-
分段读取csv文件并可视化处理
1.数据
使用数据为csv文件,数据有89万条记录,名称字段具体如下:
Time (sec)
Delta Time (sec)
Segment ID
Latitude (deg)
Longitude (deg)
Easting (m)
Northing (m)
Cross-Track (m)
Along-Track (m)
Height (m HAE)
Height (m MSL)
Classification
Signal Confidence
Dem_height
luccID
32.56000081
78976682.22
161266
29.08135819
113.4059348
734190.7155
3219390.276
-22.7432411
20201.67926
77.74754333
93.76404762
0
0
0
0
32.56000081
78976682.22
161266
29.08135858
113.4059346
734190.7011
3219390.318
-22.7526257
20201.72316
91.41132355
107.4278278
0
0
0
0
32.56000081
78976682.22
161266
29.08135802
113.4059348
734190.722
3219390.257
-22.7389931
20201.65946
71.5628891
87.57939339
0
0
0
0
32.56000081
78976682.22
161266
29.08135773
113.4059349
734190.733
3219390.224
-22.7318915
20201.62621
61.22312164
77.23962593
0
0
0
0
32.56000081
78976682.22
161266
29.08135811
113.4059348
734190.7185
3219390.267
-22.7412967
20201.67021
74.91683197
90.93333626
0
0
0
0
32.56000081
78976682.22
161266
29.08135616
113.4059355
734190.7915
3219390.052
-22.6938061
20201.44813
5.772859573
21.78936386
0
0
0
0
32.56000081
78976682.22
161266
29.08135614
113.4059355
734190.7922
3219390.05
-22.6933262
20201.44587
5.074115753
21.09062004
0
0
0
0
32.56000081
78976682.22
161266
29.08135651
113.4059354
734190.7784
3219390.091
-22.7023598
20201.48811
18.22643089
34.24293518
0
0
0
0
32.56000081
78976682.22
161266
29.08135656
113.4059354
734190.7765
3219390.096
-22.7035772
20201.49374
19.99853134
36.01503563
0
0
0
0
32.56000081
78976682.22
161266
29.08135584
113.4059356
734190.8036
3219390.016
-22.6859499
20201.41132
-5.66560459
10.3508997
0
0
0
0
32.56010081
78976682.22
161266
29.08136468
113.405934
734190.6294
3219390.994
-22.7452324
20202.4024
80.65776825
96.67429392
0
0
0
0
2.读取数据
2.1完整读取数据并显示
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- inputpath=r"E:\csv_dbscan\ATL03_20200703015729_01180802_005_01_gt1r.csv"
- df=pd.read_csv(inputpath)
- X=df['Time (sec)']
- Y=df['Height (m HAE)']
- plt.figure()
- plt.scatter(X,Y,marker='o',s=0.000003,label='Point Cloud')
- plt.legend()
- plt.show()
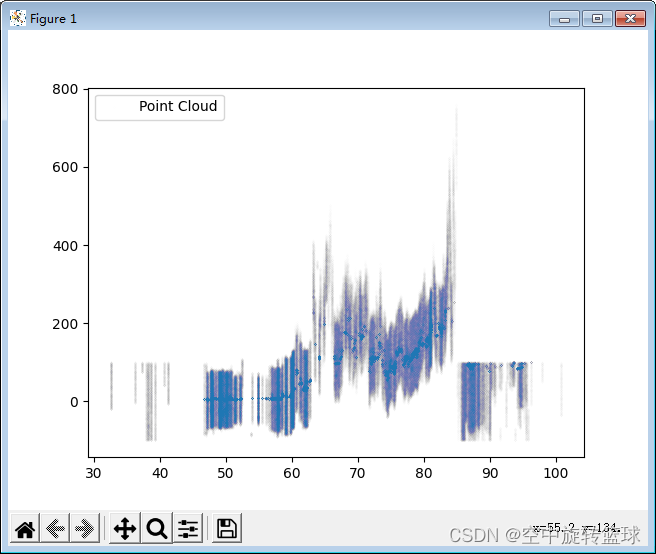
放大显示:

2.2分段读取数据并显示
(1)根据总记录数和分段数来计算每段的数量是多少,然后我们每次只读取一段数据。
方法1:使用chunksize参数实现分段读取和显示
chunksize是按照行记录数量来分段的
- df_chunker = pd.read_csv(inputpath,chunksize=segment_count)
- for df_item in df_chunker:
- X_seg = df_item['Time (sec)']
- Y_seg = df_item['Height (m HAE)']
- plt.figure()
- plt.scatter(X_seg, Y_seg, marker='o', s=1, label='Point Cloud')
- plt.legend()
- plt.show()
比如我们每段数据设置为segment_count=10000条,那么就有segment_n=N/segment_count(segment_count每段记录数,N总记录数,segment_n为段数)段数据。
我们按照顺序读取每段数据并显示:

方法2:使用沿线距离来分段显示
比如我们使用Along-Track (m)属性1000m分段显示:第一段的范围是20201.67926-20301.67926,后面依次加1000.
- len_data=len(df['Time (sec)']) #行记录数
- segment_count=1000
- Along_track_n=int((df['AlongTrack'][len_data-1]-df['AlongTrack'][0])/segment_count)+1
- start=df['AlongTrack'][0]
- end=df['AlongTrack'][len_data-1]
- for len_seg in range(Along_track_n):
- df_seg = df.loc[(df['AlongTrack'] >= (start + len_seg * segment_count)) & (df['AlongTrack'] <= (start+ (len_seg + 1) * segment_count)),:]
- X_seg = df_seg['AlongTrack']
- Y_seg = df_seg['Height (m HAE)']
- if len(X_seg)==0:
- print("该段没数据!")
- plt.figure()
- plt.scatter(X_seg, Y_seg, marker='o', s=1, label='Point Cloud')
- plt.legend()
- plt.show()


-
相关阅读:
R语言dplyr包select函数删除dataframe数据中的以指定字符串开头的数据列(变量)
Flutter开发进阶之错误信息
docker 容器优雅关闭 —— 筑梦之路
【Linux】进程间通信——管道
Java学习第一课
halcon之区域:多种区域(Region)生成(4)
一起Talk Android吧(第三百九十回:关于Android版本12适配蓝牙权限的问题)
spring的Ioc、DI以及Bean的理解
索引构建磁盘IO太高,巧用tmpfs让内存来帮忙
智能指针那些事
- 原文地址:https://blog.csdn.net/soderayer/article/details/126695776