-
《Linux驱动:块设备的读写流程( ll_rw_block 接口分析)》
一,前言
在内核空间构建了块设备驱动程序,创建了块设备的设备节点,那么用户空间的APP如果通过该设备节点去读写对应的块设备呢?接下来便逐步分析这个过程。分析用户程序是如何一步步读写到块设备的数据的。
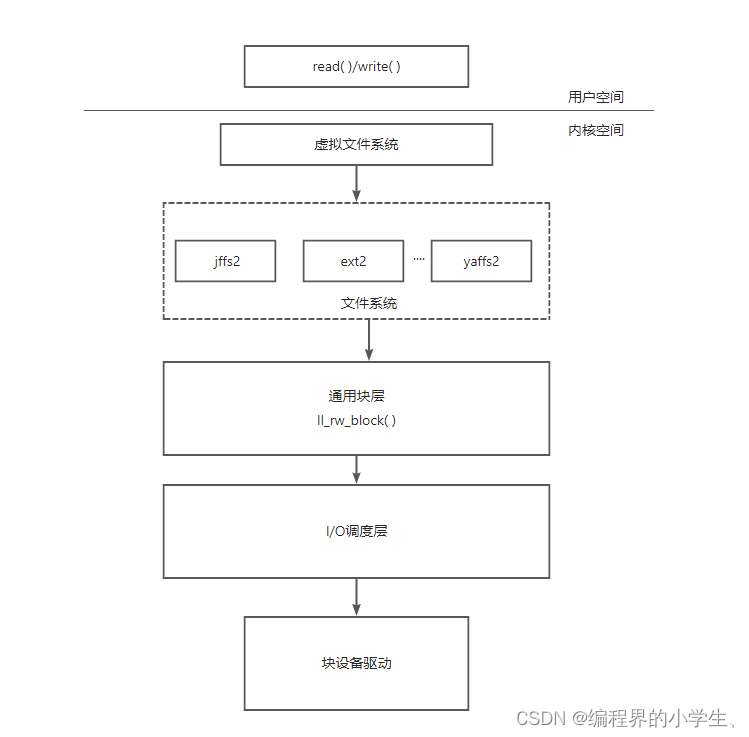
二, 应用层读写到块设备数据框架图
通用块层提供了一个接口ll_rw_block( )用来对逻辑块进行读写操作。应用层对块设备的读写操作都会调用到ll_rw_block( )函数来执行。
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[]);
rw:进行读操作还是写操作,一般可选的值为 READ、WRITE 或者 READA 等;
nr:bhs数组元素个数;
bhs:要进行读写操作的数据块数组;
三,ll_rw_block接口分析
函数原型:
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[]);
在分析ll_rw_block接口前,先看下buffer_head结构体3.1 buffer_head结构体
struct buffer_head { unsigned long b_state; /* buffer state bitmap (see above) */ struct buffer_head *b_this_page;/* circular list of page's buffers */ struct page *b_page; /* the page this bh is mapped to */ sector_t b_blocknr; /* start block number */ // 数据块号 size_t b_size; /* size of mapping */ // 数据块大小 char *b_data; /* pointer to data within the page */ struct block_device *b_bdev; // 数据块所属设备 bh_end_io_t *b_end_io; /* I/O completion */ void *b_private; /* reserved for b_end_io */ struct list_head b_assoc_buffers; /* associated with another mapping */ struct address_space *b_assoc_map; /* mapping this buffer is associated with */ atomic_t b_count; /* users using this buffer_head */ };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.2 ll_rw_block接口实现
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[]) { int i; // 遍历数据块数组,取出每一个数据块 for (i = 0; i < nr; i++) { struct buffer_head *bh = bhs[i]; if (rw == SWRITE) lock_buffer(bh); else if (test_set_buffer_locked(bh)) continue; if (rw == WRITE || rw == SWRITE) { if (test_clear_buffer_dirty(bh)) { bh->b_end_io = end_buffer_write_sync; get_bh(bh); submit_bh(WRITE, bh); // 提交写数据块 continue; } } else { if (!buffer_uptodate(bh)) { bh->b_end_io = end_buffer_read_sync; get_bh(bh); submit_bh(rw, bh); // 提交读数据块 continue; } } unlock_buffer(bh); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
3.3 构建bio、获取设备i/o请求队列
submit_bh(WRITE, bh)/submit_bh(rw, bh) -> bio = bio_alloc(GFP_NOIO, 1); bio->bi_sector = bh->b_blocknr * (bh->b_size >> 9); bio->bi_bdev = bh->b_bdev; bio->bi_io_vec[0].bv_page = bh->b_page; bio->bi_io_vec[0].bv_len = bh->b_size; bio->bi_io_vec[0].bv_offset = bh_offset(bh); bio->bi_vcnt = 1; bio->bi_idx = 0; bio->bi_size = bh->b_size; bio->bi_end_io = end_bio_bh_io_sync; bio->bi_private = bh; bio_get(bio); // 提交bio submit_bio(rw, bio) -> generic_make_request(bio) -> __generic_make_request(bio) -> q = bdev_get_queue(bio->bi_bdev) -> //获取块设备的i/o请求队列 ret = q->make_request_fn(q, bio) -> // // 调用队列的"构造请求函数"处理bio- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.4 队列的"构造请求函数"由来
队列的"构造请求函数"有两个来源,一是,使用默认的函数__make_request;二是,在块设备驱动程序中设置。
3.4.1 默认的__make_request接口
__make_request被设置为队列的"构造请求函数"的过程
blk_init_queue -> blk_init_queue_node -> blk_queue_make_request(q, __make_request); q->make_request_fn = mfn;- 1
- 2
- 3
- 4
__make_request接口实现
static int __make_request(request_queue_t *q, struct bio *bio) { struct request *req; int el_ret, nr_sectors, barrier, err; const unsigned short prio = bio_prio(bio); const int sync = bio_sync(bio); int rw_flags; nr_sectors = bio_sectors(bio); // 要读写的扇区个数 /* * low level driver can indicate that it wants pages above a * certain limit bounced to low memory (ie for highmem, or even * ISA dma in theory) */ blk_queue_bounce(q, &bio); barrier = bio_barrier(bio); if (unlikely(barrier) && (q->next_ordered == QUEUE_ORDERED_NONE)) { err = -EOPNOTSUPP; goto end_io; } spin_lock_irq(q->queue_lock); if (unlikely(barrier) || elv_queue_empty(q)) goto get_rq; // 首先通过调用 elv_merge 方法尝试将当前I/O请求与其他正在排队的I/O请求进行合并, // 如果当前I/O请求与正在排队的I/O请求相邻,那么就可以合并为一个I/O请求,从而减少对设备I/O请求的次数。 el_ret = elv_merge(q, &req, bio); switch (el_ret) { case ELEVATOR_BACK_MERGE: // 与其他I/O请求合并成功 BUG_ON(!rq_mergeable(req)); if (!ll_back_merge_fn(q, req, bio)) break; blk_add_trace_bio(q, bio, BLK_TA_BACKMERGE); req->biotail->bi_next = bio; req->biotail = bio; req->nr_sectors = req->hard_nr_sectors += nr_sectors; req->ioprio = ioprio_best(req->ioprio, prio); drive_stat_acct(req, nr_sectors, 0); if (!attempt_back_merge(q, req)) elv_merged_request(q, req, el_ret); goto out; case ELEVATOR_FRONT_MERGE: // 与其他I/O请求合并成功 BUG_ON(!rq_mergeable(req)); if (!ll_front_merge_fn(q, req, bio)) break; blk_add_trace_bio(q, bio, BLK_TA_FRONTMERGE); bio->bi_next = req->bio; req->bio = bio; /* * may not be valid. if the low level driver said * it didn't need a bounce buffer then it better * not touch req->buffer either... */ req->buffer = bio_data(bio); req->current_nr_sectors = bio_cur_sectors(bio); req->hard_cur_sectors = req->current_nr_sectors; req->sector = req->hard_sector = bio->bi_sector; req->nr_sectors = req->hard_nr_sectors += nr_sectors; req->ioprio = ioprio_best(req->ioprio, prio); drive_stat_acct(req, nr_sectors, 0); if (!attempt_front_merge(q, req)) elv_merged_request(q, req, el_ret); goto out; /* ELV_NO_MERGE: elevator says don't/can't merge. */ default: ; } // 无法和其他I/O请求合并,则构建一个i/o请求。 get_rq: /* * This sync check and mask will be re-done in init_request_from_bio(), * but we need to set it earlier to expose the sync flag to the * rq allocator and io schedulers. */ rw_flags = bio_data_dir(bio); if (sync) rw_flags |= REQ_RW_SYNC; /* * Grab a free request. This is might sleep but can not fail. * Returns with the queue unlocked. */ req = get_request_wait(q, rw_flags, bio); /* * After dropping the lock and possibly sleeping here, our request * may now be mergeable after it had proven unmergeable (above). * We don't worry about that case for efficiency. It won't happen * often, and the elevators are able to handle it. */ // 根据bio构建一个i/o请求 init_request_from_bio(req, bio); spin_lock_irq(q->queue_lock); if (elv_queue_empty(q)) blk_plug_device(q); // 向队列提交i/o请求 add_request(q, req); out: // 同步处理队列的i/o请求 if (sync) __generic_unplug_device(q); spin_unlock_irq(q->queue_lock); return 0; end_io: bio_endio(bio, nr_sectors << 9, err); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
__generic_unplug_device(q) -> q->request_fn(q); // 调用队列的处理函数,由块设备驱动程序提供 ramblock_queue = blk_init_queue(do_ramblock_request, &ramblock_lock);- 1
- 2
四,总结
用户程序通过块设备驱动节点,读写块设备数据的流程
- 块设备驱动程序初始化时调用blk_init_queue接口初始一个i/o请求队列,并为该队列提供一个队列"请求处理函数";
- 用户程序调用read()/write(),会转换成通用块层ll_rw_block接口的调用;
- ll_rw_block接口通过调用submit_bh接口提交读写数据块;
- submit_bh接口构建并设置bio,然后通过submit_bio接口提交bio;
- 调用块设备队列的"构造请求函数"处理bio,即__make_request接口处理bio;
- __make_request接口首先尝试和其他i/o请求合并bio以减少对设备I/O请求的次数;
- 如果合并不成功,则构建一个新的i/o请求;
- 所有bio处理(和其他i/o请求合并或构建一个新的i/o请求)完成或者用户强制sync时,会处理所有的i/o请求,调用__generic_unplug_device接口,调用队列的"请求处理函数"处理所有请求(读写数据)。
-
相关阅读:
社群运营怎么做?
《C和指针》笔记35:结构体
空值合并运算符(??)及其使用场景
runloop
《向量数据库指南》——Range Search 使用方法和参数检查
阿里云k8s服务之间偶尔获取不到dns解析安装ACK NodeLocal DNSCache
Clickhouse MaterializeMySQL引擎详解
vue3 全局方法挂载
使用编辑距离实现英语单词纠错-面向对象实现
Unity使用ConfigurableJoint实现物理拖拽物体
- 原文地址:https://blog.csdn.net/qq_40709487/article/details/126696460
