-
Flink 基础概念
一、 简单介绍一下Flink
Flink是一个面向流处理和批处理的分布式数据计算引擎,能够基于同一个Flink运行,可以提供流处理和批处理两种类型的功能。 在 Flink 的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流:这就是所谓的有界流和无界流。
二、Flink中的Time有哪几种
-
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
-
Ingestion Time:是数据进入Flink的时间。
-
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
三、Flink中的滚动窗口、滑动窗口、会话窗口
流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据为有限块进行处理的手段。
所以Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
根据分配数据的规则,窗口的具体实现可以分为 4 类:滚动窗口(Tumbling Window)滑动窗口、会话窗口(Session Window)
3.1滚动窗口(Tumbling Window):
滚动窗口有固定的大小,是一种
对数据进行均匀切片的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)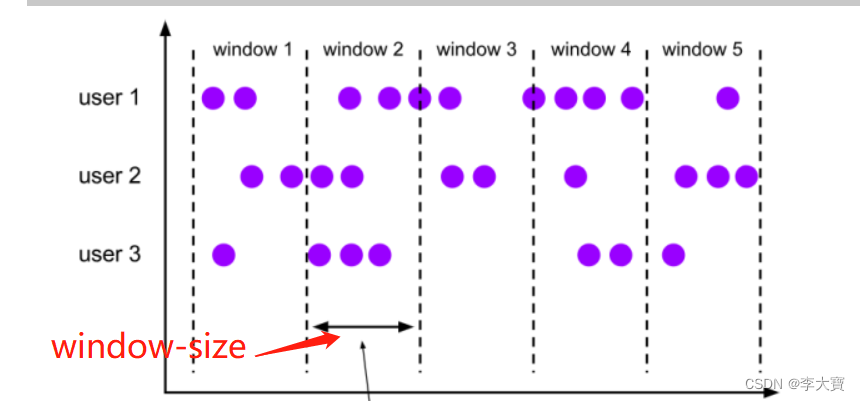
3.2 滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个滑动步长(window slide),代表窗口计算的频率。

3.3 会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
四、讲⼀下Flink的运⾏架构

当 Flink 集群启动后,
- ⾸先会启动⼀个 JobManger 和⼀个或多个的 TaskManager。
- 由 Client 提交任务给 JobManager,JobManager 将任务调度到各个 TaskManager 去执⾏,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进⾏数据的传输。上述三者均为独⽴的 JVM 进程。
- JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,从 Client 处接收到 Job 等资源后,会⽣成优化后的执⾏计划,并以 Task 的单元调度到各个 TaskManager 去执⾏。
- TaskManager 在Task Slot 上运行Task,并定时将Task Manager的运行状态和Task的运行状态发送给Job Manager,Job Manager根据Task Manager上的资源使用情况和Task的运行状态对集群进行调度
其中Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)
五、Flink on Yarn的两种运行方式
内存集中管理模式(yarn-session模式):在Yarn中初始化一个Flink集群,开辟指定的资源,之后我们提交的Flink Jon都在这个Flink yarn-session中,也就是说不管提交多少个job,这些job都会共用开始时在yarn中申请的资源。这个Flink集群会常驻在Yarn集群中,除非手动停止。
启动yarn资源: yarn-session.sh -n 2 -jm 1024 -tm 1024 -d- -n 2 表示指定两个容器
- -jm 1024 表示 jobmanager 1024M内存
- -tm 1024表示 taskmanager 1024M内存
- -d 任务后台运行
Job管理模式【推荐使用】:在Yarn中,每次提交job都会创建一个新的Flink集群,任务之间相互独立,互不影响并且方便管理。任务执行完成之后创建的集群也会消失。
提交命令:flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -c xxx ./data/batch/WordCount.jar六、讲⼀下Flink的作业执⾏流程
1 Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
2 向Yarn ResourceManager提交任务
3 ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster
4 ApplicationMaster启动后加载Flink的Jar包和配置构建环境
5 启动JobManager之后ApplicationMaster向ResourceManager申请资源启动TaskManager
6 ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
7 NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
8 TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
七、如何排查生产环境中的反压问题
1. 反压出现的场景
反压是在实时数据处理中,数据管道某个节点上游产生数据的速度大于该节点处理数据速度的一种现象。反压会从该节点向上游传递,一直到数据源,并降低数据源的摄入速度。这在流数据处理中非常常见,很多场景可以导致反压的出现,比如, GC导致短时间数据积压,数据的波动带来的一段时间内需处理的数据量大增,甚至是checkpoint本身都可能造成反压。
2. 反压监控方法
通过Flink Web UI发现反压问题。
Flink 的 TaskManager 会每隔 50 ms 触发一次反压状态监测,共监测 100 次,并将计算结果反馈给 JobManager,最后由 JobManager 进行计算反压的比例,然后进行展示。
这个比例展示逻辑如下:
OK: 0 <= Ratio <= 0.10,表示状态良好正;
LOW: 0.10 < Ratio <= 0.5,表示有待观察;
HIGH: 0.5 < Ratio <= 1,表示要处理了(增加并行度/subTask/检查是否有数据倾斜/增加内存)。
0.01,代表100次中有一次阻塞在内部调用。
3. 反压问题定位和处理
Flink会因为数据堆积和处理速度变慢导致checkpoint超时,而checkpoint是Flink保证数据一致性的关键所在,最终会导致数据的不一致发生。
数据倾斜:可以在 Flink 的后台管理页面看到每个 Task 处理数据的大小。当数据倾斜出现时,通常是简单地使用类似 KeyBy 等分组聚合函数导致的,需要用户将热点 Key 进行预处理,降低或者消除热点 Key 的影。
GC:不合理的设置 TaskManager 的垃圾回收参数会导致严重的 GC 问题,我们可以通过
-XX:+PrintGCDetails参数查看 GC 的日志。代码本身:开发者错误地使用 Flink 算子,没有深入了解算子的实现机制导致性能问题。我们可以通过查看运行机器节点的 CPU 和内存情况定位问题。
八. Flink的内存管理是如何做的
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上。此外,Flink大量的使用了堆外内存。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。Flink 为了直接操作二进制数据实现了自己的序列化框架
九、 Flink对于迟到数据是怎么处理的
Flink中 WaterMark 和 Window 机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据eventTime进行业务处理,对于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据
设置允许延迟的时间是通过allowedLateness(lateness: Time)设置
保存延迟数据则是通过sideOutputLateData(outputTag: OutputTag[T])保存
获取延迟数据是通过DataStream.getSideOutput(tag: OutputTag[X])获取
十、Flink是如何保证Exactly-once语义的
Flink通过实现两阶段提交和状态保存来实现端到端的一致性语义。分为以下几个步骤:
开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件夹里面
预提交(preCommit)将内存中缓存的数据写入文件并关闭
正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟
丢弃(abort)丢弃临时文件
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
十一、如果下级存储不支持事务,Flink怎么保证exactly-once
端到端的exactly-once对sink要求比较高,具体实现主要有幂等写入和事务性写入两种方式。
幂等写入的场景依赖于业务逻辑,更常见的是用事务性写入。而事务性写入又有预写日志(WAL)和两阶段提交(2PC)两种方式。
如果外部系统不支持事务,那么可以用预写日志的方式,把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
十二、Flink设置并行度的方式
算子层面:.map(new RollingAdditionMapper()).setParallelism(10) //将操作算子设置并行度
环境层面:$FLINK_HOME/bin/flink 的-p参数修改并行度
客户端层面: env.setParallelism(10):
系统层面:全局配置在flink-conf.yaml文件中,parallelism.default,默认是1:可以设置默认值大一点
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
-
-
相关阅读:
[附源码]Python计算机毕业设计Django实验室管理系统
Nacos注册中心和服务消费方式(服务治理)
基于R语言、MATLAB、Python机器学习方法与案例分析
【大模型入门】LLM-AI大模型介绍
中缀表达式 - 栈实现综合计算器
R-install_miniconda()卸载 | conda命令行报错及解决方法
[ZJOI2013]K大数查询 (权值线段树套权值线段树+标记永久化)
Android源码——Contxt和ContextWrapper源码解析
github-actions
贪心算法的高逼格应用——Huffman编码
- 原文地址:https://blog.csdn.net/libaowen609/article/details/126692666