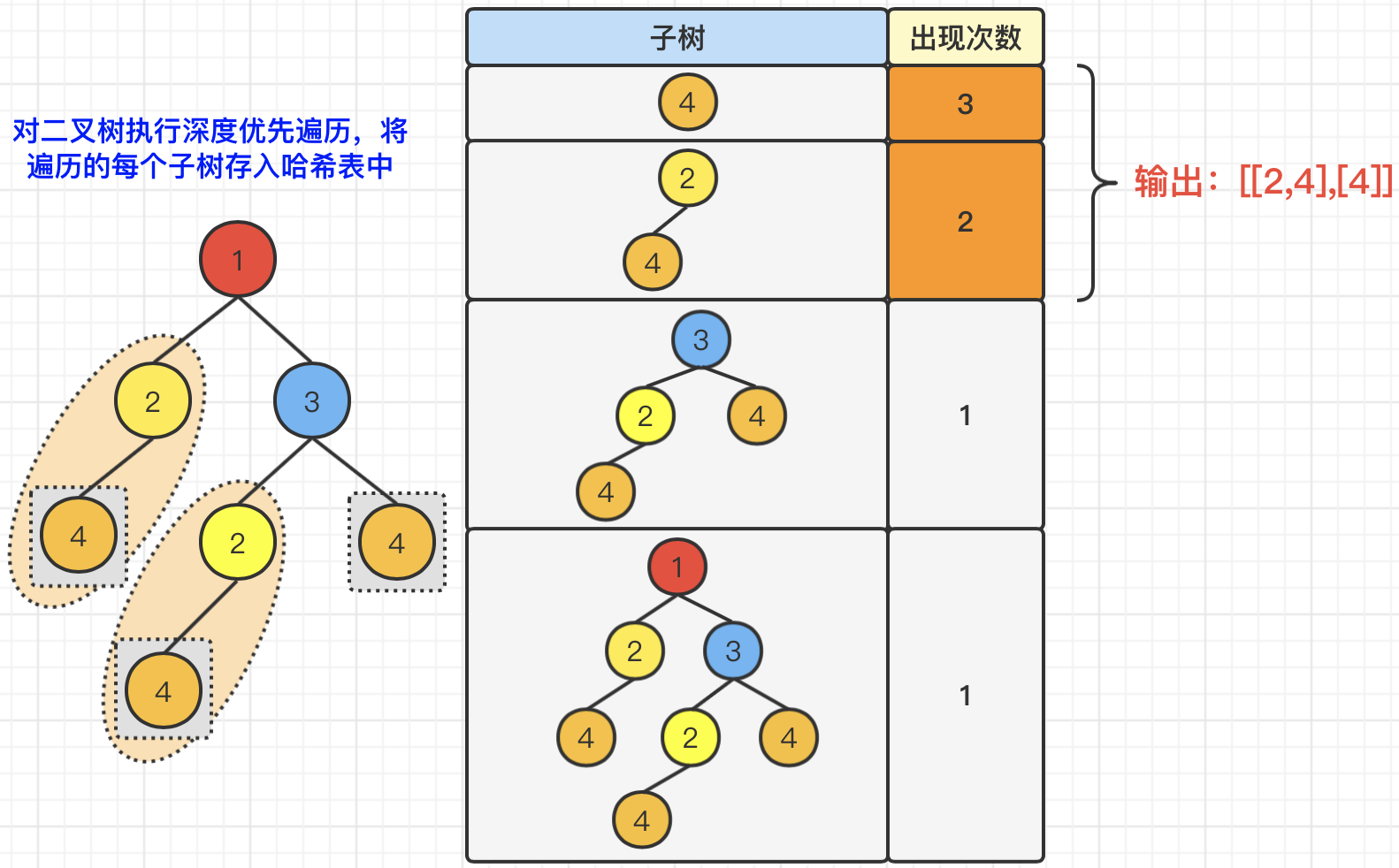
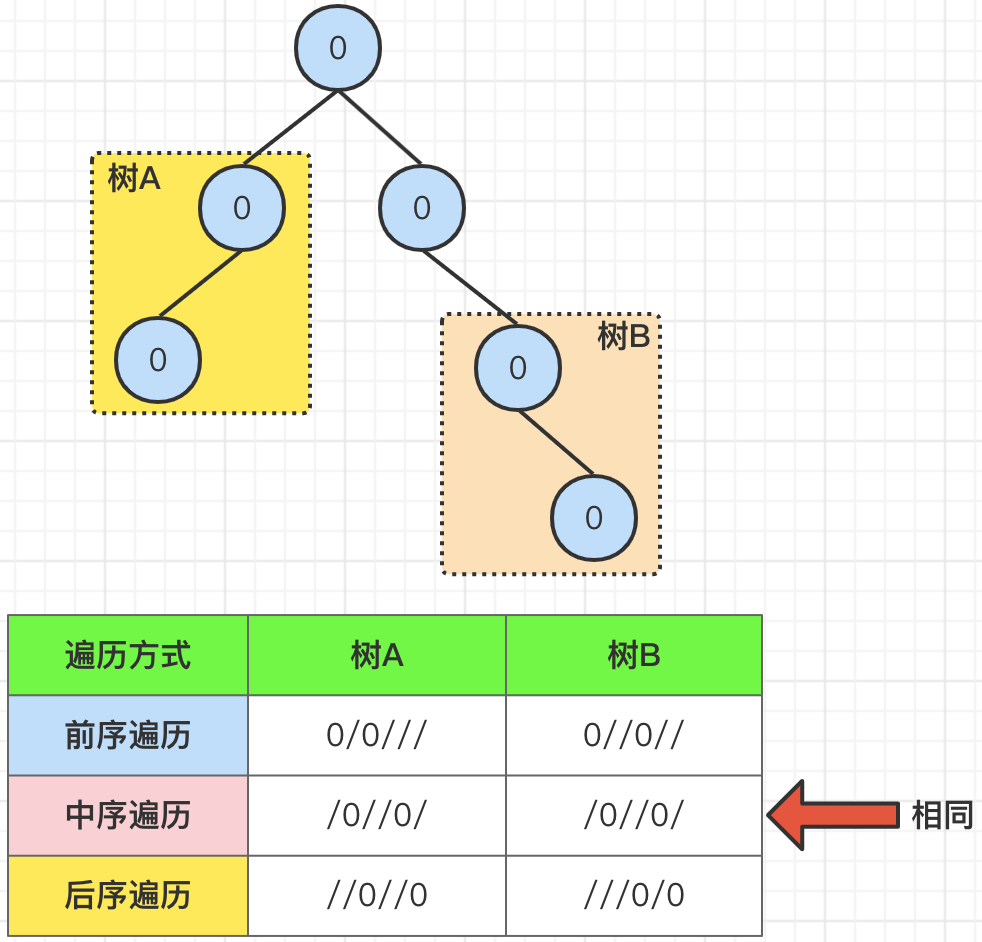
那么,在上面的描述中,我们在将子树转化为字符串的时候,指出可以采用前序或后续遍历,为什么不能采用中序遍历呢?请看下面的图示,当我们采用中序遍历的时候,我们发现,针对树A和树B,转换后的结果(不同节点,我们采用“/”分割)是相同的,但是树A和树B却不是重复的子树。
好了,以上就是基本的解题思路了。具体的代码实现,请参照:代码实现 部分
四、代码实现
- class Solution {
- Map<String, Integer> map = new HashMap();
- List<TreeNode> result = new ArrayList();
- public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
- dfs(root);
- return result;
- }
- public String dfs(TreeNode node) {
- if (node == null) return "";
- String key = new StringBuilder().append(node.val).append(",").append(dfs(node.left)).append(",").append(dfs(node.right)).toString();
- if (map.getOrDefault(key, 0) == 1) result.add(node);
- map.put(key, map.getOrDefault(key, 0) + 1);
- return key;
- }
- }

今天的文章内容就这些了:
写作不易,笔者几个小时甚至数天完成的一篇文章,只愿换来您几秒钟的 点赞 & 分享 。
更多技术干货,欢迎大家关注公众号“爪哇缪斯” ~ \(^o^)/ ~ 「干货分享,每天更新」
- 树中的结点数在
-
相关阅读:
JAVA计算机毕业设计养老机构管理信息系统Mybatis+源码+数据库+lw文档+系统+调试部署
开放实验室管理系统 毕业设计 JAVA+Vue+SpringBoot+MySQL
怎样能更快速的整理软考高项教材的知识考点?
YbtOJ「基础算法」第4章 深度搜索
docker 部署 coredns(内部域名解析)
2021年9月电子学会图形化三级编程题解析含答案:计算平均分
【C++】编程题遇到行数不固定的字符串(以逗号或空格分割)
Python初级笔记6 函数
RK3399平台开发系列讲解(I/O篇)Linux最大文件数的限制机制
c++ vector erase
- 原文地址:https://blog.csdn.net/qq_26470817/article/details/126699136