-
【项目实战】自主实现 HTTP 项目(五)——返回静态网页
目录

构建响应
我们上次说完了处理请求与构建相应,而现在我们要做的就是完成对于不需要启动CGI的请求,在确认路径有效的情况下,我们要对其返回静态的网页,当然,这里的返回网页不仅仅是返回我们的网页内容,这里我们需要加上响应行,相应报头的等等信息。

可以看到的是响应报文的结构,其中包括的是状态行,响应报头,空行,和响应正文等,这个时候我们构建响应类,把这些添加入我们的响应类中。
- class HttpResponse{
- public:
- std::string status_line;
- std::vector
- std::string blank;
- std::string response_body;
- }
构建响应状态行
由上图可知,状态行包括的是 版本号,状态码 和状态码描述。
版本号和状态码的构建
- #define HTTP_VERSION "HTTP/1.0"
- #define LINE_END "\r\n"
- int ProcessNonCgi()
- {
- http_response.status_line =HTTP_VERSION;
- http_response.status_line +=" ";
- http_response.status_line +=std::to_string(http_response.status_code);
- http_response.status_line +=" ";
- http_response.status_line +=LINE_END;
- return 0;
- }
说明:
1.版本号,状态码 状态码的描述,中间都是用空格隔开的。
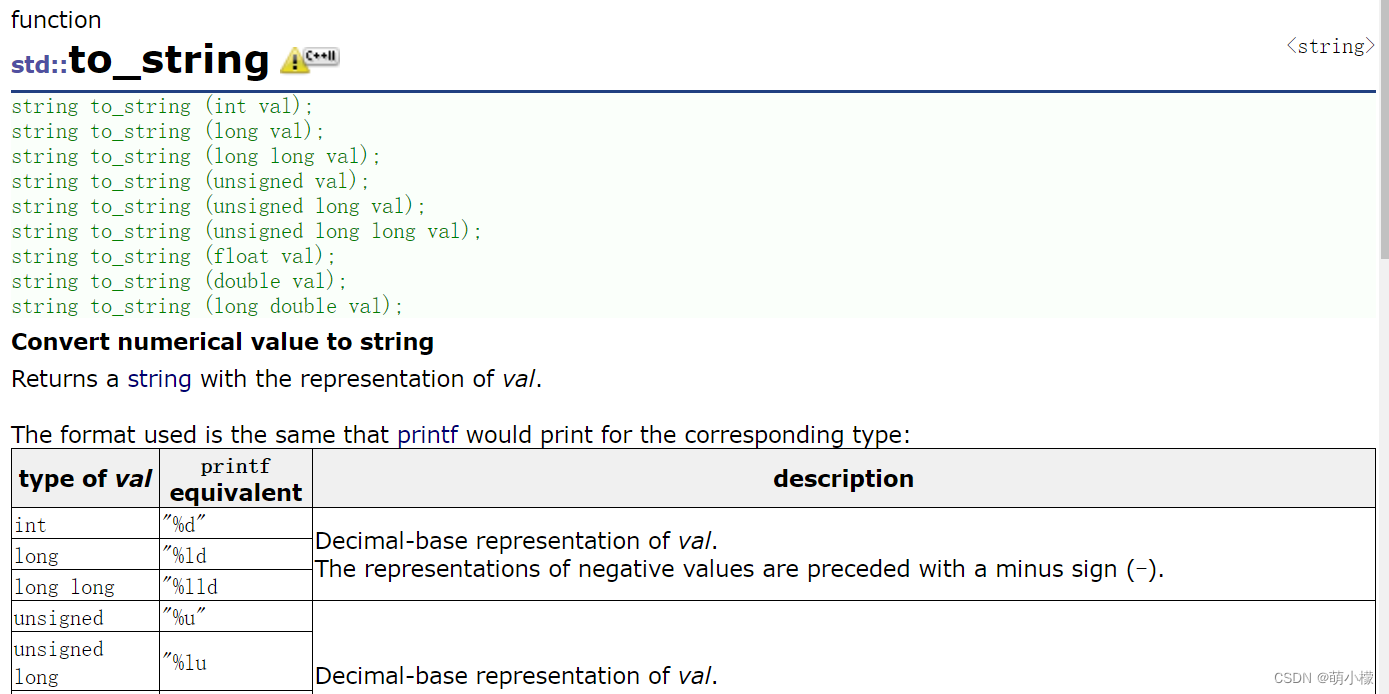
2.这里的状态码当时定义的是int类型,而这里因为要把它插入到string类型中的line中,所以要把它进行一步的转化,利用的是to_string函数。
3.我们这里默认以‘ \r\n ’作为统一的换行标志,因为我们之前已经自己写过统一的行处理了,这个时候就可以直接这样标志就行。
状态码描述的构建
我们之前通过定义宏来建立状态码和描述的联系,但是在这里我们可以构建一个函数,用switch语句来进行返回构建,来达到我们要的效果。
- static std::string Code2Desc(int code)
- {
- std::string desc;
- switch(code)
- {
- case 200:desc ="OK";
- break;
- case 404:desc ="Not Found";
- break;
- default:break;
- }
- return desc;
- }
- //....
- http_response.status_line +=Code2Desc(http_response.status_code);
- //....
发送报文
sendfile函数介绍
- int ProcessNonCgi(int size)
- {
- http_response.fd =open(http_request.path.c_str(),O_RDONLY);
- if(http_response.fd >= 0){
- http_response.status_line =HTTP_VERSION;
- http_response.status_line +=" ";
- http_response.status_line +=std::to_string(http_response.status_code);
- http_response.status_line +=" ";
- http_response.status_line +=Code2Desc(http_response.status_code);
- http_response.status_line +=LINE_END;
- http_response.size = size;
- return OK;
- }
- return 404;
- }
- void SendHttpResponse()
- {
- send(sock,http_response.status_line.c_str(),http_response.status_line.size(),0);
- for(auto iter:http_response.response_header){
- send(sock,iter.c_str(),iter.size(),0);
- }
- send(sock,http_response.blank.c_str(),http_response.blank.size(),0);
- sendfile(sock, http_response.fd ,nullptr, http_response.size);
- close(http_response.fd);
- }
我们这里先不管请求方法,直接来看找到对应的请求路径下的资源,打开请求资源进行读取和发送。这里说一下三个部分的发送方式,对于请求行部分,因为只有一行,我们直接调用send 发送即可,而对于请求方法行(虽然还没开始写,但是我们先把发送方法建立好),因为其是key:value的模式,我们用for的形式进行一行一行的发送,而对于正文来说,发送方式就有讲究了,我们这里详细谈一下。
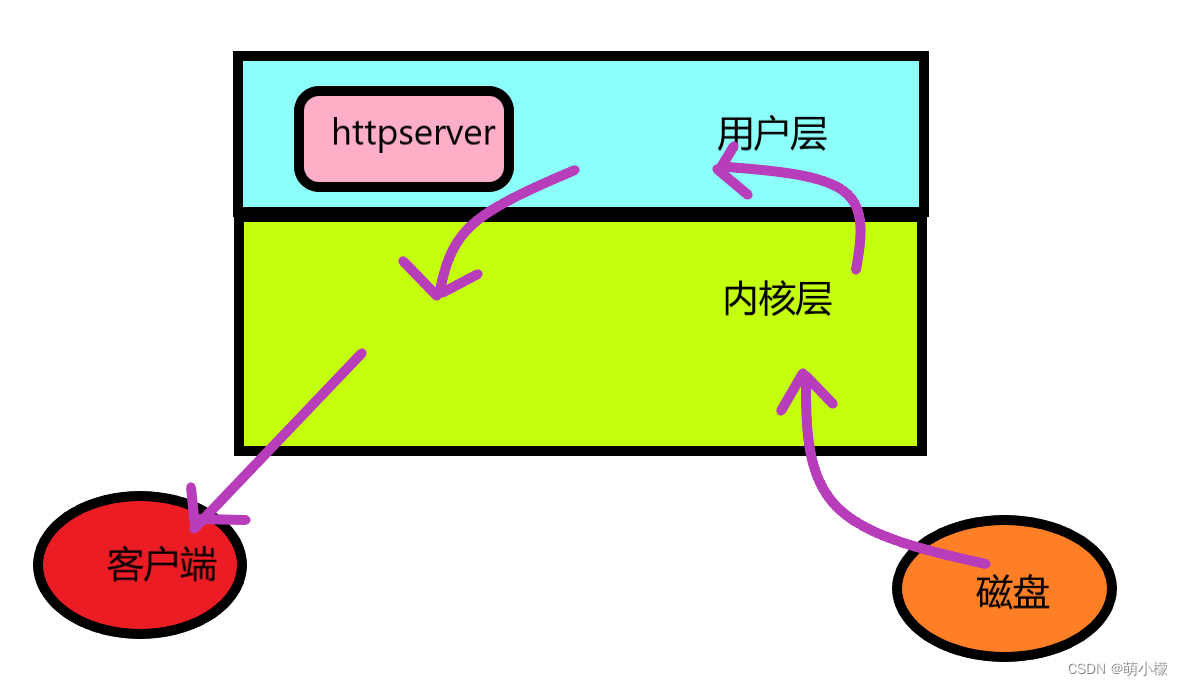
通常来说,正文部分的内容一般情况下比较多,而我们读取正文资源的时候一般都是要到我们服务器的磁盘上去读取,然后拷贝到我们的内核层的接收缓冲区,因为我们之前在response设定了一个body,这个是我们在用户层自己设定的接口,如果想要把正文内容填充到body,那么就应该再把数据从内核层拷贝到用户层,再由用户层send发出,但是send其实还是调用了内核层的接口,相当于再把正文内容拷贝到内核层的发送缓冲区,再由内核层发送出去,通过这个过程我们发现太麻烦了,这里我们想要优化,可以直接不经过用户层,直接由内核层从磁盘上读取,发送出去。
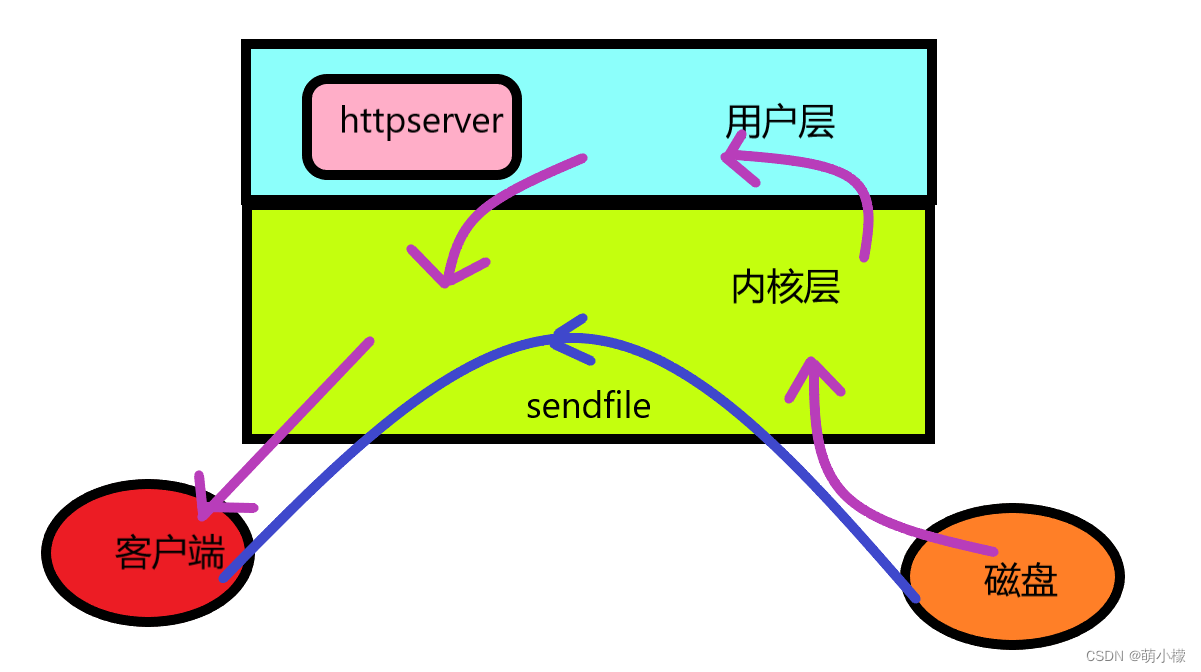
这里要介绍的函数就是sendfile
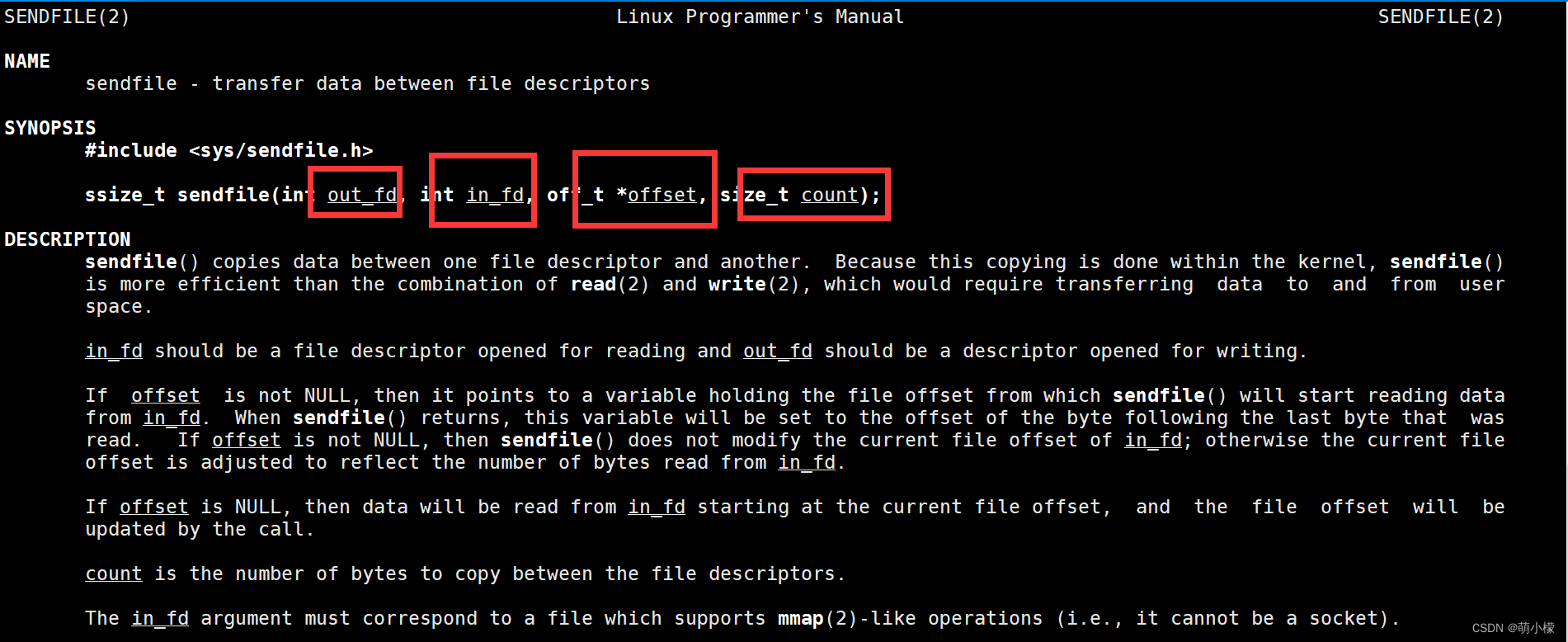 四个参数分别是:发送的套件字、读取文件的文件描述符,nullptr,以及需要发送的大小。
四个参数分别是:发送的套件字、读取文件的文件描述符,nullptr,以及需要发送的大小。发送完毕之后,我们就可以关闭对应的文件描述符即可。
正文大小获取方法
这个时候问题又来了,我们怎么知道正文的大小是多少呢,你还记得我们之前介绍的stat这个结构体吗,它是专门可以用来获取文件信息的结构体,而现在我们需要获取文件的字节数,我们就可以再次利用一下这个函数。
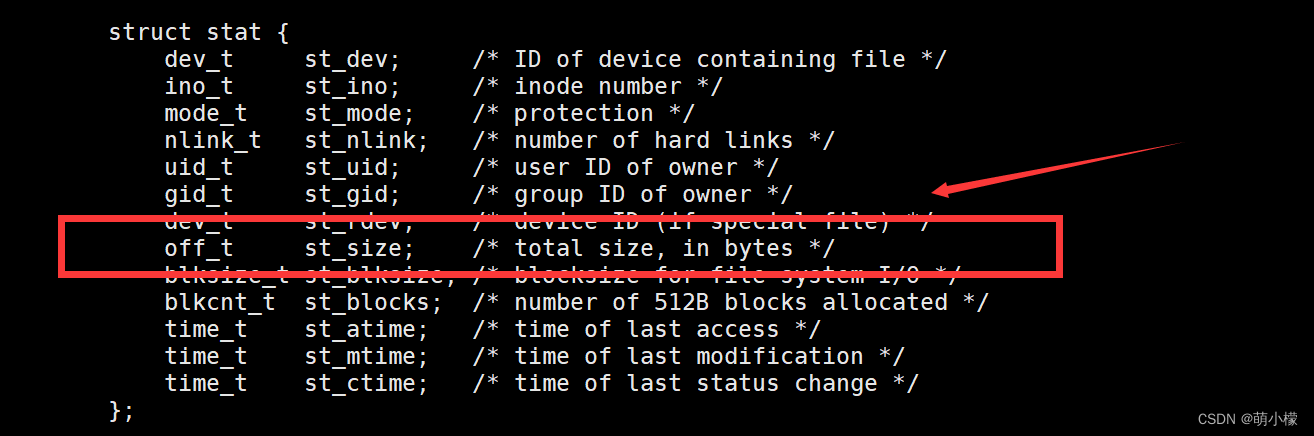
我们找到了可以帮我们获取文件大小的变量,st_size。
- //....
- int size=0;
- //....
- if(stat(http_request.path.c_str(),&st) == 0)
- {
- //说明资源是存在的
- if(S_ISDIR(st.st_mode)){
- //说明请求的资源是一个目录,不被允许的,需要做一下相关处理
- //虽然是一个目录,但是绝对不会以/结尾!
- http_request.path += "/";
- http_request.path += HOME_PAGE;
- stat(http_request.path.c_str(), &st);
- }
- if( (st.st_mode&S_IXUSR) || (st.st_mode&S_IXGRP) || (st.st_mode&S_IXOTH) ){
- //特殊处理
- http_request.cgi = true;
- }
- size =st.st_size;
- }
注意,中间第二次的stat是为了再次获取最新的字节数,来对size进行填充。
文件测试
这样,请求报头和正文都有了,我们来做一个测试。
在当前文件下面创建一个 index.html文件,并且输入一段有效文字,保存退出。
我们在网站上去随便找一个前端网页的模板进行一下测试。
我们这里以一段测试的前端代码作为实验
- html>
- <html lang="en">
- <head>
- <title>Logistics — Colorlib Website Templatetitle>
- <meta charset="utf-8">
- <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
- <link rel="stylesheet" href="static/css/style.css">
- <link rel="stylesheet" href="static/css/bootstrap.min.css">
- <link rel="stylesheet" href="static/css/magnific-popup.css">
- <link rel="stylesheet" href="static/css/jquery-ui.css">
- <link rel="stylesheet" href="static/css/owl.carousel.min.css">
- <link rel="stylesheet" href="static/css/owl.theme.default.min.css">
- <link rel="stylesheet" href="static/css/bootstrap-datepicker.css">
- <link rel="stylesheet" href="static/css/flaticon.css">
- <link rel="stylesheet" href="static/css/aos.css">
- <link rel="stylesheet" href="static/css/style1.css">
- head>
- <body>
- <div class="site-wrap">
- <div class="site-mobile-menu">
- <div class="site-mobile-menu-header">
- <div class="site-mobile-menu-close mt-3">
- <span class="icon-close2 js-menu-toggle">span>
- div>
- div>
- <div class="site-mobile-menu-body">div>
- div>
- <header class="site-navbar py-3" role="banner">
- <div class="container">
- <div class="row align-items-center">
- <div class="col-11 col-xl-2">
- <h1 class="mb-0"><a href="" class="text-white h2 mb-0">Logisticsa>h1>
- div>
- <div class="col-12 col-md-10 d-none d-xl-block">
- <nav class="site-navigation position-relative text-right" role="navigation">
- <ul class="site-menu js-clone-nav mx-auto d-none d-lg-block">
- <li class="active"><a href="">Homea>li>
- <li><a href="about.html">About Usa>li>
- <li class="has-children">
- <a href="services.html">Servicesa>
- <ul class="dropdown">
- <li><a href="#">Air Freighta>li>
- <li><a href="#">Ocean Freighta>li>
- <li><a href="#">Ground Shippinga>li>
- <li><a href="#">Warehousinga>li>
- <li><a href="#">Storagea>li>
- ul>
- li>
- <li><a href="industries.html">Industriesa>li>
- <li><a href="blog.html">Bloga>li>
- <li><a href="contact.html">Contacta>li>
- ul>
- nav>
- div>
- <div class="d-inline-block d-xl-none ml-md-0 mr-auto py-3" style="position: relative; top: 3px;"><a href="#" class="site-menu-toggle js-menu-toggle text-white"><span class="icon-menu h3">span>a>div>
- div>
- div>
- header>div>
这是我从网络上随机截取的一段前端代码,然后我们用浏览器进行访问。

我们可以会把前端的网页发送给我们,我们的实验就成功了。
添加响应方法
添加Content-length属性
- void BuildOkResponse()
- {
- line = "Content-Length: ";
- if(http_request.cgi){
- line += std::to_string(http_response.response_body.size());
- }
- else{
- line += std::to_string(http_request.size); //Get
- }
- line += LINE_END;
- http_response.response_header.push_back(line);
- }
由于之前我们已经设定了size 为正文长度,在这里我们直接获取就可以,但是这里和之前一样,需要把整形的size转化为string类型添加line中。
添加类型属性
我们想要拿到一个文件的类型,就是通过其文件名 点后面的内容来进行表示,而现在我们可以利用分隔符分割.后面的内容即可。
我们这里还需要一张对照表,利用unorded_map的形式进行映射对照
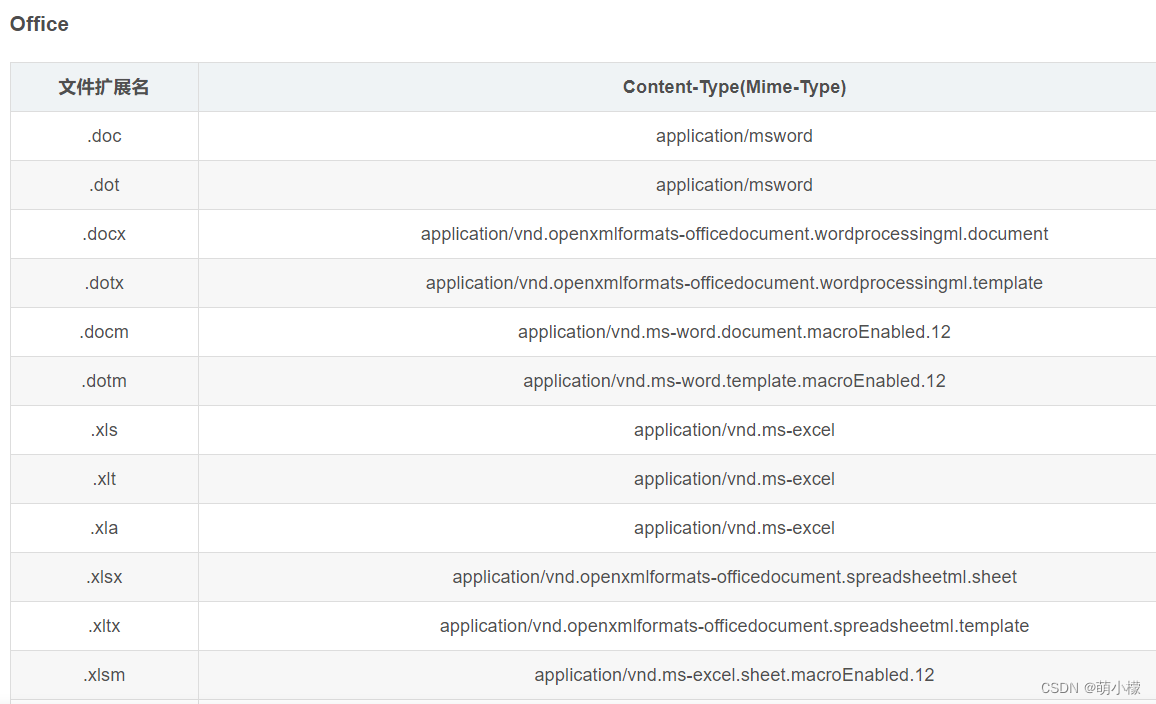
我们在这里简单插入几个常见的文件下标以及其Content-Type的对照
- static std::string Suffix2Desc(const std::string &suffix)
- {
- static std::unordered_map
- {".html","text/html"},
- {".css","text/css"},
- {".js","application/javascript"},
- {".jpg","application/x-jpg"},
- };
- auto iter =suffix2desc.find(suffix);
- if(iter !=suffix2desc.end()){
- return iter->second;
- }
- return "text/html";
- }
对照content-length的添加方式,进行content -type添加
- header_line ="Content-Type: ";
- header_line +=Suffix2Desc(http_request.suffix);
- header_line +=LINE_END;
- http_response.response_header.push_back(header_line);
这个时候我们做一个测试,我们利用本地环回,把index.html的内容改为hello world。
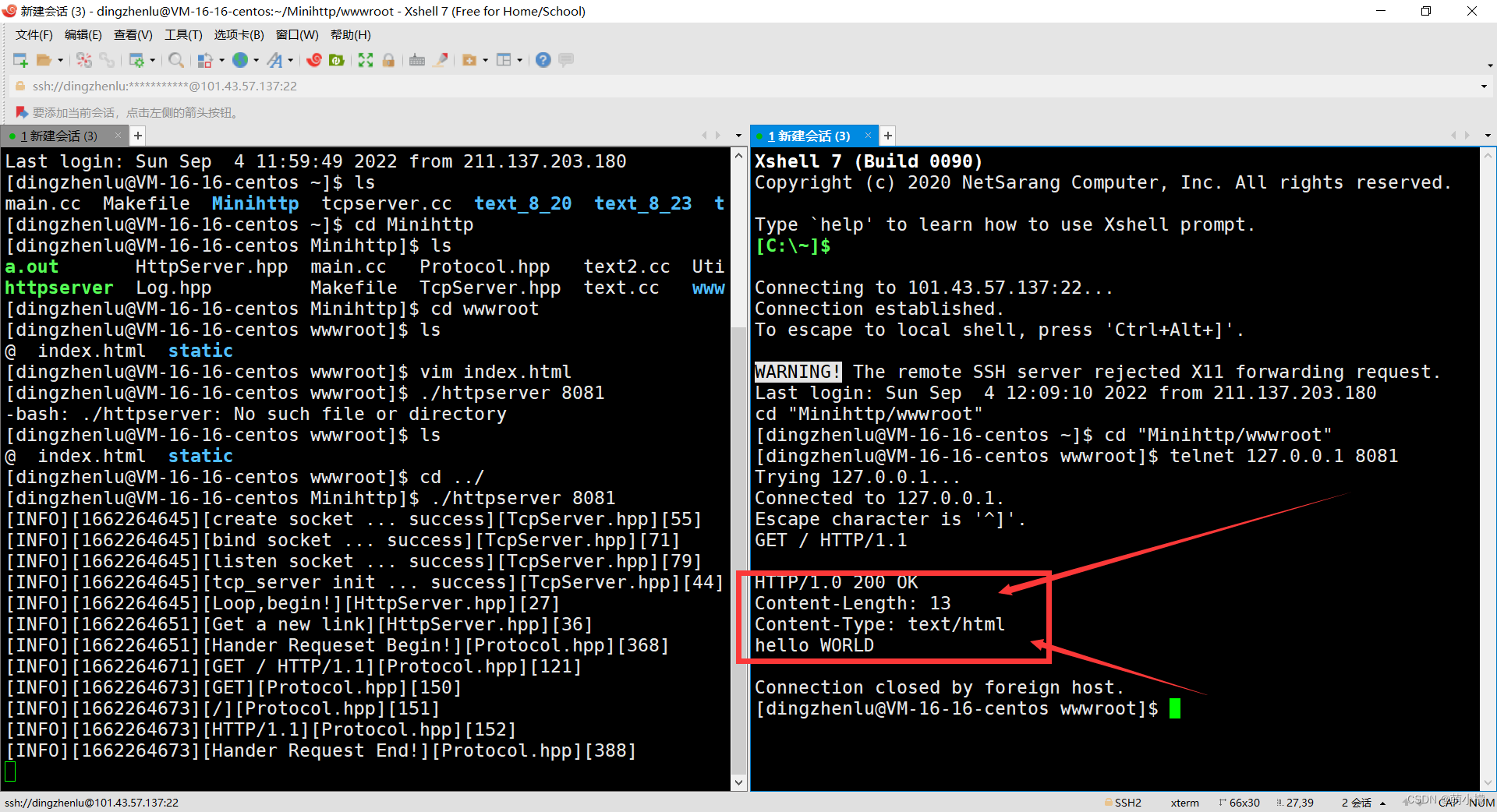
我们就获取到了状态码 状态码描述,以及content-length content-type等信息,以及hello world的正文内容,我们写的静态网页测试就成功了。
-
相关阅读:
Spring 之 Lifecycle 及 SmartLifecycle
KubeSphere 网关的设计与实现(解读)
【云原生 二】 Docker架构演进过程
Towards Class-Oriented Poisoning Attacks Against Neural Networks 论文笔记
查看linux的内存使用情况
Flink CDC 菜鸟教程 -环境篇
cleanmymac2023免费版纯净mac电脑系统管家
快速学会linux中ssh服务的连接
SaaSBase:Automation Anywhere是什么?
一文带你了解J.U.C的FutureTask、Fork/Join框架和BlockingQueue
- 原文地址:https://blog.csdn.net/m0_61703823/article/details/126678808
