-
ACL2021论文笔记(3篇)
An End-to-End Progressive Multi-Task Learning Framework for Medical Named Entity Recognition and Normalization
——医学领域
论文面向领域:医学实体识别任务和实体标准化任务。
后者是将识别到的mention和知识库中已有的mention做对比,标准化已识别到的mention。这一项任务也可以被理解为short text的matching问题。
**思想:**先易后难,从简单的做起。
将任务分解为子任务,从简单的子任务不断扩展到复杂的子任务。现有的研究
- 管道式方法:前者被公式化以最大化后验概率 p(yNER |x) 和 p(yNEN |m, e) 其中 x 是医学文本,m
是识别模型提取的医学提及,e 是标准实体, yNER 和 yNEN 是实体类型。 - 并行式方法:后者试图最大化后验概率 p(yNER, yNEN |x)
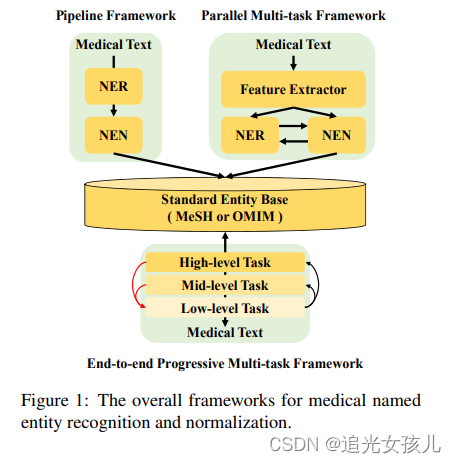
端到端-任务建模(由简入难)
encoder:Bert
-
低层级任务:抽取出医学文本中的所有可能实体
- loss:交叉熵损失函数
- 任务形式:识别NER的label
-
中层级任务:识别现有的医学实体是否可以映射到标准的实体;
- 任务形式:将text和现有的entity base建模为二元组形式,判断text中是否存在base中的entity。
- loss:二分类交叉熵
-
高层级任务:抽取出可以被映射到标准候选实体的实体提及。
- 实体mention的特征和标准实体特征,计算预测概率。
**整个训练过程的损失:**L = Llow + λ · Lmid + µ · Lhigh
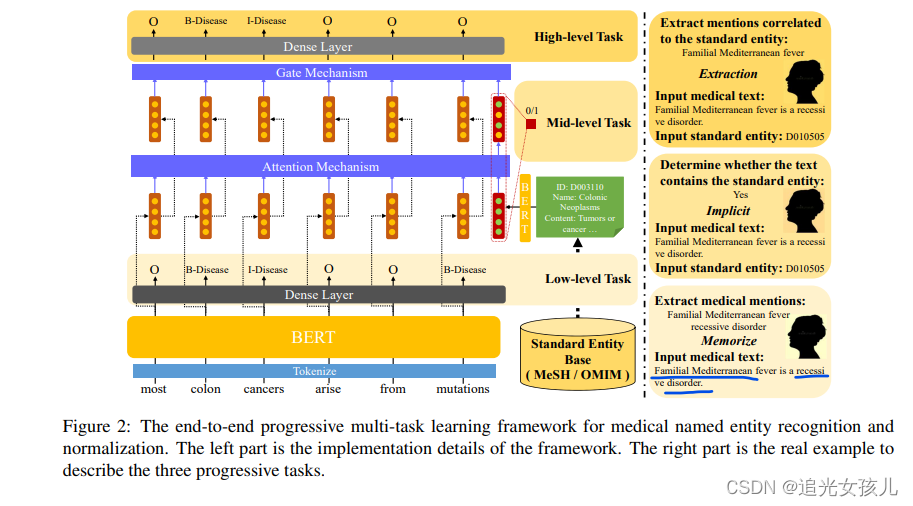
- 实体mention的特征和标准实体特征,计算预测概率。
总结
论文中的思想:从简到难值得借鉴。
当吧任务拆分为子任务时,会遇到一个问题,误差传播和任务之间的交互性,这里采用了注意力机制的方法,可以借鉴。(这点比较重要)Modeling Fine-Grained Entity Types with Box Embeddings
细粒度的命名实体类型识别问题。
- 文中一个出发点:相比于以往的dot
product的方式计算,以点的形式在向量空间中表示。文中提出了几何方法表示实体,以几何体的体积作为计算依据。在细粒度考量上,不仅考虑了树状形式的实体类型树,也考虑到了不同类型之间的多种复杂关系,文中的例子是poliction
and Author。 - 文中的另一个出发点是:更高维度的表示,可以使得细粒度的实体分类结果更加精确。
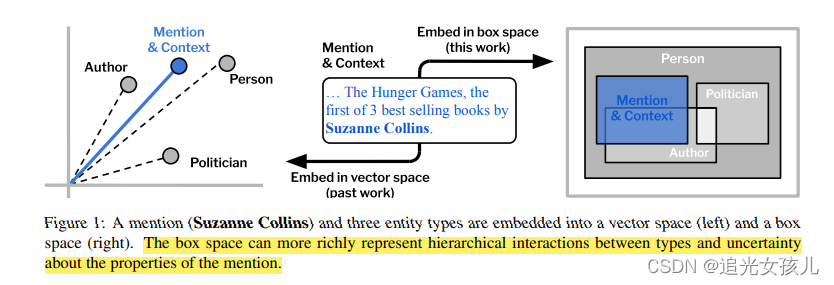
模型
### 盒模型 盒的体积计算:Vol(x) = ∏︁i(xM,i − xm,i). 如果我们将框空间的体积标准化为 1,我们可以将每个框的体积解释为提及显示给定实体类型的边际概率。 条件概率计算为: P(y | x) = Vol(x∩y)/Vol(x) improve training of box embeddings using max and min Gumbel distributions (i.e., Gumbel boxes) to represent the min and max coordinates of a box.- 1
- 2
- 3
- 4
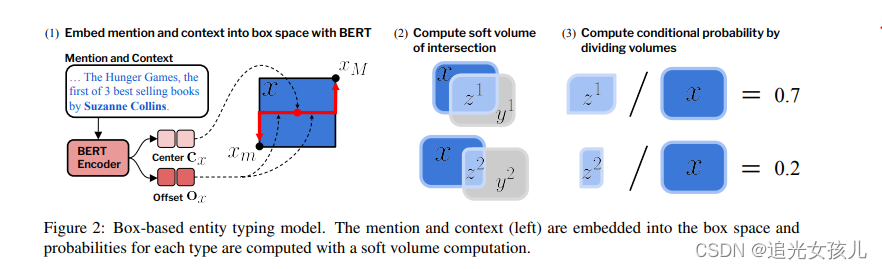
x是上下文的嵌入,y是某个type的嵌入,zk是交叉重叠部分。

-
mention and context encoder
- Bert
- 将整个序列编码为单个vector,使用的是CLS表示的整个序列。
- 线性层,将hidden state映射到高维向量空间 2d
- 2d中一个d表示box的中心,一个d表示box的偏置。
loss计算(m表示mention和s表示context):

总结
最出彩的地方,就是开头的出发点。
眼前一亮。dot->box;
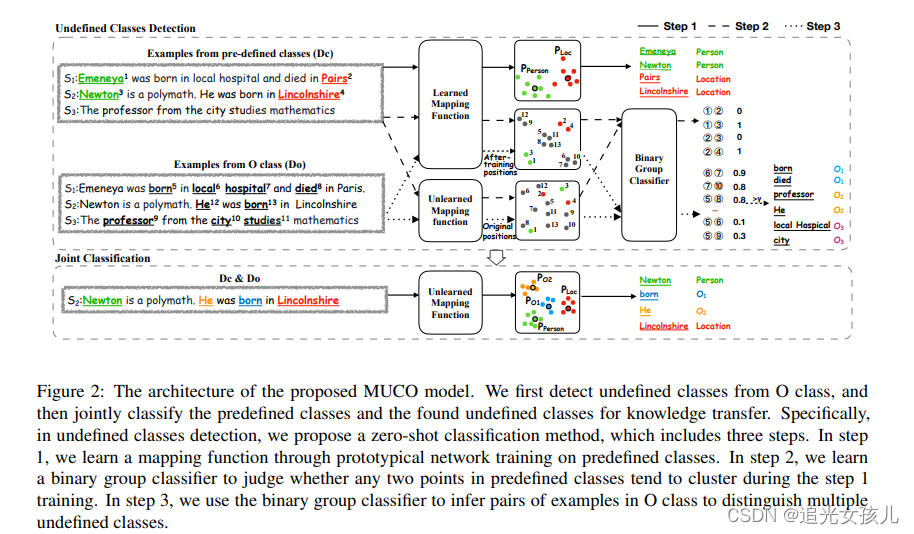
Learning from Miscellaneous Other-Class Words for Few-shot Named Entity Recognition
利用O class表示的信息,丰富知识表示,具体,是对O表示的部分,做一个类型分类,类似于实体分类任务。
出发点:我们主张进一步将 O 类解耦为多个未定义的类,以充分利用隐藏在 O 类中的丰富语义
模型部分
一是预测O表示的classes
二是识别文中的实体。- O分类问题
-
zero-shot 问题
-
In step 1, we train the prototypical network on predefined classes to obtain the learned mapping function. Through the learned mapping function the examples belonging to the same class will cluster in the space. In step 2, we train a binary group classifier on predefined classes base on the position features from the learned mapping function and unlearned mapping function to judge whether any two points tend to cluster during the step 1 training. In step 3, we use the learned binary group classifier in step 2 to infer examples in O class to distinguish undefined classes from each other
-
第一步,根据现有的标注实体训练每种类型的原型网络
-
第二步+第三步,根据原型,训练一个二分类器,判断O class是否可以归于其中某类,或聚类到某类
-
- 管道式方法:前者被公式化以最大化后验概率 p(yNER |x) 和 p(yNEN |m, e) 其中 x 是医学文本,m
-
相关阅读:
大数据分布式计算工具Spark实战讲解(数据输入实战)
Spring(八)- Spring整合MyBatis框架原理剖析
宝塔面板网站解决跨域问题
B2B企业如何打造独立站:从策略到实施的全面指南
javascript数据类型
leecode337. 打家劫舍 III
java计算机毕业设计ssm气象百事通系统-天气预报系统
【附源码】计算机毕业设计JAVA专利查询与发布系统设计与实现
Docker 网络访问原理解密
Python实现的公众号系统介绍及其中间件分析
- 原文地址:https://blog.csdn.net/Hekena/article/details/126695524