-
强化学习简介
title: 强化学习简介
机器学习的类型
-
预测型
- 有监督学习:根据数据预测所需输出,根据p(x)得到p(y)
- 无监督学学习:生成数据实例,联合概率分布函数p(x|y)
-
决策型
- 强化学习:在动态的环境中采取行动
- 转变到新的状态
- 得到及时奖励
- 随着时间的推移得到最大累积奖励
区别: 比如智慧医疗,前者像是根据你的身体预测你可能会得某种疾病;后者是ai直接提供一个治疗方案
- 强化学习:在动态的环境中采取行动
强化学习的定义
-
智能体
- 感知:在某种程度上感知环境的状态
- 行动:采取行动影响状态或者达到目标
- 目标:获得最大的累积奖励
-
环境
- 智能体所处的环境,智能体的行为会改变环境
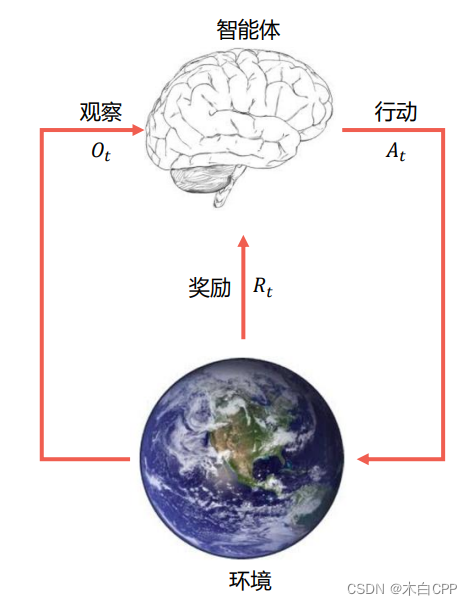
- 交互过程
-
智能体
- 获得观测 O t O_t Ot
- 获得奖励 R t R_t Rt
- 做出行动 A t A_t At
-
环境
- 获得行动 A t A_t At
- 给出观测 O t + 1 O_{t+1} Ot+1
- 给出奖励 R t + 1 R_{t+1} Rt+1
-
t在环境这一步增加
-
例子: 如果你在玩超级玛丽,那么游戏画面就是环境,玛丽是智能体,根据当前的游戏画面,超级玛丽会有三种行为。每一次跳跃前进后退都会改变环境(金币减少、蘑菇被吃、game over…),每一次的行为都会得到一个奖励,金币减少+1,通关+100,game over-100,因为我们的目标是获得最大累积奖励,通过不断训练不断重复,超级玛丽最终会朝着奖励最大的方向做出一系列动作。
强化学习术语
-
符号解释
- P(X|Y) 表示条件概率,Y发生的情况下,X发生的概率
- E[X|Y] 表示Y发生的情况下,对X求期望,有 E [ X ∣ Y ] = ∑ x ∈ X P ( X ∣ Y ) ⋅ x E[X|Y]=\sum_{x\in X}P(X|Y)·x E[X∣Y]=∑x∈XP(X∣Y)⋅x
-
历史: 是观察、行动和奖励的序列,根据这个历史就可以知道接下来会发生什么动作。
H t = O 1 , R 1 , A 1 , O 2 , R 2 , A 2 , . . . , O t − 1 , R t − 1 , A t − 1 , Q t , R t H_t=O_1,R_1,A_1,O_2,R_2,A_2,...,O_{t-1},R_{t-1},A_{t-1},Q_{t},R_t Ht=O1,R1,A1,O2,R2,A2,...,Ot−1,Rt−1,At−1,Qt,Rt -
状态(state): 处于环境中的一种状态,移动超级玛丽,状态改变
序列也可以改成:
H t = S 1 , A 1 , R 2 , S 2 , A 2 , . . . , S t H_t=S_1,A_1,R_2,S_2,A_2,...,S_t Ht=S1,A1,R2,S2,A2,...,St -
策略(Policy): 是状态到行动的映射,合格的策略能指导智能体采取最佳行动以获取最高总收益。
- 确定性策略(Deterministic Policy) a = π ( s ) a=\pi(s) a=π(s)
- 随机策略(Stochastic Policy) π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s)=P(A_t=a|S_t=s) π(a∣s)=P(At=a∣St=s)
-
奖励(Reward): R ( s , a ) R(s,a) R(s,a)是一个标量,能立即感知什么是“好”。
-
回报(return): 我们把未来的奖励称之为回报,即带衰减的后续奖励之和,例如从t时刻开始的回报可以定义为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . = ∑ k = t ∞ γ k R t + k + 1 G_t=R_{t+1}+\gamma R_{t+2}+\gamma ^2R_{t+3}+...=\sum_{k=t}^\infty\gamma ^kR_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+...=k=t∑∞γkRt+k+1
其中$\gamma $为折扣因子(discounting factor),区间在[0,1]。- 为什么未来的奖励需要衰减?
- 未来的奖励存在不确定性(比如股票)
- 未来的奖励不会给当前提供太大的收益(所以很多人提倡及时行乐)
- 因为衰减,无需考虑太长远的收益
- 为什么从
R
t
+
1
R_{t+1}
Rt+1开始?
- 因为在t时刻采取的行动后,在t+1时刻才有奖励,也就是说 R t + 1 R_{t+1} Rt+1是根据 A t A_{t} At给出的。比如,给pid控制器一组参数这个动作完成之后,等到整个系统走完之后得到一个输出才能给出判断(奖励)
- 为什么未来的奖励需要衰减?
-
价值函数: 用于定义长期什么是“好”,价值函数是对于未来累积奖励的预测,用于评估未来某个状态或者动作的好坏。
- 动作价值函数(Action-value function): 表示定义一对(s,a)行为的价值,也可以说在某一状态下采取动作后,最终能获得多少累积奖励的函数:
Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q_{\pi}(s,a)=E_{\pi}[G_t|S_t=s,A_t=a] Qπ(s,a)=Eπ[Gt∣St=s,At=a] - 状态价值函数(State-value function): 表示在t时刻下,在该状态下未来回报的期望值
V π ( s ) = E π [ G t ∣ S t = s ] V_{\pi}(s)=E_{\pi}[G_t|S_t=s] Vπ(s)=Eπ[Gt∣St=s] - 因为是根据策略
π
\pi
π来生成动作的,可以想象成是该状态下所有动作的动作价值函数的累加,两者可以表示为:
V π ( s ) = ∑ a ∈ A Q π ( s , a ) π ( a ∣ s ) V_{\pi}(s)=\sum_{a\in A} Q_{\pi}(s,a) \pi(a|s) Vπ(s)=a∈A∑Qπ(s,a)π(a∣s)
- 动作价值函数(Action-value function): 表示定义一对(s,a)行为的价值,也可以说在某一状态下采取动作后,最终能获得多少累积奖励的函数:
-
最优价值函数: 采用最优策略可以产生最大回报
Q ∗ ( s , a ) = m a x π Q π ( s , a ) Q_*(s,a)=\underset {\pi}{max}Q_{\pi}(s,a) Q∗(s,a)=πmaxQπ(s,a)
V ∗ ( s ) = m a x π V π ( s ) V_*(s)=\underset {\pi}{max}V_{\pi}(s) V∗(s)=πmaxVπ(s)强化学习算法分类
-
是否依赖模型
-
基于模型的强化学习:有环境模型,比如围棋,象棋
-
模型无关的强化学习:无环境模型,需要和现实交互,比如ai医生
-
-
策略or价值
- 基于价值:智能体关注动作/状态价值函数,根据价值函数来生成策略
- 基于策略:根据策略,得到最优的价值函数
- 组合:Actor-Critic
-
-
相关阅读:
Spring MVC(上)
编写一个函数创建无向图的邻接表。
UDP用户数据报协议
MATLAB | 如何绘制三维曲线、曲面、多边形投影(三视图)?
带团队后的日常思考(十五)
人机组队概念的战场应用
latex修改公式的默认编号
R语言dplyr包select函数删除dataframe数据中的以指定字符串开头的数据列(变量)
CMake详解--从创建到编译
做产品经理需要很高的学历吗?真相来咯!
- 原文地址:https://blog.csdn.net/u011895157/article/details/126695007